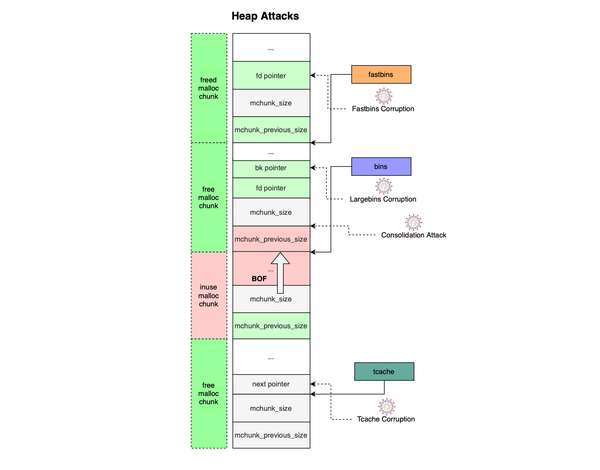
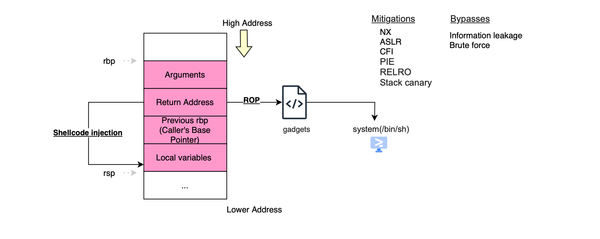
Memory defects such as buffer overflows, double frees, and use-after-free remain a leading cause of security vulnerabilities in low-level programming languages like C and C++. Contemporary heap exploits differ significantly from stack-based attacks. Exploiting heap defects requires more than just triggering a bug, it demands a deep understanding of the

Memory defects such as buffer overflows, double frees, and use-after-free remain a leading cause of security vulnerabilities in low-level programming languages like C and C++. Contemporary heap exploits differ significantly from stack-based attacks. Exploiting heap defects requires more than just triggering a bug, it demands a deep understanding of the underlying memory allocator.
Over the years, several memory allocators have been proposed, each making different trade-offs between performance and resistance to attacks. This post concentrates on the analysis of glibc 2.42’s default memory allocator, ptmalloc, covering key structs used in the glibc's heap implementation, binning logic, allocation and deallocation paths, integrity checks, bitmap scanning, pointer mangling, and the low-level tricks employed by the allocator.
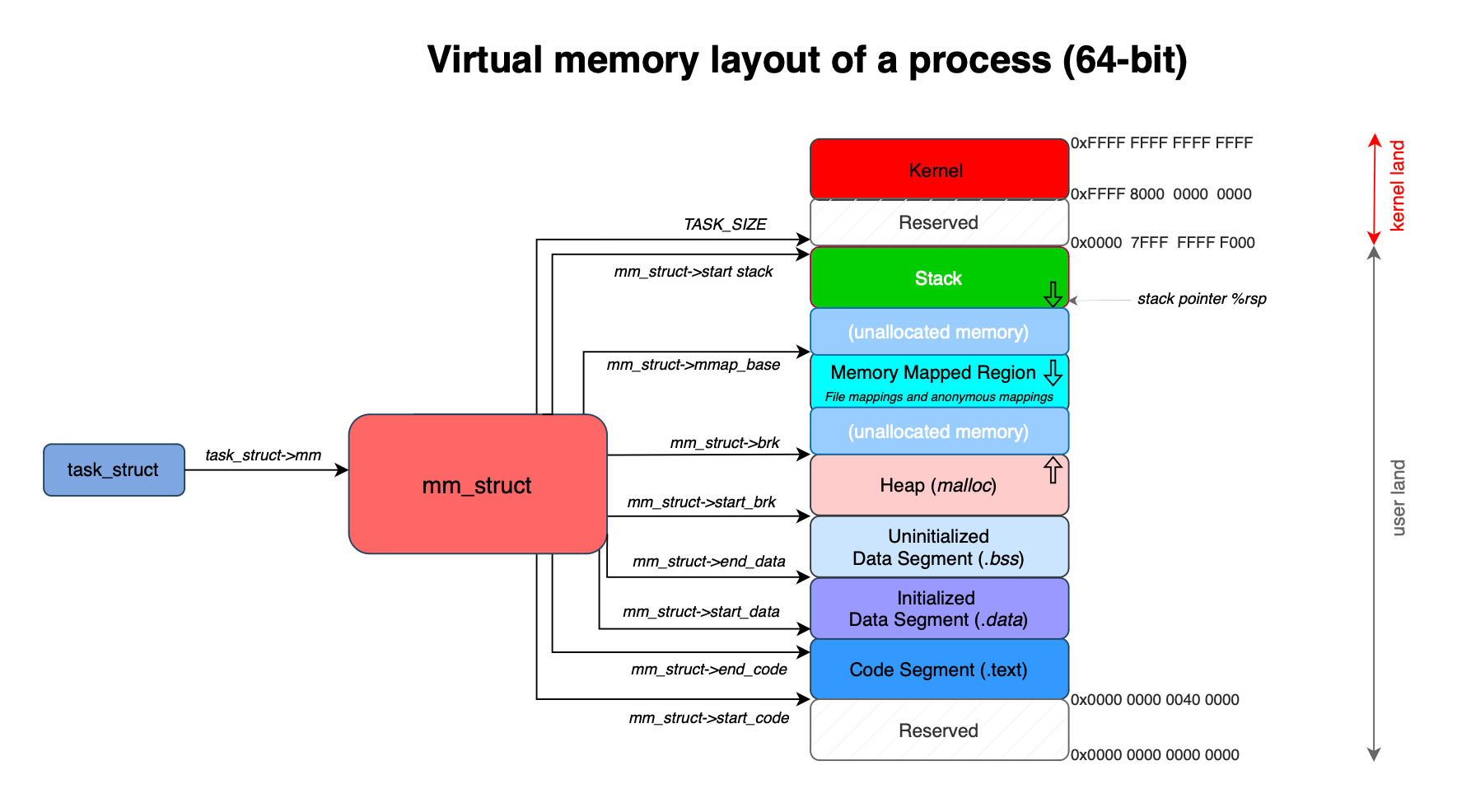
Memory is divided into several segments, including the stack, heap, global, and code segments. The heap represents a portion of virtual memory accessible by programs to request memory dynamically at runtime. Programs typically rely on existing allocators like ptmalloc to request memory (e.g. malloc() or new), delegating the complexity of handling alignment, fragmentation, and performance to the allocator.
Heap corruption occurs when dynamic memory allocation is not managed correctly. These subtle bugs can lead to costly, serious and exploitable vulnerabilities such as privilege escalation, arbitrary code execution, and complete system takeover. Most memory corruptions occur on the heap, which for decades has represented a major source of software defects in programs written in low-level languages like C and C++.
Protecting the heap against attacks is a well-researched problem. The implementation and deployment of defense mechanisms such as ASLR (which randomizes process memory layout, especially effective on 64-bit systems), Non-Executable (NX), and other techniques have significantly raised the bar for attackers. Yet sophisticated, dedicated, and patient adversaries still find ways to bypass most existing defenses.
Heap-based exploits leverage memory safety violations, either spatial (out-of-bounds access) or temporal (accessing freed or invalid memory) such as buffer overflows, double frees, or use-after-free bugs, leading to information disclosure attack, privilege escalation, or arbitrary code execution.
While the primary goal of a memory allocator is to serve chunks dynamically at runtime, not all allocators are designed equally. Some are hardened by design, for example, by segregating heap metadata and preventing predictable heap layouts, whereas others trade security for performance e.g by placing metadata directly adjacent to heap chunks; introducing security risks that are often mitigated through integrity checks.
Heap vulnerabilities differs significantly from stack based memory defects. Stack based vulnerabilities are easier to understand and exploit (though modern mitigations make exploiting them far more difficult today), heap exploitation requires a much deeper understanding of the underlying memory allocator.
Recently, I decided to go low-level and study how heap exploitation techniques are actually developed. I discovered that many of these techniques abuse and corrupt allocator metadata, meaning they are allocator-specific. This makes the heap a prime target for attackers, provided an application vulnerability exists in the first place.
After spending several days studying the internals of glibc’s malloc implementation, I decided to write a post about how the allocator really works under the hood, knowledge that can help anyone interested in learning the foundations of low-level exploitation and memory forensics.
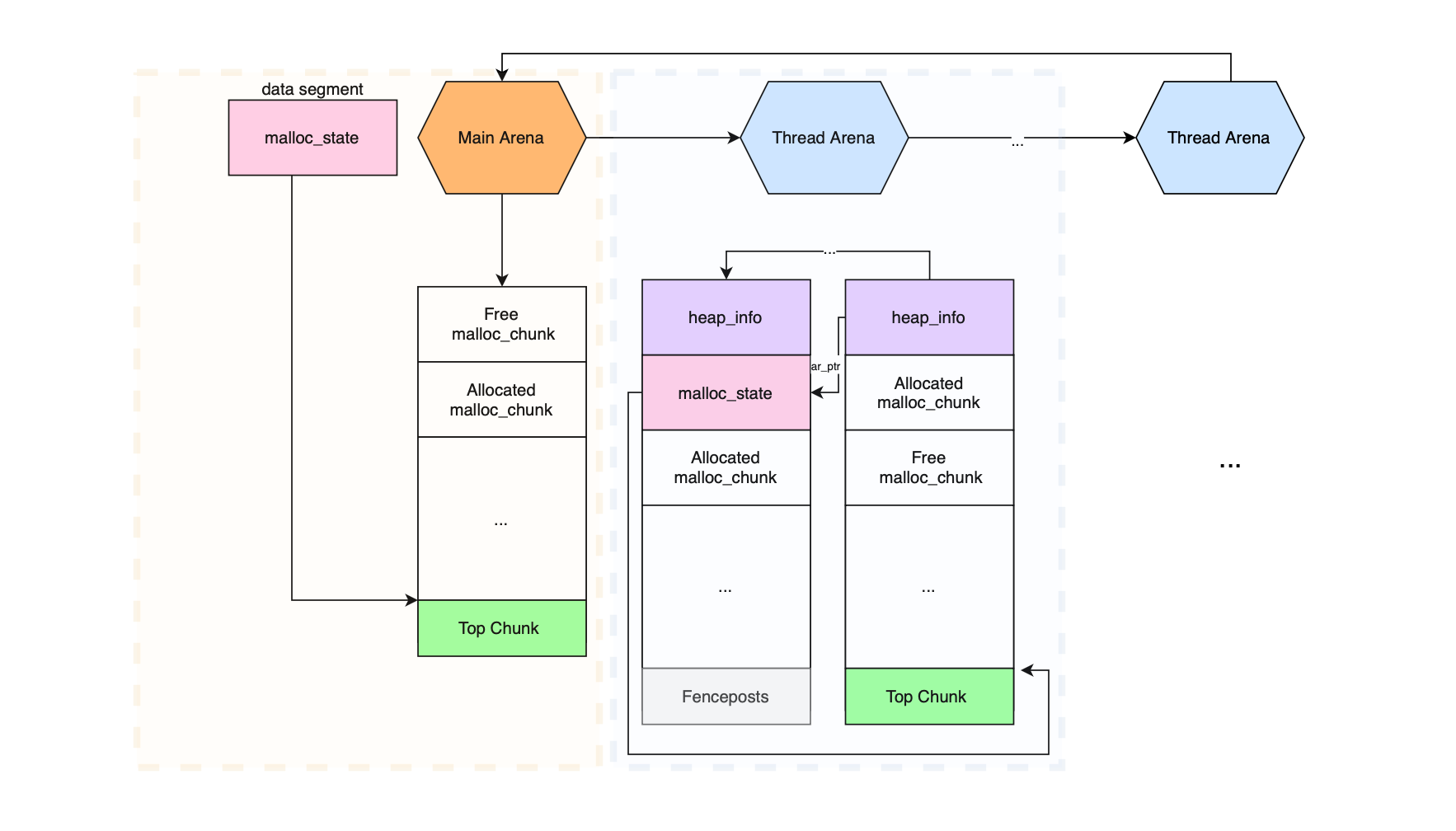
As we will cover in this post, virtual memory is organized into chunks, where each chunk belongs to a heap space (or arena). This could be the traditional process heap, in which case the chunk belongs to the main arena, or a memory-mapped region represented by a vm_area_struct, in which case the chunk belongs to a thread arena.
