DAST and black-box approaches are methods used to test the security of an application by analyzing its behavior in response to inputs without having knowledge of the application’s internal structure or the code being executed. These approaches rely on generating inputs through methods such as brute force and
DAST and black-box approaches are methods used to test the security of an application by analyzing its behavior in response to inputs without having knowledge of the application’s internal structure or the code being executed. These approaches rely on generating inputs through methods such as brute force and randomness, in the hopes of discovering vulnerabilities which comes with several limitations:
Lack of knowledge of the code being executed means that certain vulnerabilities may not be discovered, as they only appear when a certain path is traversed. This can lead to limited code coverage and a higher likelihood of missing vulnerabilities.
Brute force and random input generation can lead to many inputs being tested that do not contribute to discovering new vulnerabilities. This can be time-consuming and inefficient.
Pre-reading Requirements
While the article is somewhat lengthy, it is not overly technical. It is assumed that readers possess at least a foundational understanding of software engineering.
Summary:
Traditional Dynamic Application Security Testing (DAST) and black-box methods launch payloads against an application to trigger behaviors that may expose bugs or security vulnerabilities, such as a stack overflow. However, this approach is often inefficient and time-consuming. Feedback-Based Application Security Testing (FAST), on the other hand, utilizes feedback from the application (without altering the source code) to glean insights about the effects of payloads, like code coverage. This information is then used to generate new payloads more likely to uncover vulnerabilities or bugs.
Jazzer is a coverage-guided fuzzer designed for integration with JVM applications, such as those using Spring Boot. It employs LibFuzzer and Java instrumentation to adapt LibFuzzer for use with JVM-based applications. Jazzer also instruments application classes within the classpath, enabling the detection of potential vulnerabilities, including SQL Injection.
FAST is not meant to replace other application security testing tools like SAST or DAST but is intended to complement your security testing toolkit.
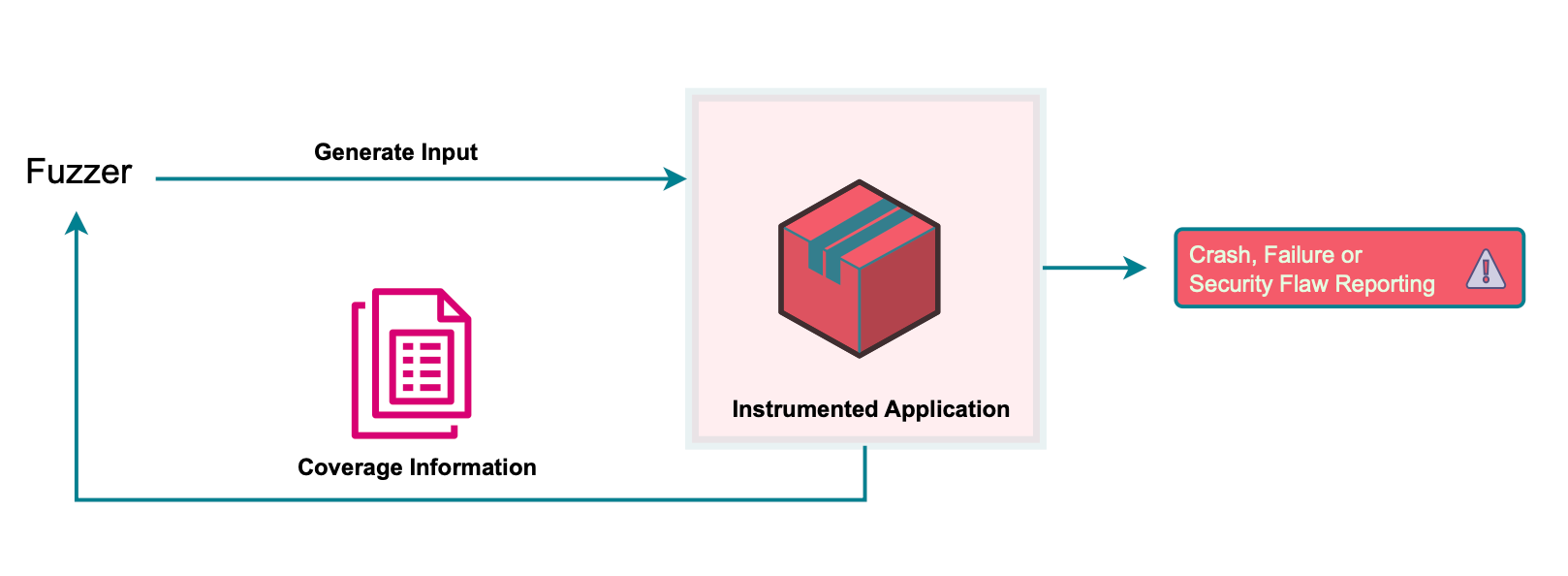
FAST (in short for Feedback-based Application Security Testing) is an approach that addresses these limitations by using feedback from the application to generate test cases. This approach involves playing an input and receiving feedback from the application. This feedback is then used to generate new test cases that maximize objectives such as code coverage, which helps to minimize being stuck in one particular region of the application space leading to the discovery of interesting paths, hoping that a position will point out a bug, crash, or vulnerability.
