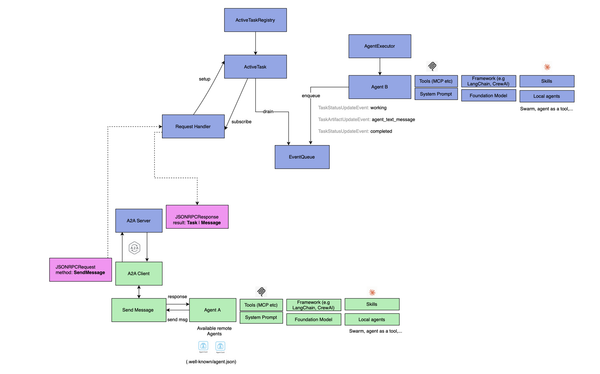
The goal of this post is to provide an in-depth look at standardizing how heterogeneous agents discover, authenticate, and communicate with one another by examining the Google's Agent-to-Agent (A2A) protocol [1] (covering both theory, practical deployment and security). The post will present the foundations of

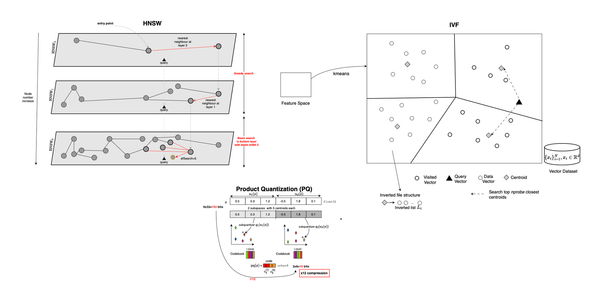
The goal of this post is to explain how vector similarity search works internally. Why is this interesting? Because Retrieval-Augmented Generation or RAG is typically implemented using vector search over text embeddings. Embeddings are basically a bottleneck that compresses the semantics of a paragraph or chunk into a continuous
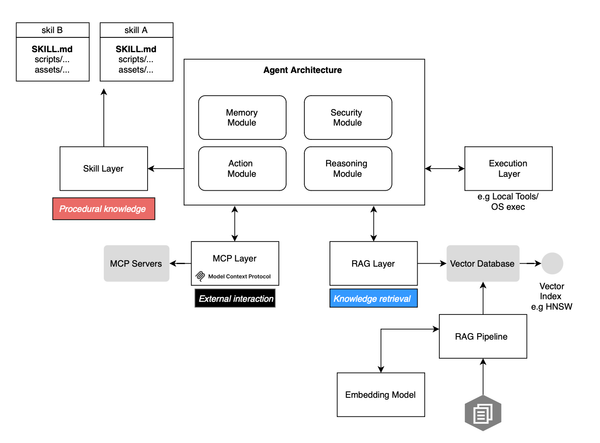
This post summarizes the main implementation patterns used by modern multi-agent frameworks including agents-as-tools, handoffs, routing, reflection, group chat, debate, Magentic-style ledger orchestration, dynamic subagent spawning, and mixture-of-agents architectures. The Brain: Foundation Models Well, the first thing we need to build an agent is
Introduction A straightforward approach to augment large language models or LLMs with new capabilities is through in-context learning. The model is provided with a small number of examples that demonstrate how to solve a task, after which it generates a response using its inherent capabilities combined with the knowledge
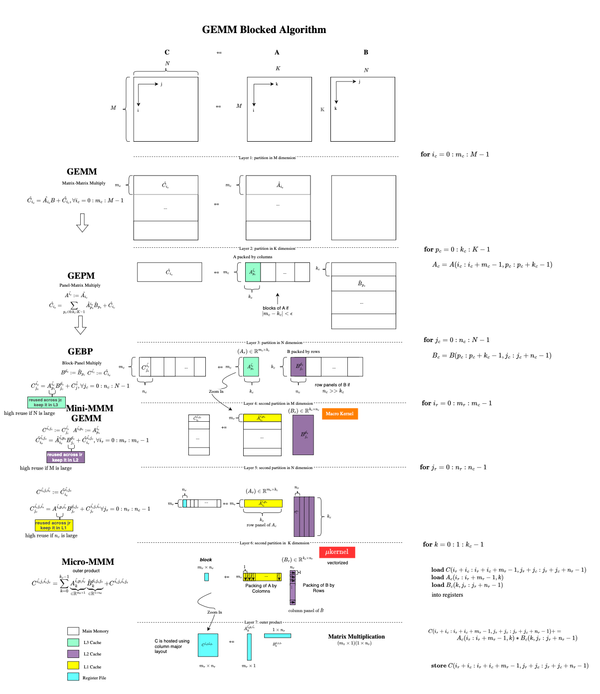