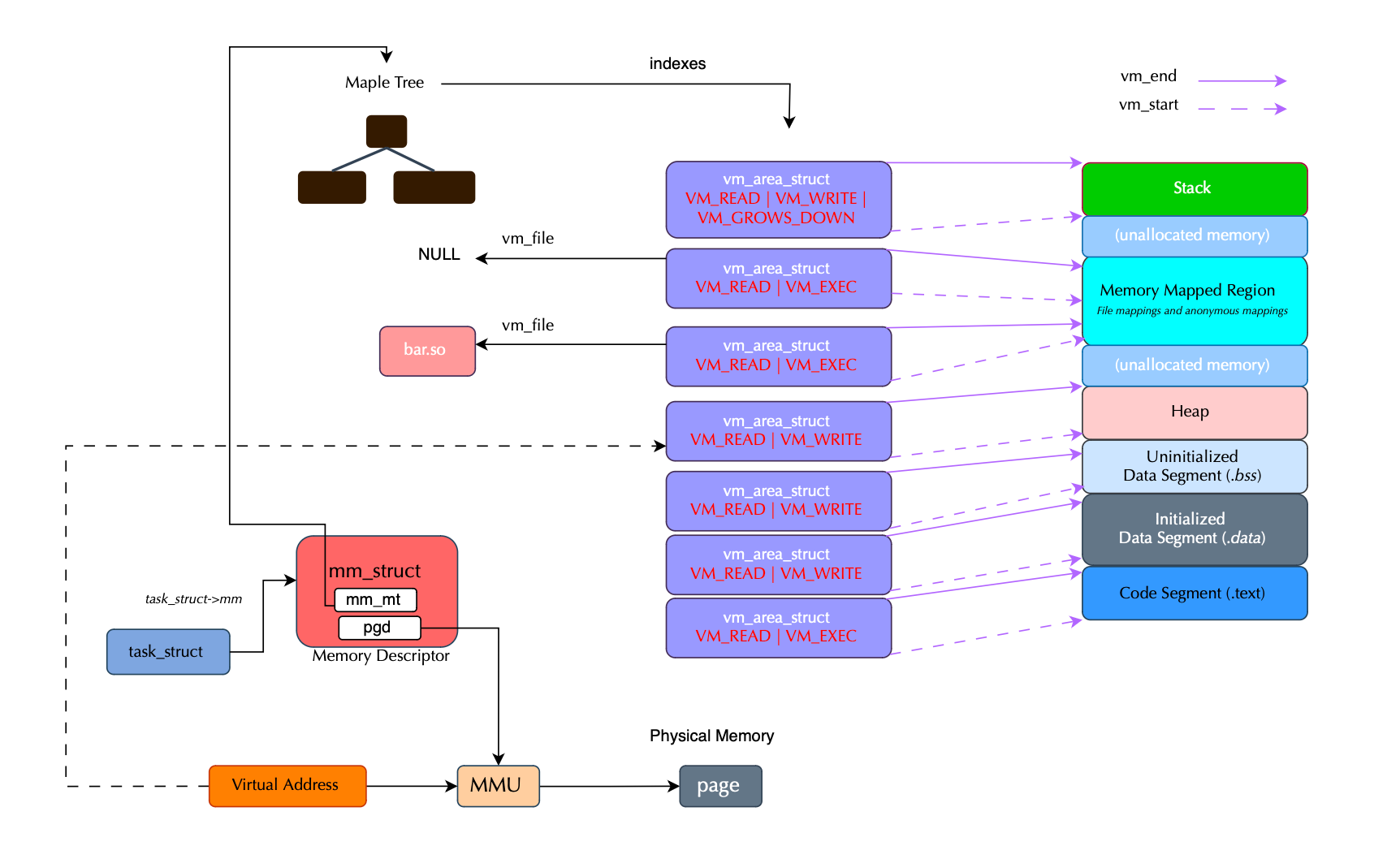
When a thread is assigned to an arena other than the main one, its mapped memory region is represented by a heap_infostructure. This is needed because mmap does not guarantee contiguous memory; when discontinuities occur, heap_infoallows traversal of the heap space managed by an arena.
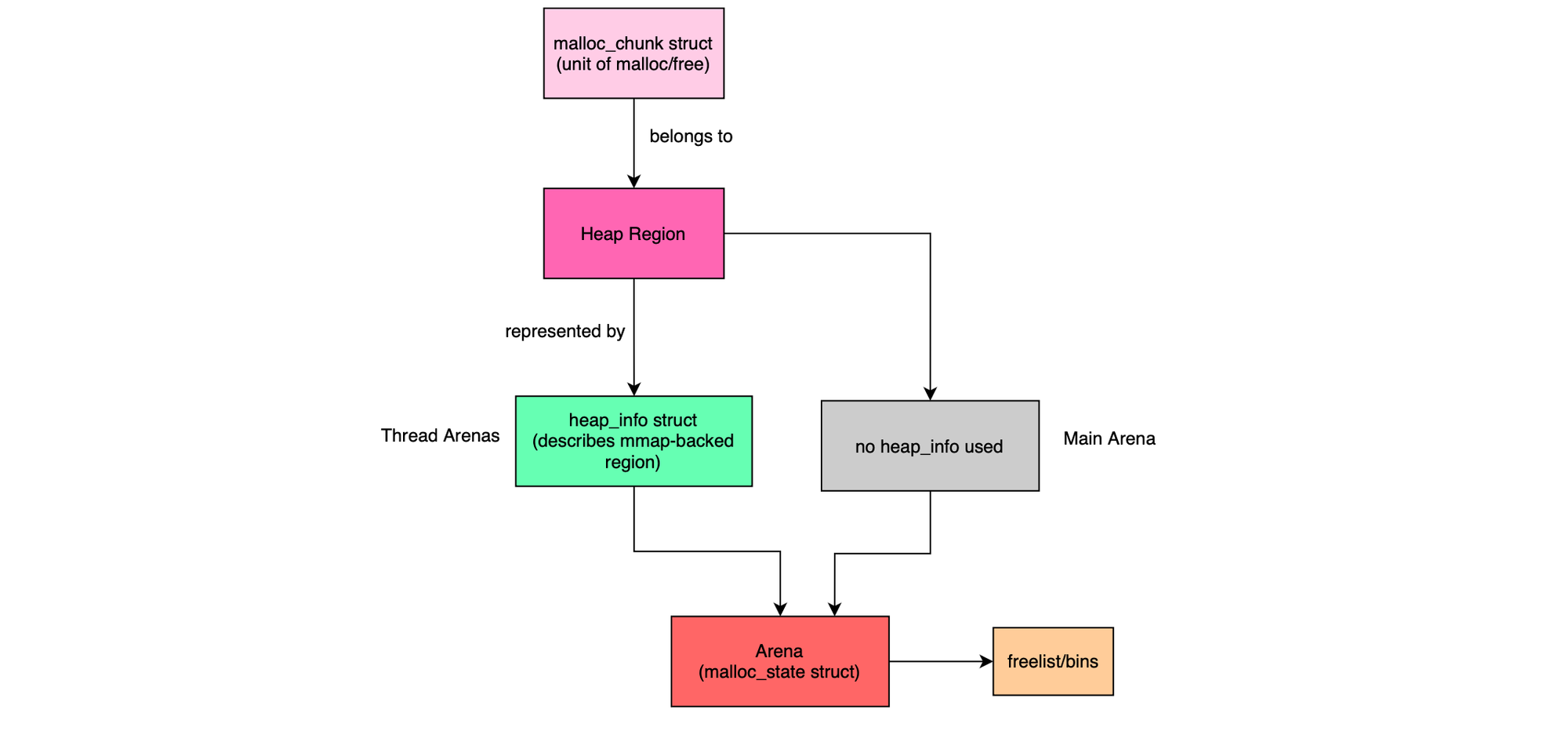
An arena represents a heap space, storing memory blocks or chunks and belonging to one or more threads. Since malloc limits the number of arenas that can be created, some arenas may eventually be shared across threads. One or more heap_info structures (chained together) belong to a single arena. Thus, a chunk belongs to a heap region represented by a heap_info (except in the main arena), which in turn belongs to an arena represented by a malloc_state struct. During execution, heap_info instances may go away when memory is deallocated and new ones may join during allocation.
There is always a main arena, which uses the standard contiguous process heap region. Because it is contiguous, no heap_info structures are required for the main arena (although over time it can become non-contiguous).
In contrast, to better support multi-threaded applications and reduce synchronization tax, thread-specific arenas were introduced. These arenas consist of multiple heaps (memory-mapped regions) and are attached to different threads. Each thread arena is composed of chained heap_info structures, allocated via mmap().
Finally, when chunks are very large, they are allocated directly via mmap(). Unlike vanilla heap chunks, mmaped chunks are not subject to binning; a bin is a container where freed chunks are linked together.
In this section, internal data structures and concepts of ptmalloc are introduced.

Memory managed by ptmalloc is divided into blocks or chunks, generally housed inside an arena consisting of one or several chained heaps (except the main arena). Each piece of memory or chunk allocated and returned to user code is prefixed with a header, a structure called malloc_chunk. Its definition is shown below:
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};Chunks sits next to each other in the heap, mchunk_prev_size is the size of the previous chunk, valid only if that chunk is free (otherwise it may house user data). The mchunk_size is the user size of this chunk, including the memory overhead (i.e 16 bytes or 2*INTERNAL_SIZE_T ). Because a chunk is always aligned to MALLOC_ALIGNEMENT =16 bytes by default, mchunk_size stores flags in its least significant bits, which helps during malloc deallocation and consolidation.