The feedback-based approach allows fuzzers to focus on areas of the input space that are more likely to reveal vulnerabilities, leading to more efficient testing and a higher likelihood of discovering vulnerabilities. Additionally, FAST can be integrated into the development process, making it easier to identify and fix vulnerabilities early on in the development lifecycle.
Fuzzing Testing
Fuzzing testing is a powerful technique used to discover glitches and security weaknesses in software. In essence, it involves a methodical exploration of the various possible inputs a program can receive, with the goal of identifying inputs that can make the program malfunction or become unresponsive. This exploration does not have to be entirely random; it can be influenced by a specific goal, like achieving comprehensive code coverage.
There are two types of fuzzing techniques. The first type is mutation-based fuzzing, which involves randomly changing parts of the input data. The second type is generation-based fuzzing, which involves creating entirely new, valid input data. Both approaches can be used to identify bugs and vulnerabilities in software.
In modern fuzzing techniques, the program being tested is instrumented to give the fuzzer feedback about the code covered. The mutation engine uses this feedback as a measure of input quality which helps the fuzzer to focus on areas of the code that are not yet tested, and to avoid redundant tests. At the core of the mutation engine are genetic algorithms that use code coverage as a fitness function.
Fuzzers work by first randomly generating inputs for a program, and then analyzing the program’s behavior in response to those inputs. The inputs generated by fuzzers can be in the form of file inputs, network inputs, or command-line arguments, among others. The fuzzer then records any crashes or unexpected behavior that the program exhibits in response to the inputs, and uses this information to generate new inputs that are more likely to reveal bugs.
In spite of their seemingly naive appearance, fuzzers are surprisingly effective at finding hidden bugs in programs. They can discover bugs that would have otherwise been difficult to find through manual testing or other methods. This is because fuzzers are able to explore a much larger portion of the input space than a human tester would be able to, which increases the chances of uncovering bugs. As an example, a Denial of Service vulnerability (CVE-2023-20861) has recently been discovered in the Spring Framework by Jazzer, a coverage-guided, in-process fuzzer for the JVM (https://www.code-intelligence.com/blog/expression-dos-spring).
Fuzzing entails the creation of a fuzz driver, essentially a specialized testing tool crafted to interact with software library code by supplying inputs to the target program. This serves to enhance the versatility of the testing engine. The fuzz driver acts as an intermediary, linking the fuzzer with the target program, transmitting inputs generated by the fuzzer into the target program. By doing so, the fuzz driver plays a crucial role in guaranteeing that the fuzzer can provide valid inputs to the target program and that the target program can properly process and understand these inputs.
Coverage-guided greybox fuzzing is a method of fuzz testing that utilizes a feedback loop to incrementally generate inputs. This method has three main stages:
The first stage is to generate a set of test inputs and execute the target program with them. This initial set of inputs can be generated randomly or using some other methods.
The second stage is to collect code coverage data from the program execution. Code coverage is a measure of how much of the program’s code has been executed during testing. This data can be used to identify parts of the program that were not traversed during the initial test inputs.
The third stage is to use this code coverage data to guide the generation of new inputs that will exercise these uncovered areas. This loop is repeated until all parts of the program have been exercised or a timeout has been reached.
In greybox fuzzing, instrumentation is usually inserted at compile-time, and then random mutations are generated and tested over the course of the fuzzing campaign. Mutated input that traverses new instrumented locations are retained and prioritized for further mutation. As a result, we are able to cover more paths, allowing us to detect bugs or other application issues.
This post is for subscribers only
Sign up now to read the post and get access to the full library of posts for subscribers only.