Implementing highly efficient matrix multiplication routines that approach peak performance demands significant effort, strong linear algebra knowledge, and a deep understanding of the underlying hardware architecture (even down to the microarchitectural level[23]). This is why vendors provide highly optimized implementations of the Basic Linear Algebra Subprograms (BLAS)[1], including

This post is devoted to the study of the mechanisms employed by python ( CPython (3.14) ) to prevent memory-safety violations, including spatial defects such as buffer overflows and temporal errors like use-after and double-free. Additionally, we also cover why python integers can never overflow; this is basically
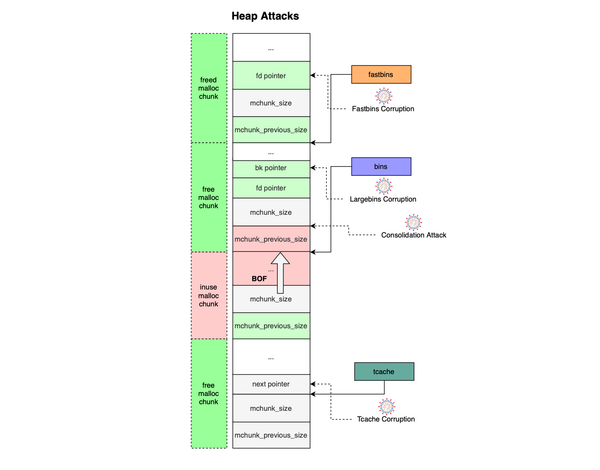
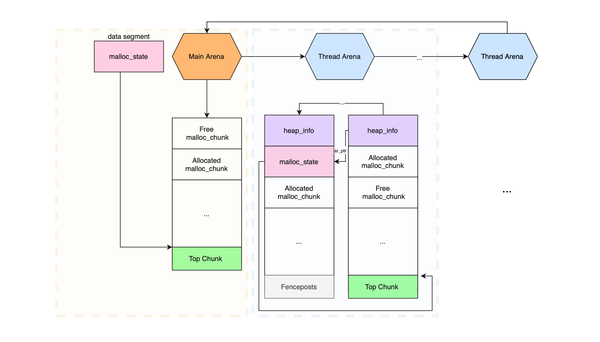
In my previous post, I provided an extensive analysis of the memory allocator used by the GNU C library. In this post, I’ll show how weaknesses in the glibc heap allocator design can be abused to turn memory errors like buffer overflows (spatial defects) or use-after-free bugs
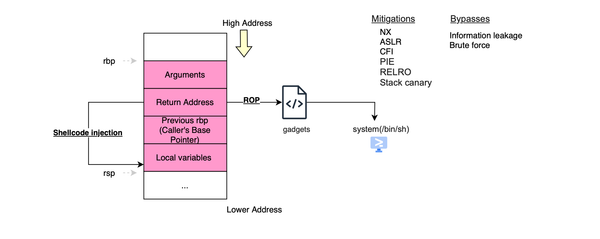
This post discusses memory defects at the stack level, covering different stack exploitation techniques and how they are mitigated in modern environments. If you are interested in heap exploitation, see my other post, which introduces heap-based attacks and explains how memory allocators can be abused to achieve successful heap
Memory defects such as buffer overflows, double frees, and use-after-free remain a leading cause of security vulnerabilities in low-level programming languages like C and C++. Contemporary heap exploits differ significantly from stack-based attacks. Exploiting heap defects requires more than just triggering a bug, it demands a