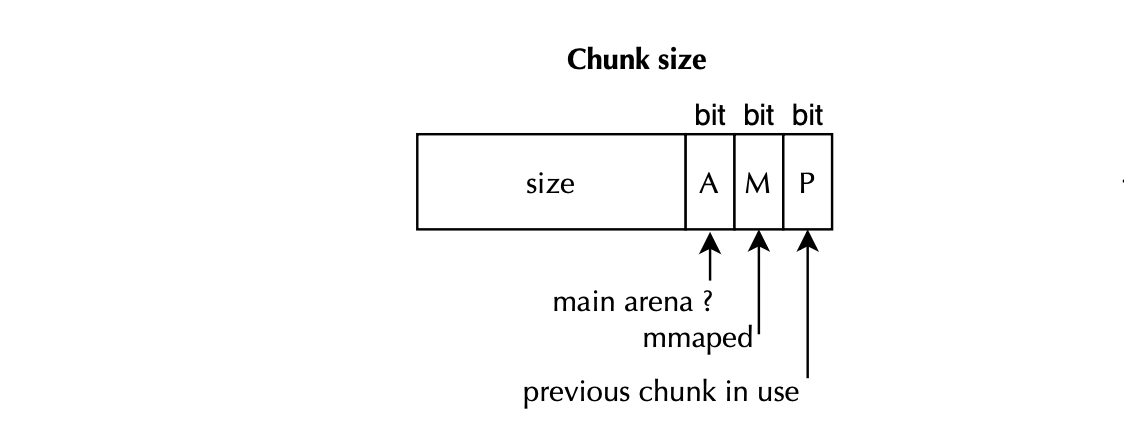
P(PREV_INUSE) is stored at lowest order bit and indicates if the previous chunk is free facilitating the malloc consolidation of free chunks as would be covered in more details later. The second lowest order bit, M(IS_MMAPPED), indicates if the chunk was allocated using mmap which would require a different deallocation path e.g munmap as mmaped chunks are not subject for bin indexing. Finally A(NON_MAIN_ARENA) bit if set indicates that the chunk belongs to a thread arena (more on that later).
Let's look at other fields. fd and bk are forward and backward pointers used to link/unlink free chunks in double linked lists (used for binning). The two pointers are stored in the chunk's user accessible memory only if the chunk is free (i.e if the user chunk is allocated then user data would sit at the corresponding memory location).
In order to simplify the implementation of the doubly linked list, the allocator uses a sentinel node, a dummy node placed at the front of each doubly linked list (associated with a bin index or size range); the bin node points to the head and tail nodes of the list. The sentinel node does not contain any data; it consists only of a forward pointer fd and a backward pointer bk, requiring two pointers for each bin (minus one, since bin 0 does not exist), i.e.,2 × (NBINS – 1).
The forward and backward pointers reference the largest and smallest malloc chunks indexed in the bin (index traversal by size is only relevant for large bin indexes). If the header or sentinel node points to itself, then the doubly linked list is empty.
To speed up traversal of bin indexes when several chunks of the same size are adjacent (and would otherwise require few steps), the allocator introduces another type of doubly linked list, represented by fd_nextsize and bk_nextsize. fd_nextsize and bk_nextsize allow skipping over chunks of identical size, as they point directly to the next smaller/larger chunk available. This is illustrated below.
When memory is allocated, the allocator move past the header of size CHUNK_HDR_SZ and return the obtained memory address to the user:
#define chunk2mem(p) ((void*)((char*)(p) + CHUNK_HDR_SZ))When memory is freed, the allocator retrieves the chunk's header as follows :
#define mem2chunk(mem) ((mchunkptr)((char*)(mem) - CHUNK_HDR_SZ))
As we will cover later, the following macros are extensively used during memory allocation and deallocation.
While reading the source code of malloc or posts discussing its internals, you may come across something confusing (e.g https://stackoverflow.com/questions/49343113/understand-a-macro-to-convert-user-requested-size-to-a-malloc-usable-size). The memory overhead used to store chunk metadata on 64-bit system is by default 16 bytes, or 2 words (mchunk_prev_size and mchunk_size). However, when you look at the macro used to map the request size to include the overhead:
#define request2size(req) \
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
MINSIZE : \
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
You get confused. Why does it only add SIZE_SZ (8 bytes in 64-bit systems) and not 2 * SIZE_SZ? This is because in worst case scenario, the SIZE_SZ previous size is borrowed from next chunk as anyway it would not be used until the previous chunk is free; thus the allocator only needs to guarantee size for SIZE_SZ.
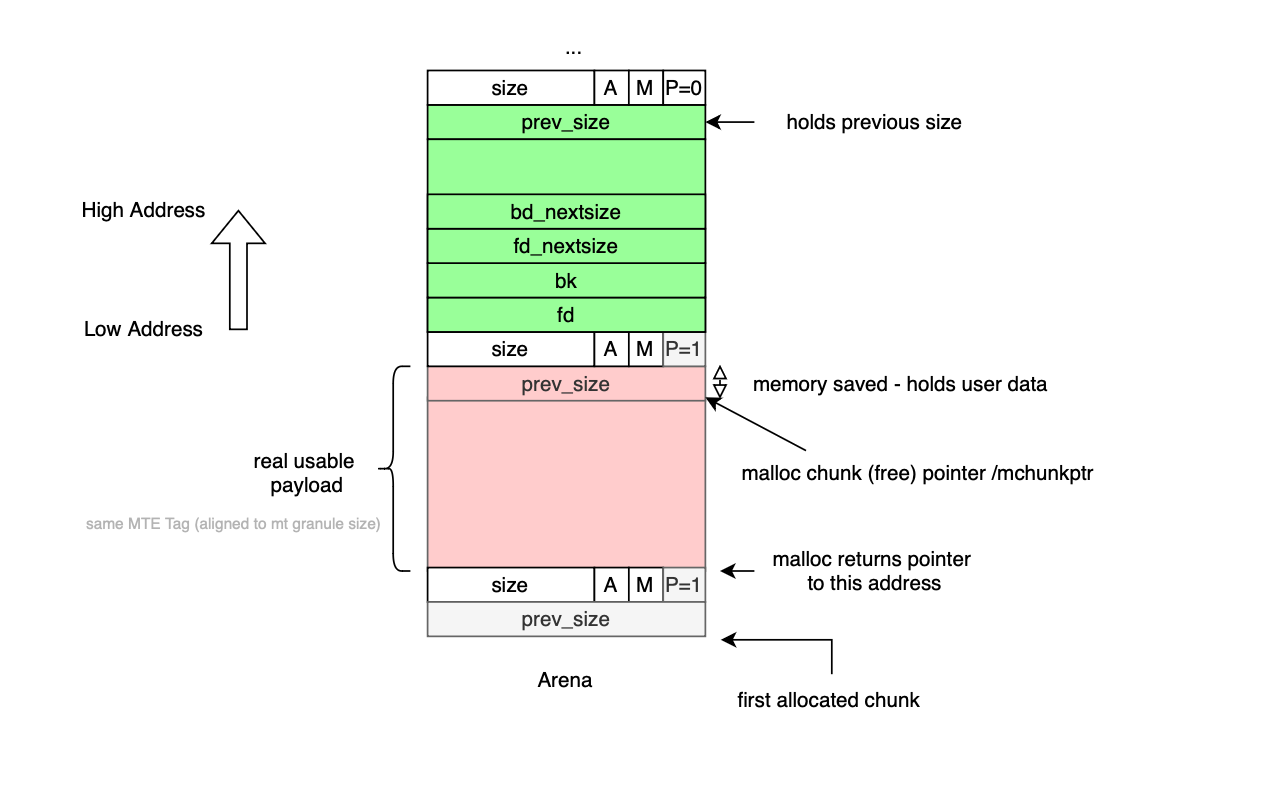
The footer of the current chunk, that is, the prev_size field, is stored as part of the next chunk's header and is never used when previous chunk is in use so why not use it when possible and use the 8 bytes of prev_size to complete the user memory if needed.
Let's look at the macro memsize(p), which returns the real usable data (very important when Memory Tagging or MT is enabled).
/* This is the size of the real usable data in the chunk. Not valid for
dumped heap chunks. */
#define memsize(p) \
(__MTAG_GRANULE_SIZE > SIZE_SZ && __glibc_unlikely(mtag_enabled) ? \
chunksize(p) - CHUNK_HDR_SZ : \
chunksize(p) - CHUNK_HDR_SZ + (chunk_is_mmapped(p) ? 0 : SIZE_SZ))
Let's first consider the case where memory tagging is not enabled. If the chunk is served by mmap then the usable size is chunksize(p) - CHUNK_HDR_SZ as in this case binning is not used. On the other hand, if the chunk is subject to binning, then the real usable size is chunksize(p) - CHUNK_HDR_SZ + SIZE_SZ as SIZE_SZ can be borrowed in this case.
Now, if memory tagging is enabled and the granule size is larger than SIZE_SZ, it is not safe to return chunksize(p) - CHUNK_HDR_SZ + SIZE_SZ. Instead, the real usable memory is just chunksize(p) - CHUNK_HDR_SZ. This is because when __MTAG_GRANULE_SIZE > SIZE_SZ, the size and prev_size fields would not be in different granules (note that the initial size is always aligned to the granule size before calling the request2size macro and __MTAG_GRANULE_SIZE is multiple of SIZE_SZ , so the user will never be deprived of usable memory here).
On the other hand, if __MTAG_GRANULE_SIZE < SIZE_SZ, it is safe to return chunksize(p) - CHUNK_HDR_SZ + SIZE_SZ. The reason is that if __MTAG_GRANULE_SIZE < SIZE_SZ, then SIZE_SZ is necessarily a multiple of __MTAG_GRANULE_SIZE (since both are power of 2 and recall that \( 2^{x+n} =2^{x} \times 2^{n} \). Sooo we are good.
Memory allocation in glibc is organized using arenas; regions of memory that manage chunks. There are two types of arenas: main and thread specific arenas.
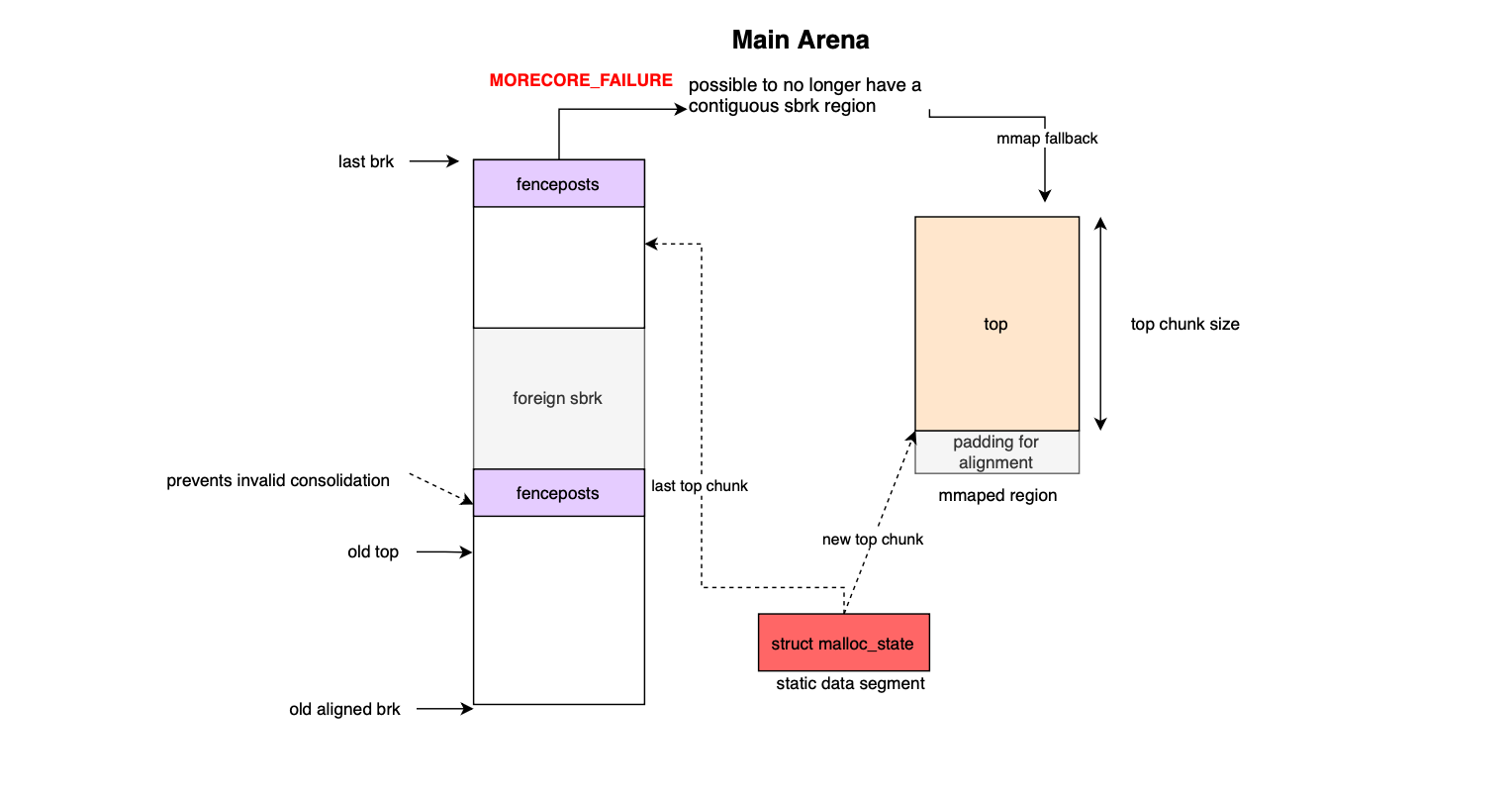
Main arena uses the traditional heap via sbrk() to grow memory (it can also use mmap in certain scenarios and thus can become non contiguous; more on that later). Thread specific arenas in contrast use mmap() to allocate space for malloc chunks. Memory or heap regions in thread arenas are chained together as mmap() may return discontinuous heap regions. As we will cover in a future section, when a heap is not used anymore, the backed physical memory or pages would be handed back to the kernel. Thread arenas are limited to 8 x cores in 64-bit systems.
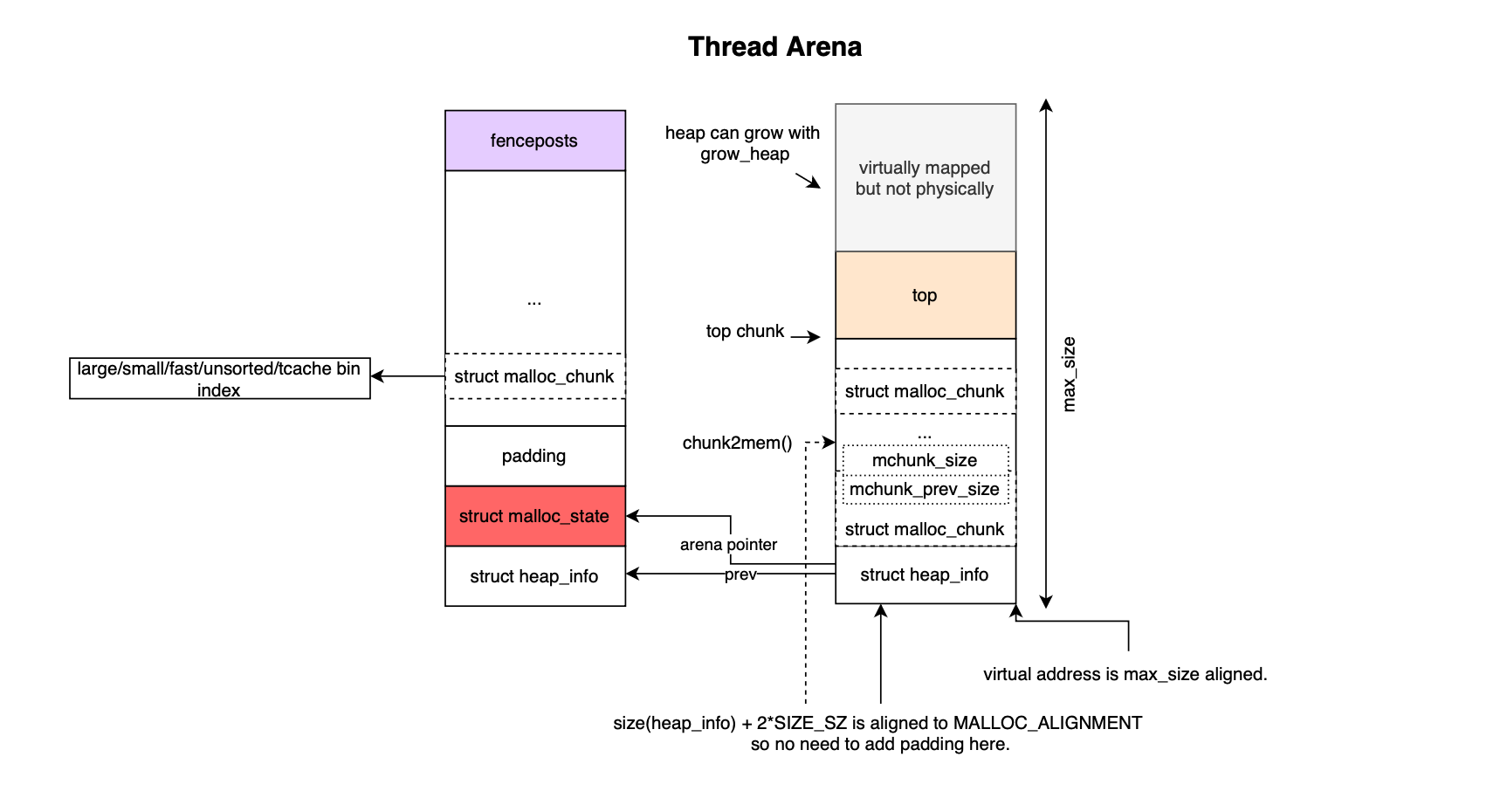
Each arena is described by a malloc_state struct:
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};__libc_lock_define (, mutex) is a synchronization primitive, a mutex, that serializes access to the arena. If one thread holds it, other threads may be suspended until the lock is released by the owner (different from a spinlock). int have_fastchunks indicates whether there are fastbin chunks available; when a chunk is returned to malloc and turns out that the size fits for fast bin index, malloc would set atomically have_fastchunks to make the chunk available to use for next allocations. have_fastchunks is represented using int rather than a bool as atomic booleans are not supported on all targets.
mfastbinptr fastbinsY[NFASTBINS]is the array of fastbin lists (used for small, quick allocations). It uses LIFO semantic and is not coalesced immediately; only during malloc consolidation which is triggered using malloc_consolidate().
mchunkptr top is a pointer to the top chunk; the chunk at the end of the heap that's not in a bin. mchunkptr last_remainder stores the leftover part of a chunk split. mchunkptr bins[ 2*(NBINS -1) ] is a double-linked lists for unsorted, small and large bins where even indices are fd and odd indices are bk.
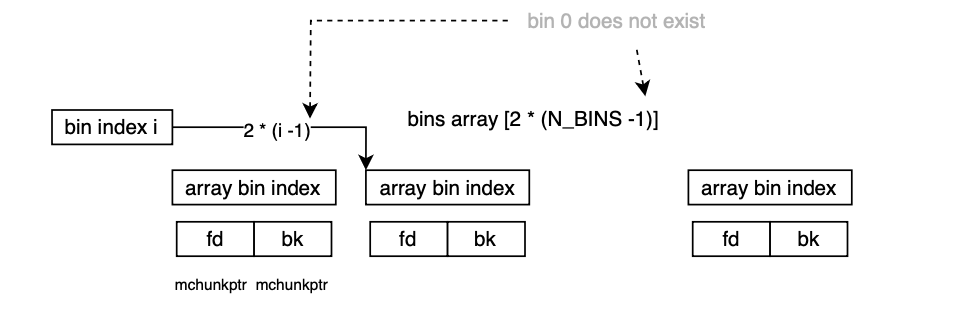
unsigned int binmap[BINMAPSIZE] is a bitmap that flags which bins are non-empty, speeding up lookup (as we will cover later; when a chunk is returned to malloc and size fits in small or large bin index, binmap is updated).
struct malloc_state *next is a pointer to the next arena used to chain multiple arenas. struct malloc_state *next_free points to the next free arena.
INTERNAL_SIZE_T attached_threads houses the number of threads currently attached to this arena (the allocator sets a limit on the number of arenas that can be created so at some points threads may share arenas). If attached_threads= 0, the arena may be reclaimed.
INTERNAL_SIZE_T system_mem is the total memory allocated from the system in this arena via sbrk or mmap (as we will cover later when a heap unused is released or malloc shrinks, top chunk system_mem is updated) and finally INTERNAL_SIZE_T max_system_mem peak memory usage by the arena during its lifetime i.e largest amount of memory observed for that arena.
Free chunk are organized into bins based on size. Each chunk is housed inside exactly one of the bins (unless the chunk is served by mmap()). Additionally when two neighboring chunks are freed, they may be merged into a larger chunk; this is refered to as consolidation; consolidation can also happens between a freed chunk and top chunk. Currently there are 4 types of indexes: fastbin, unsorted, small and large bin). As we will cover later, particularly large chunks are managed with the mmap() system call and are never indexed in bins
Fastbins are introduced for performance and cache locality. Chunks stored in fastbins are always marked as in_use until they are indexed in the unsorted bin.
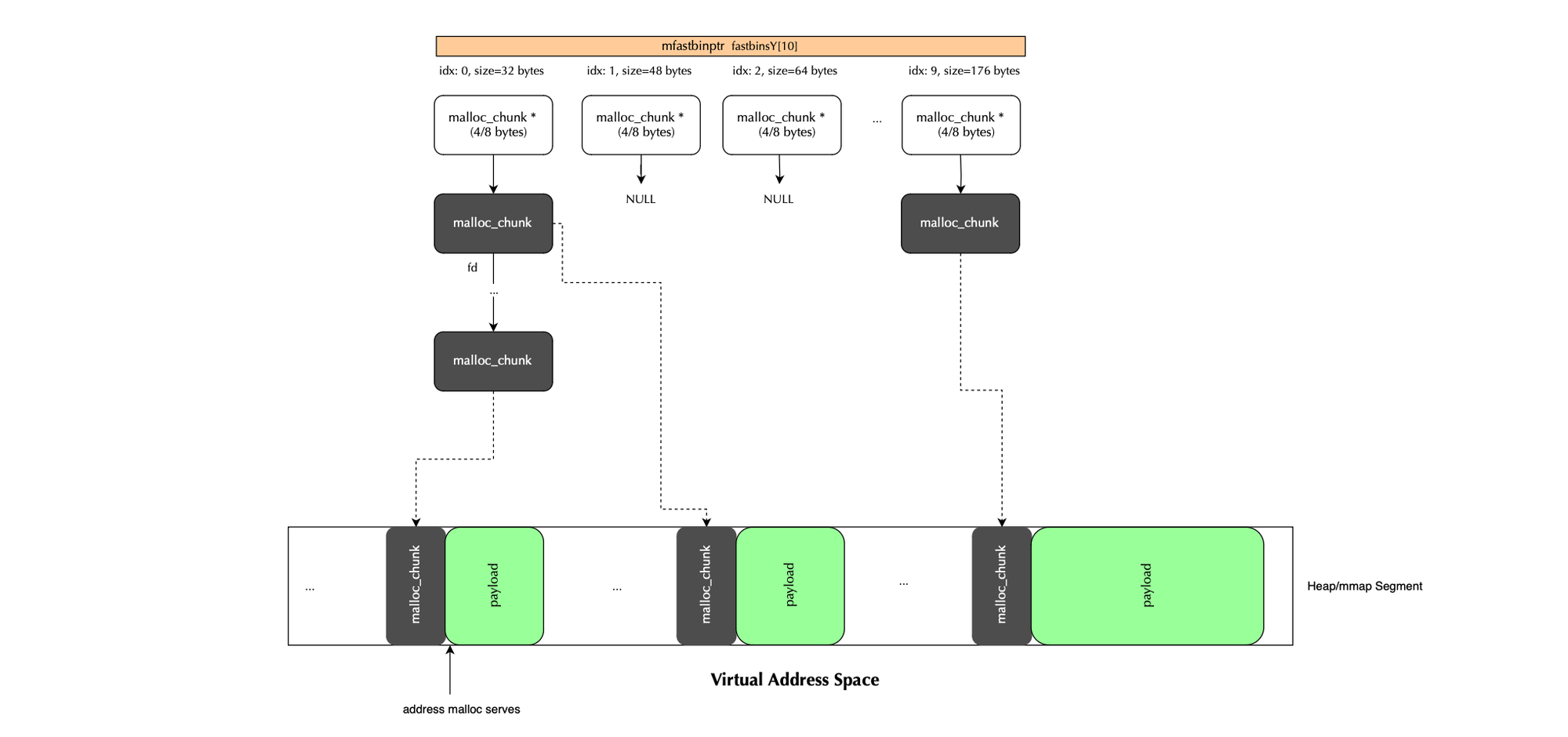
Chunks of size ( including overhead) smaller than MAX_FAST_SIZE:=(80 * SIZE_SZ / 4) bytes (e.g., 32, 40, ..., 160) are all eligible for fast bins which are organized using a linked list stored in the malloc_state data structure representing the arena:
mfastbinptr fastbinsY[NFASTBINS];
All memory allocations (including overhead ) are aligned to MALLOC_ALIGNEMENT (default to 2 * sizeof(size_t) or 2*SIZE_SZ) and each chunk size is at least MIN_SIZE (default 32 bytes).
Each fast bin index maps to a specific chunk size, with sizes increasing in fixed alignment multiples (32, 48,.. 128 bytes,). In other words, the index follows the following formula size = index.MALLOC_ALIGNMENT and thus the index can be obtained by diving the size by the alignment. The index mapping is shown below:
#define fastbin_index(sz) \
((((unsigned int)(sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
The macro subtract 2 because otherwise the resulting indexes 0 and 1 would never be used, as no valid chunk size maps to them (minimum size is 32); the array size can be be computed using the following macro (+ 1 as indexes starts at 0):
#define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)
...
struct malloc_state
{
...
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
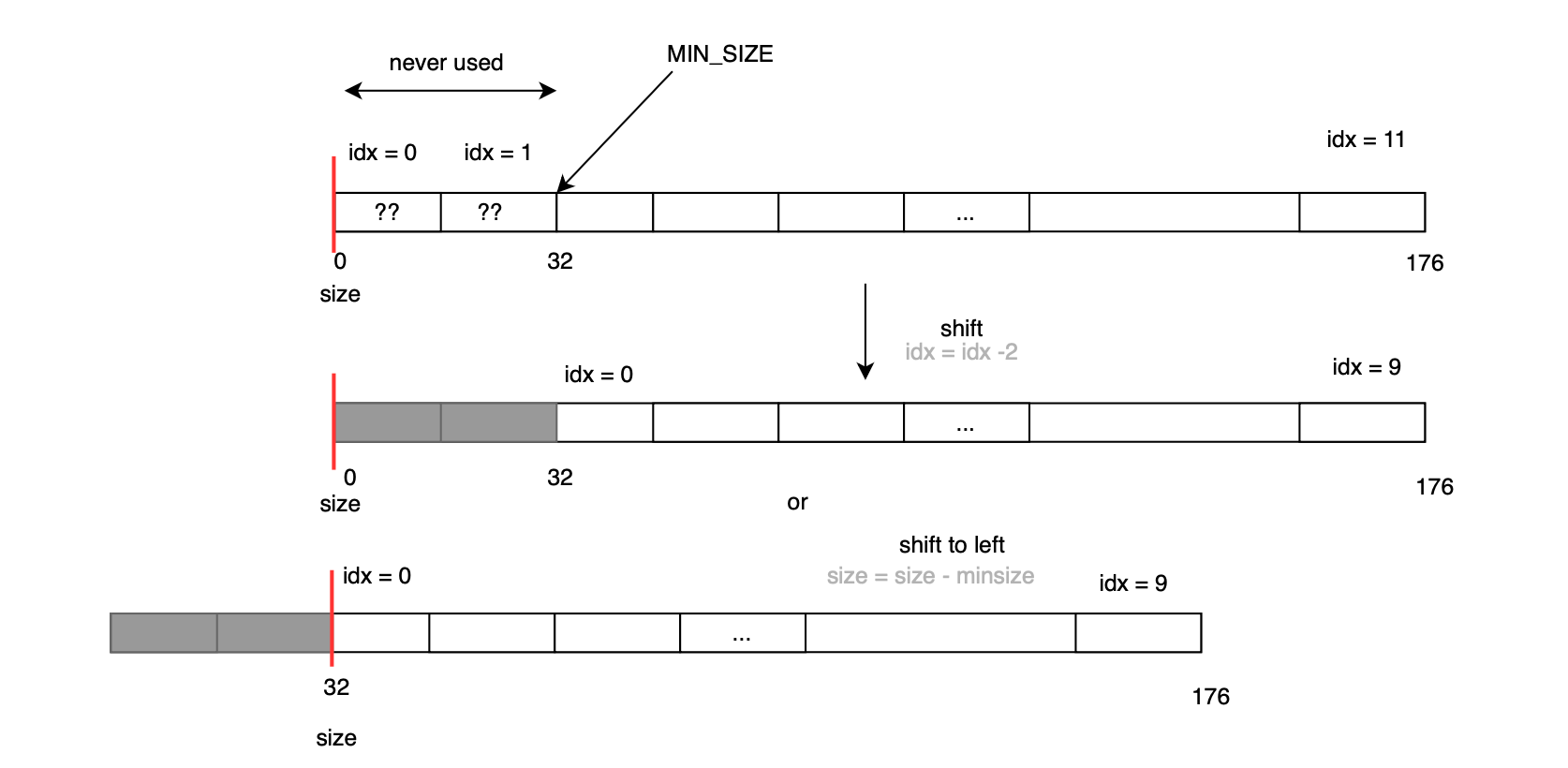
We could have also used the following indexing for fast bins which achieves the same:
index = (size - MIN_SIZE) / MALLOC_ALIGNMENT;The minimum chunk size is defined as follows:
#define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize))On a 64-bit system, the minimum chunk size maps to 32 bytes. This means chunk sizes from 32 to 160 bytes fall within the fast bin range.
Finally the size for fast bin index is by default set to DEFAULT_MXFAST (64 * SIZE_SZ / 4) i.e 128 bytes on 64-bit systems (one can set it but can not go above MAX_FAST_SIZE otherwise out of bounds #define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)).
#ifndef DEFAULT_MXFAST
#define DEFAULT_MXFAST (64 * SIZE_SZ / 4)
#endif
...
set_max_fast (DEFAULT_MXFAST);
...
#define set_max_fast(s) \
global_max_fast = (((size_t) (s) <= MALLOC_ALIGN_MASK - SIZE_SZ) \
? MIN_CHUNK_SIZE / 2 : ((s + SIZE_SZ) & ~MALLOC_ALIGN_MASK))
...
static __always_inline INTERNAL_SIZE_T
get_max_fast (void)
{
if (global_max_fast > MAX_FAST_SIZE)
__builtin_unreachable ();
return global_max_fast;
}
...
# int_malloc()
...
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ())) # fast path decision boundary The next category of bins is small bins which uses FIFO semantic and houses chunks of size from 32 until 1008 bytes or [32, 1024[ (there are 62 small bins in 64 bits system).
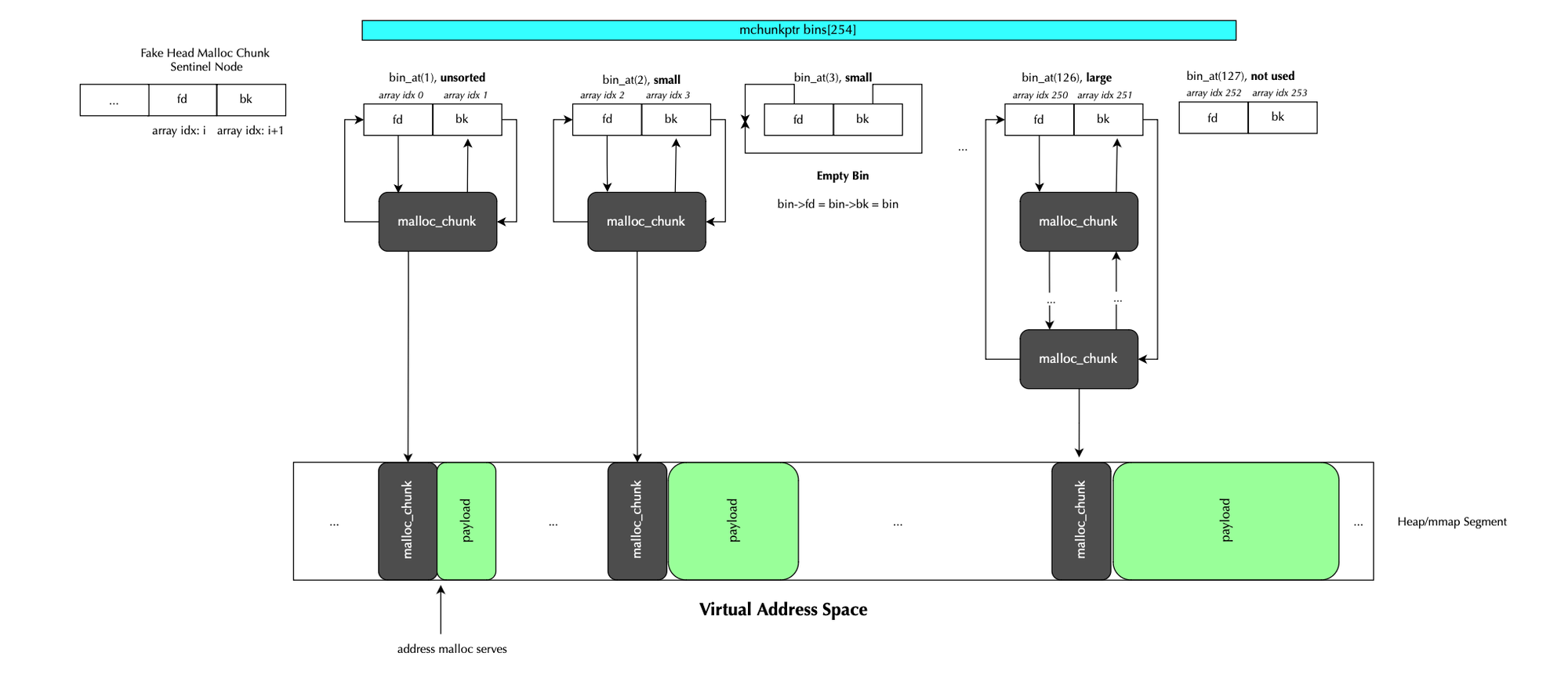
As discussed earlier, all bins (unsorted, large, and small) are housed in the bins array of the arena structure i.e malloc_state. Each bin occupies two entries in the array: the first for the forward pointer fd and the second for the backward pointer bk; basically they form a sentinel node for the double linked list. When a bin is empty, both fd and bk point to the sentinel node itself. This is illustrated below:
Small bins handle chunk sizes (request size + overhead) below MIN_LARGE_SIZE= NSMALLBINS.MALLOC_ALIGNMENT :
#define in_smallbin_range(sz) \
((unsigned long)(sz) < (unsigned long)MIN_LARGE_SIZE)
Bins are spaced by MALLOC_ALIGNMENT i.e size = index . MALLOC_ALIGNMENT. Specifically, malloc corrects the index if MALLOC_ALIGNMENT > CHUNK_HDR_SZ, i.e redefines the size indexing as size = (index-correction) . MALLOC_ALIGNMENT (honestly like this I dont' see why we need it...).
#define NBINS 128
#define NSMALLBINS 64
#define SMALLBIN_WIDTH MALLOC_ALIGNMENT
#define SMALLBIN_CORRECTION (MALLOC_ALIGNMENT > CHUNK_HDR_SZ)
#define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH)
The above gives born to the following macro:
#define smallbin_index(sz) \
((SMALLBIN_WIDTH == 16 ? (((unsigned)(sz)) >> 4) : (((unsigned)(sz)) >> 3)) \
+ SMALLBIN_CORRECTION)
Small bins manage chunks of size greater than DEFAULT_MXFAST (default is 128) and smaller than MIN_LARGE_SIZE (1008 bytes =(64 - 1) x 16). For example, if we consider a chunk of size 208 bytes (on a 64-bit system) the index is (208 / 16) + 1=14, so the bin index is 14 . To find the position in the bins array, the macro used is defined (bin_at()):
#define bin_at(m, i) \
(mbinptr)(((char *)&((m)->bins[((i) - 1) * 2])) \
- offsetof(struct malloc_chunk, fd))
Here, offsetof(struct malloc_chunk, fd) is used to represent the sentinel node. As we will cover in a future section, if bin_at(..).fd = bin_at(..).bk = bin_at(..) it means the bin is empty.
In contrast to other bins, unsorted bin stores chunks with arbitrary sizes. As we will cover later, large chunks returned to malloc are not indexed in their associated bins immediatly. They are first placed in the unsorted bin index and only during traversal later (when malloc is called) the freed chunks will be indexed in their associated bins i.e large bin index.
static INTERNAL_SIZE_T
_int_free_create_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size,
mchunkptr nextchunk, INTERNAL_SIZE_T nextsize)
{
if (nextchunk != av->top)
{
/* get and clear inuse bit */
bool nextinuse = inuse_bit_at_offset (nextchunk, nextsize);
/* consolidate forward */
if (!nextinuse) {
unlink_chunk (av, nextchunk);
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0);
mchunkptr bck, fwd;
if (!in_smallbin_range (size))
{
/* Place large chunks in unsorted chunk list. Large chunks are
not placed into regular bins until after they have
been given one chance to be used in malloc.
This branch is first in the if-statement to help branch
prediction on consecutive adjacent frees. */
bck = unsorted_chunks (av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("free(): corrupted unsorted chunks");
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
else
{
/* Place small chunks directly in their smallbin, so they
don't pollute the unsorted bin. */
int chunk_index = smallbin_index (size);
bck = bin_at (av, chunk_index);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("free(): chunks in smallbin corrupted");
mark_bin (av, chunk_index);
}
p->bk = bck;
p->fd = fwd;
bck->fd = p;
fwd->bk = p;
set_head(p, size | PREV_INUSE);
set_foot(p, size);
check_free_chunk(av, p);
}
else
{
/* If the chunk borders the current high end of memory,
consolidate into top. */
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}
return size;
}The small bin index starts at 2 while the bins array index 0 and 1 are occupied by the unsorted bin; the following macro is used during memory alloc/dealloc to get a pointer to the head of the double linked list (recall that the bin index =1 is different from that array bin index i.e o,1):
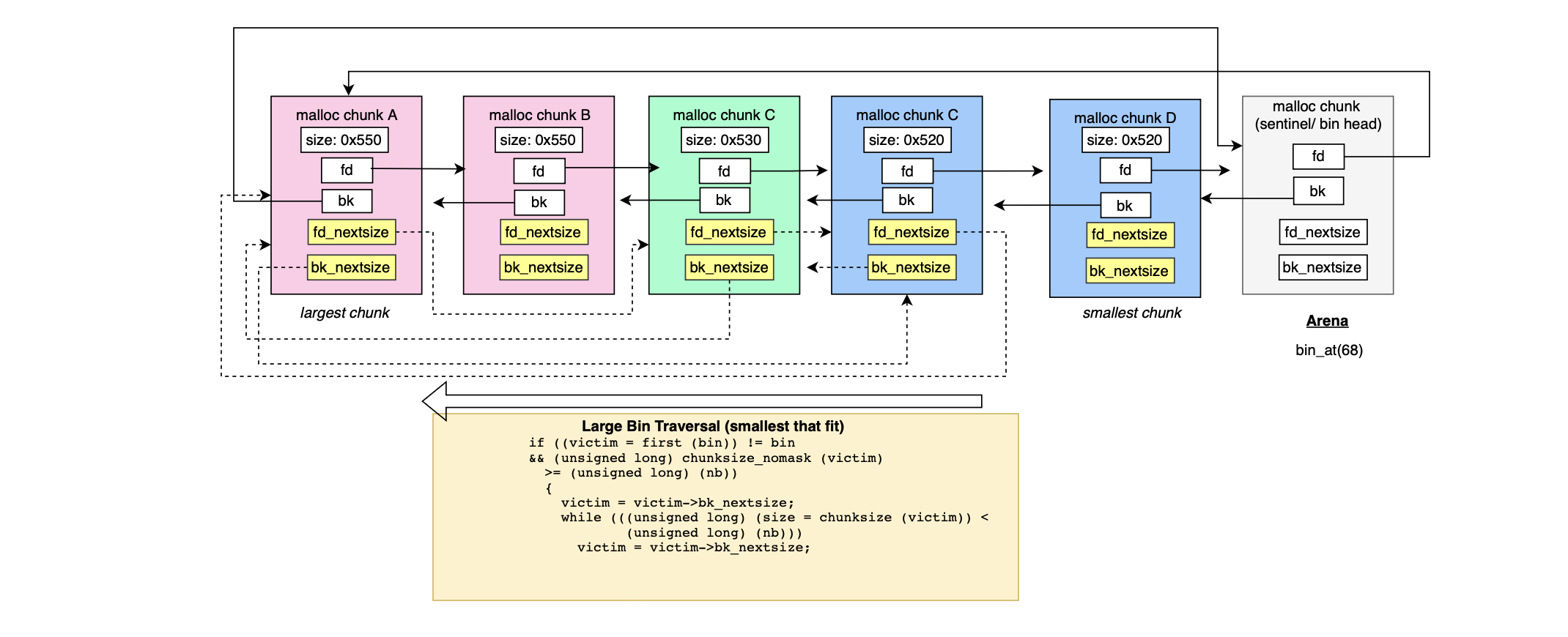
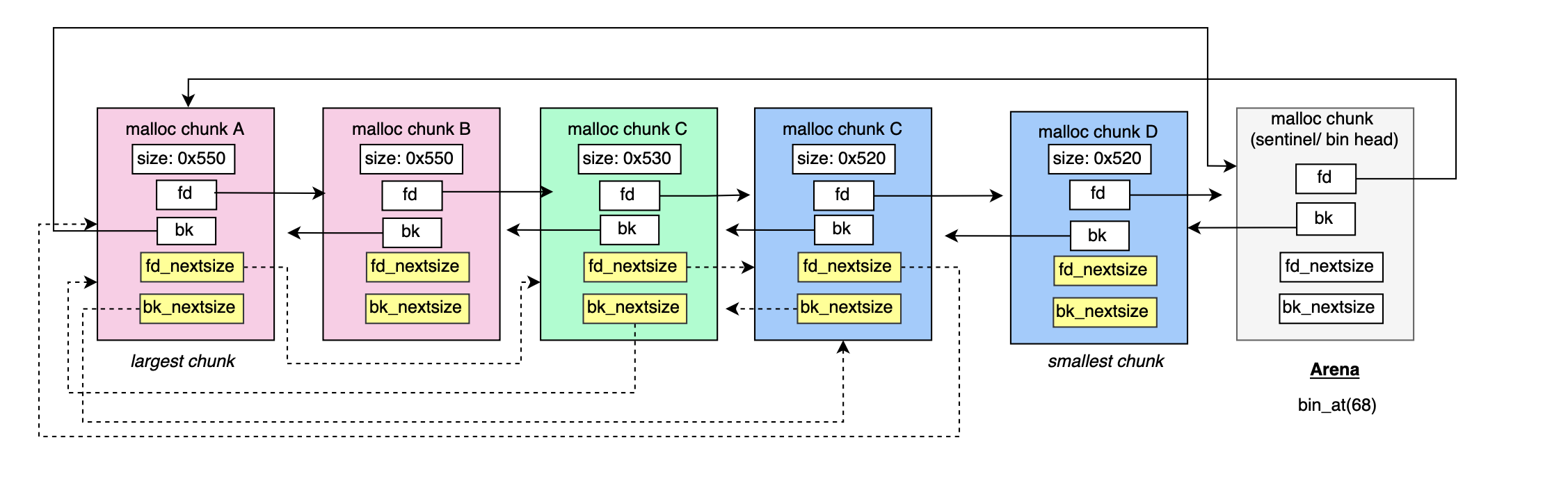
#define unsorted_chunks(M) (bin_at (M, 1))In contrast to small and fast bins, large bins store chunks within a specific range and not of same size (as it is completely impractical to maintain one bin for each size). In order to speed up the indexing and searching, two pointers fd_nextsize and bk_nextsize are introduced to traverse group of same sized chunks.
During allocation, bins are traversed in ascendant order (i.e find smallest that fits) through bk_nextsize until a chunk fit the request size and similarly while indexing (i.e bins coming from unsorted bin) fd_nextsize is used to traverse the double linked list and find the best position to place a given bin.
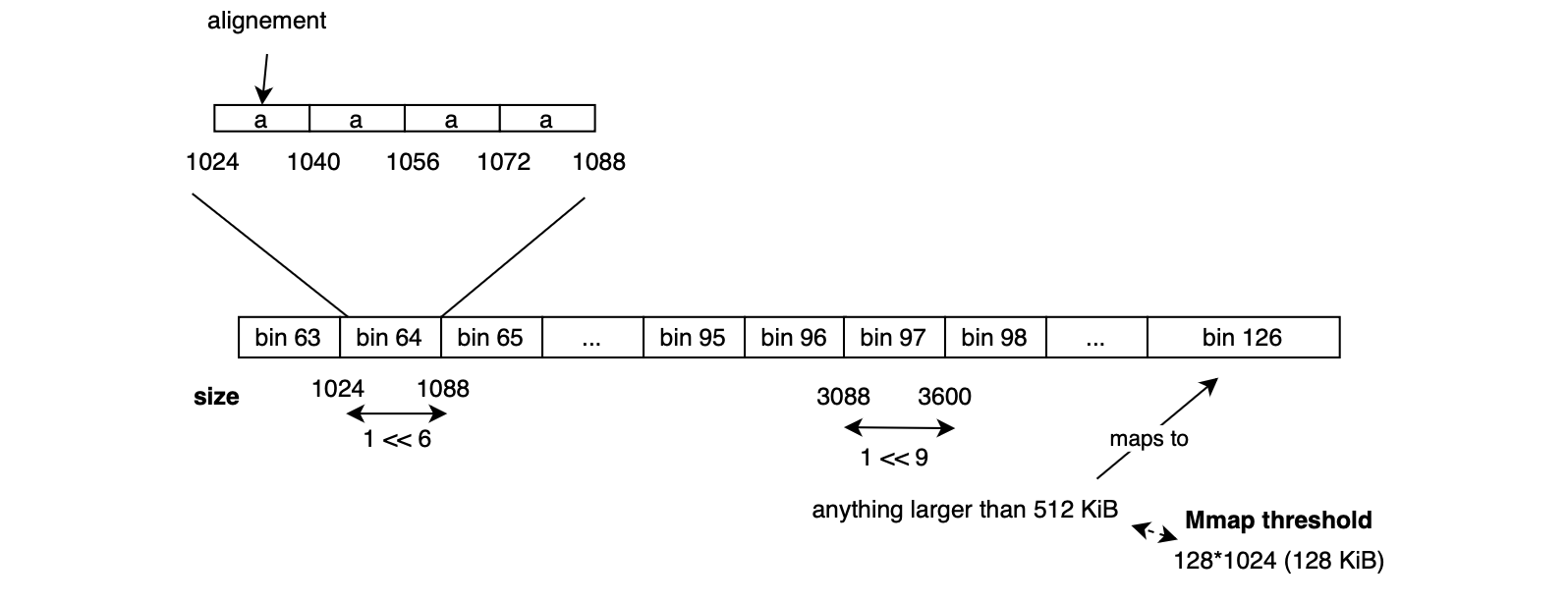
Malloc chunks with size larger than or equal to MIN_LARGE_SIZE bytes ( default 1024) are indexed in large bin index. The indexation logic is slightly more complex and is shown below:
#define largebin_index_64(sz) \
(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
126)Basically, in contrast to the small bin indexing approach, it does not increase the index every MALLOC_ALIGNMENT, it groups sizes by powers of two, for example, it updates the index once every 64 bytes if the chunk size falls in the range [1024, 3072] ( i.e every sz >> 6, which is by the way a multiple of MALLOC_ALIGNMENT) , if we consider a chunk of size 0x520 or 1312 then the bin index is 1312/64 + 48 = 68 (48 is an offset to make sure that we land at at at least one index after latest small bin index 64 = 1024/64 + 48). Chunks with size larger than >= 512 KiB falls into bin 126 i.e array positions (126‑1)*2 = 250 and 251 insidemchunkptr bins[NBINS*2 ‑ 2].
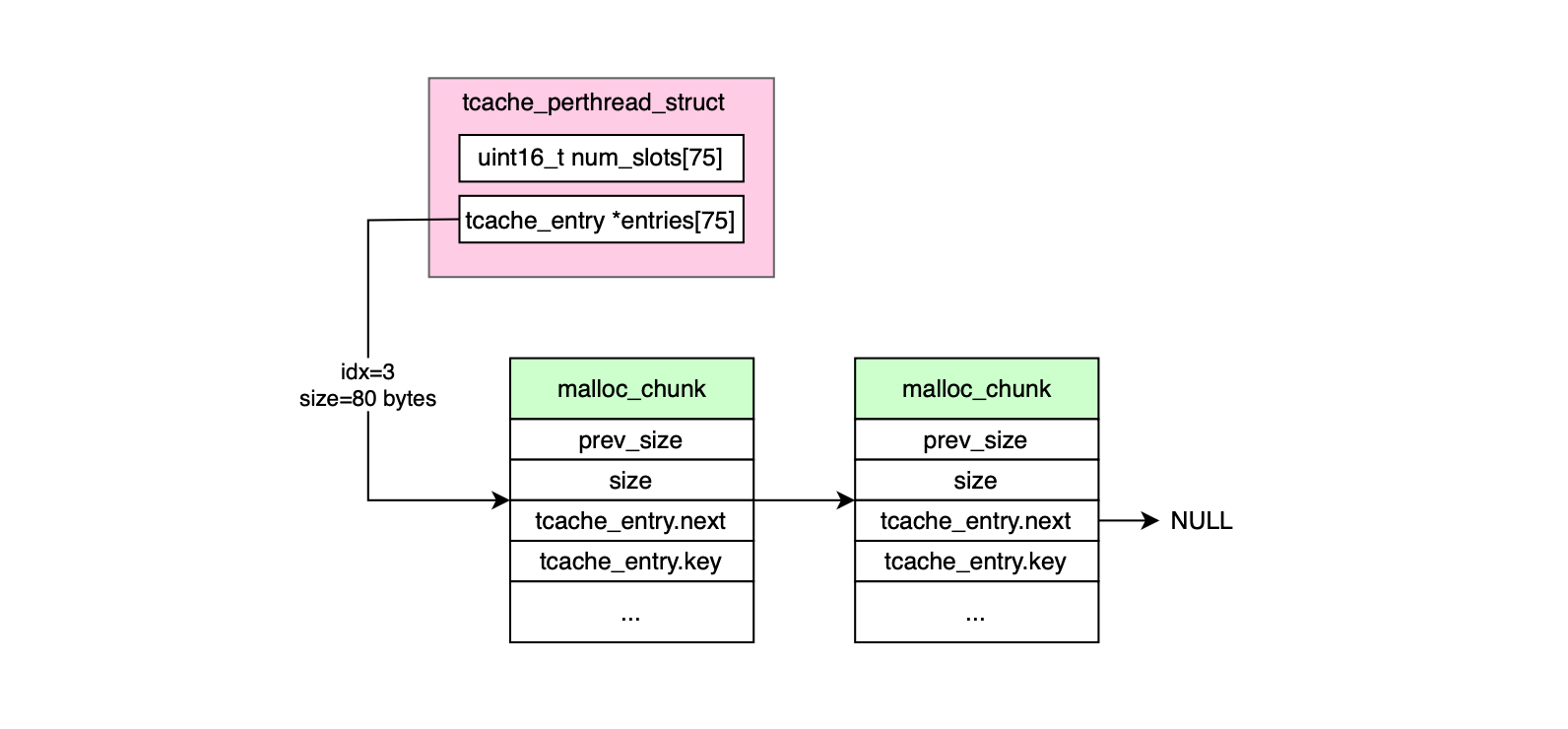
tcache_perthread_struct is a per-thread data structure that maintains thread-local bins. This is particularly efficient when several threads share the same arena and one wants to avoid the synchronization tax needed to operate on shared malloc state structure thereby improving performance in multi-threaded scenarios by reducing contention and latency for small, frequent allocations.
typedef struct tcache_perthread_struct
{
uint16_t num_slots[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
The bins are stored in a specific array, similarly to previous glibc versions (in new glibc version, logarithmic binning was introduced for large tcache chunks):
tcache_entry *entries[TCACHE_MAX_BINS];
...
# define TCACHE_SMALL_BINS 64
# define TCACHE_LARGE_BINS 12 /* Up to 4M chunks */
# define TCACHE_MAX_BINS (TCACHE_SMALL_BINS + TCACHE_LARGE_BINS)
# define MAX_TCACHE_SMALL_SIZE tidx2usize (TCACHE_SMALL_BINS-1) The number of free blocks that can be added inside each bin is indicated in num_slots (default is 7):
typedef struct tcache_perthread_struct
{
uint16_t num_slots[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
...
/* This is another arbitrary limit, which tunables can change. Each
tcache bin will hold at most this number of chunks. */
# define TCACHE_FILL_COUNT 7
There are basically 64 tcache small bins (housing chunks of the same size) and 12 tcache large bins (where each bin houses chunks of various size). The max bins index is then given by TCACHE_MAX_BINS = 75.
Each tcache bin (whether small or large) is a singly linked list. The nodes in that list are struct tcache_entry objects:
typedef struct tcache_entry {
struct tcache_entry *next; // Pointer to the next free chunk in the bin
uintptr_t key; // Used to detect double frees (security/integrity check)
} tcache_entry;
The key field helps detecting double frees by storing a thread specific value:
static void
tcache_key_initialize (void)
{
/* We need to use the _nostatus version here, see BZ 29624. */
if (__getrandom_nocancel_nostatus_direct (&tcache_key, sizeof(tcache_key),
GRND_NONBLOCK)
!= sizeof (tcache_key))
{
tcache_key = random_bits ();
#if __WORDSIZE == 64
tcache_key = (tcache_key << 32) | random_bits ();
#endif
}
} When a chunk is placed into the tcache, its user area (starting just after the size field) is reused to store the tcache_entry.
static __always_inline void
tcache_put_n (mchunkptr chunk, size_t tc_idx, tcache_entry **ep, bool mangled)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
/* Mark this chunk as "in the tcache" so the test in __libc_free will
detect a double free. */
e->key = tcache_key;
if (!mangled)
{
e->next = PROTECT_PTR (&e->next, *ep);
*ep = e;
}
else
{
e->next = PROTECT_PTR (&e->next, REVEAL_PTR (*ep));
*ep = PROTECT_PTR (ep, e);
}
--(tcache->num_slots[tc_idx]);
}The chunk2mem macro used to get the user pointer from a chunk is:
#define chunk2mem(p) ((void*)((char*)(p) + CHUNK_HDR_SZ))For small tcache bins (indices 0...63), the indexing is straightforward and linear, very much like the old fastbins (offset by MINSIZE to align the minimum chunk to index 0):
# define csize2tidx(x) (((x) - MINSIZE) / MALLOC_ALIGNMENT)Here the indexing follows the formula size = MINSIZE + index.MALLOC_ALIGNEMT, where a is MALLOC_ALIGNMENT . For instance if i = 0, then size = MINSIZE = 32, if i = 1, then size = 32 + 16 = 48, i = 2, then size = 48 + 16 = 64 ect, thus similar to earlier versions, there are 64 small bins (up to 1024 bytes) and 12 extra bins for large chunks (up to 4194303 bytes) as listed below.
# define TCACHE_SMALL_BINS 64
# define TCACHE_LARGE_BINS 12 /* Up to 4M chunks */
# define TCACHE_MAX_BINS (TCACHE_SMALL_BINS + TCACHE_LARGE_BINS)
# define MAX_TCACHE_SMALL_SIZE tidx2usize (TCACHE_SMALL_BINS-1)
The insertion inside the tcache is shown below:
size_t tc_idx = csize2tidx (size);
if (__glibc_likely (tc_idx < TCACHE_SMALL_BINS))
{
if (__glibc_likely (tcache->num_slots[tc_idx] != 0))
return tcache_put (p, tc_idx);
}
else
{
tc_idx = large_csize2tidx (size);
if (size >= MINSIZE
&& !chunk_is_mmapped (p)
&& __glibc_likely (tcache->num_slots[tc_idx] != 0))
return tcache_put_large (p, tc_idx);
}
}
Small chunks are indexed similar to previous versions, that is, one bin index houses chunks of the same size.
static __always_inline void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_put_n (chunk, tc_idx, &tcache->entries[tc_idx], false);
}
...
/* Caller must ensure that we know tc_idx is valid and there's room
for more chunks. */
static __always_inline void
tcache_put_n (mchunkptr chunk, size_t tc_idx, tcache_entry **ep, bool mangled)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
/* Mark this chunk as "in the tcache" so the test in __libc_free will
detect a double free. */
e->key = tcache_key;
if (!mangled)
{
e->next = PROTECT_PTR (&e->next, *ep);
*ep = e;
}
else
{
e->next = PROTECT_PTR (&e->next, REVEAL_PTR (*ep));
*ep = PROTECT_PTR (ep, e);
}
--(tcache->num_slots[tc_idx]);
}On the other hand, larger chunks don’t grow linearly and instead they use the logarithmic mapping (large_csize2tidx). Specifically, it uses __builtin_clz, returning the number of leading 0-bits. The routine is listed below:
static __always_inline size_t
large_csize2tidx(size_t nb)
{
size_t idx = TCACHE_SMALL_BINS
+ __builtin_clz (MAX_TCACHE_SMALL_SIZE)
- __builtin_clz (nb);
return idx;
}The tcache in glibc >= 2.42 can now hold chunks up to 4 MiB (4194303 bytes), with the maximum valid tcache index being 75. At runtime, when setting the max bytes for tcache, glibc ensures tc_idx < TCACHE_MAX_BINS thereby avoiding out-of-bounds access.
static __always_inline int
do_set_tcache_max (size_t value)
{
size_t nb = request2size (value);
size_t tc_idx = csize2tidx (nb);
/* To check that value is not too big and request2size does not return an
overflown value. */
if (value > nb)
return 0;
if (nb > MAX_TCACHE_SMALL_SIZE)
tc_idx = large_csize2tidx (nb);
LIBC_PROBE (memory_tunable_tcache_max_bytes, 2, value, mp_.tcache_max_bytes);
if (tc_idx < TCACHE_MAX_BINS)
{
if (tc_idx < TCACHE_SMALL_BINS)
mp_.tcache_small_bins = tc_idx + 1;
mp_.tcache_max_bytes = nb;
return 1;
}
return 0;
}The allocator's state initialization is performed using malloc_init_state(). As shown below, unlike fast bins, which do not require explicit initialization, the bins array must be explicitly initialized. This involves setting the header and tail pointers to point to the sentinel bin itself, i.e., bin->fd = bin->bk = bin, as previously explained.
static void
malloc_init_state (mstate av)
{
int i;
mbinptr bin;
/* Establish circular links for normal bins */
for (i = 1; i < NBINS; ++i)
{
bin = bin_at (av, i);
bin->fd = bin->bk = bin;
}
#if MORECORE_CONTIGUOUS
if (av != &main_arena)
#endif
set_noncontiguous (av);
if (av == &main_arena)
set_max_fast (DEFAULT_MXFAST);
atomic_store_relaxed (&av->have_fastchunks, false);
av->top = initial_top (av);
}The maximum chunk size handled via fast bins is also set during initialization using set_max_fast (with a default of 128 bytes, i.e fast bins index chunk of size ranging from 32 bytes to 128 bytes). The have_fastchunks flag is a boolean represented as an int (since atomic operations on booleans are not always possible) and indicates whether there are any fastbin chunks available. It is set atomically using relaxed memory ordering, which is sufficient here as one only needs to defeat compiler optimizations. Finally, the top chunk of the arena is initialized to point at unsorted bin.
The entry point for memory allocation in glibc is __libc_malloc(). If tcache is not enabled it delegates directly to __libc_malloc2().
void *
__libc_malloc (size_t bytes)
{
#if USE_TCACHE
size_t nb = checked_request2size (bytes);
if (nb == 0)
{
__set_errno (ENOMEM);
return NULL;
}
if (nb < mp_.tcache_max_bytes)
{
size_t tc_idx = csize2tidx (nb);
if(__glibc_unlikely (tcache == NULL))
return tcache_malloc_init (bytes);
if (__glibc_likely (tc_idx < TCACHE_SMALL_BINS))
{
if (tcache->entries[tc_idx] != NULL)
return tag_new_usable (tcache_get (tc_idx));
}
else
{
tc_idx = large_csize2tidx (nb);
void *victim = tcache_get_large (tc_idx, nb);
if (victim != NULL)
return tag_new_usable (victim);
}
}
#endif
return __libc_malloc2 (bytes);
}If the tcache is enabled, the size is mapped to include the overhead and ensure alignment size_t nb = checked_request2size (bytes);. If memory tagging is enabled, the size is first aligned to __MTAG_GRANULE_SIZE before delegating to request2size (req);.
static __always_inline size_t
checked_request2size (size_t req) __nonnull (1)
{
_Static_assert (PTRDIFF_MAX <= SIZE_MAX / 2,
"PTRDIFF_MAX is not more than half of SIZE_MAX");
if (__glibc_unlikely (req > PTRDIFF_MAX))
return 0;
/* When using tagged memory, we cannot share the end of the user
block with the header for the next chunk, so ensure that we
allocate blocks that are rounded up to the granule size. Take
care not to overflow from close to MAX_SIZE_T to a small
number. Ideally, this would be part of request2size(), but that
must be a macro that produces a compile time constant if passed
a constant literal. */
if (__glibc_unlikely (mtag_enabled))
{
/* Ensure this is not evaluated if !mtag_enabled, see gcc PR 99551. */
asm ("");
req = (req + (__MTAG_GRANULE_SIZE - 1)) &
~(size_t)(__MTAG_GRANULE_SIZE - 1);
}
return request2size (req);
}The macro request2size() is defined below. It adds SIZE_SZ overhead and round up to next aligned value (ensuring that initial size + overhead + alignment -1 is at least MINSIZE).
#define request2size(req) \
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
MINSIZE : \
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)Next, still on the tcache allocation path, if the the mapped size is smaller than configured size if (nb < mp_.tcache_max_bytes) , the thread index is inferred using the macro csize2tidx:
# define csize2tidx(x) (((x) - MINSIZE) / MALLOC_ALIGNMENT)If tcache is NULL , it means there is naturally no chunk to get served from the tcache. In this case, the tcache is initialized; which consists of allocating memory for housing a data structure of type tcache_perthread_struct and setting the thread local variable tcache. Then the user get a memory chunk from __libc_malloc2 (bytes) (will be covered in a moment).
static void
tcache_init (void)
{
if (tcache_shutting_down)
return;
/* Check minimum mmap chunk is larger than max tcache size. This means
mmap chunks with their different layout are never added to tcache. */
if (MAX_TCACHE_SMALL_SIZE >= GLRO (dl_pagesize) / 2)
malloc_printerr ("max tcache size too large");
size_t bytes = sizeof (tcache_perthread_struct);
tcache = (tcache_perthread_struct *) __libc_malloc2 (bytes);
if (tcache != NULL)
{
memset (tcache, 0, bytes);
for (int i = 0; i < TCACHE_MAX_BINS; i++)
tcache->num_slots[i] = mp_.tcache_count;
}
}
...
static __thread tcache_perthread_struct *tcache = NULL;Now if the tcache is not null, then there is possibly a free chunk that can be served. This is achieved by checking if the associated entry tcache->entries[tc_idx] is NULL.
if (__glibc_likely (tc_idx < TCACHE_SMALL_BINS))
{
if (tcache->entries[tc_idx] != NULL)
return tag_new_usable (tcache_get (tc_idx));
}A pointer to user chunk is obtained using the following macro tcache_get (tc_idx):
static __always_inline void *
tcache_get (size_t tc_idx)
{
return tcache_get_n (tc_idx, & tcache->entries[tc_idx], false);
}As listed below, tcache_get_n() removes the chunk from the linked list while coping with pointer mangling.
static __always_inline void *
tcache_get_n (size_t tc_idx, tcache_entry **ep, bool mangled)
{
tcache_entry *e;
if (!mangled)
e = *ep;
else
e = REVEAL_PTR (*ep);
if (__glibc_unlikely (misaligned_mem (e)))
malloc_printerr ("malloc(): unaligned tcache chunk detected");
void *ne = e == NULL ? NULL : REVEAL_PTR (e->next);
if (!mangled)
*ep = ne;
else
*ep = PROTECT_PTR (ep, ne);
++(tcache->num_slots[tc_idx]);
e->key = 0;
return (void *) e;
}If memory tagging is enabled, tag_new_usable() is invoked to create a new tag __libc_mtag_new_tag and tag the usable memory chunk (memsize()).
static __always_inline void *
tag_new_usable (void *ptr)
{
if (__glibc_unlikely (mtag_enabled) && ptr)
{
mchunkptr cp = mem2chunk(ptr);
ptr = __libc_mtag_tag_region (__libc_mtag_new_tag (ptr), memsize (cp));
}
return ptr;
}If the tcache chunk is large i.e the following condition does not hold:
if (__glibc_likely (tc_idx < TCACHE_SMALL_BINS))The tcache linked list is traversed to serve the first chunk larger or equal to the chunk size.
static __always_inline void *
tcache_get_large (size_t tc_idx, size_t nb)
{
tcache_entry **entry;
bool mangled = false;
entry = tcache_location_large (nb, tc_idx, &mangled);
if ((mangled && REVEAL_PTR (*entry) == NULL)
|| (!mangled && *entry == NULL))
return NULL;
return tcache_get_n (tc_idx, entry, mangled);
}
static __always_inline tcache_entry **
tcache_location_large (size_t nb, size_t tc_idx, bool *mangled)
{
tcache_entry **tep = &(tcache->entries[tc_idx]);
tcache_entry *te = *tep;
while (te != NULL
&& __glibc_unlikely (chunksize (mem2chunk (te)) < nb))
{
tep = & (te->next);
te = REVEAL_PTR (te->next);
*mangled = true;
}
return tep;
}The allocator ensures that the tcache bins list is always maintained in order; relevant for large tcache chunks only.
static __always_inline tcache_entry **
tcache_location_large (size_t nb, size_t tc_idx, bool *mangled)
{
tcache_entry **tep = &(tcache->entries[tc_idx]);
tcache_entry *te = *tep;
while (te != NULL
&& __glibc_unlikely (chunksize (mem2chunk (te)) < nb))
{
tep = & (te->next);
te = REVEAL_PTR (te->next);
*mangled = true;
}
return tep;
}
static __always_inline void
tcache_put_large (mchunkptr chunk, size_t tc_idx)
{
tcache_entry **entry;
bool mangled = false;
entry = tcache_location_large (chunksize (chunk), tc_idx, &mangled);
return tcache_put_n (chunk, tc_idx, entry, mangled);
}Now if the tcache is not enabled or simply can't serve the user request, the call is delegated to __libc_malloc2 (bytes);
Before discussing __libc_malloc2, let's quickly go through the pointer masking used in tcache and fastbins. In order to obfuscate pointers of single linked-list data structures from corruption, the allocator uses pointer mangling proposed by CheckPoint:
/* Safe-Linking:
Use randomness from ASLR (mmap_base) to protect single-linked lists
of Fast-Bins and TCache. That is, mask the "next" pointers of the
lists' chunks, and also perform allocation alignment checks on them.
This mechanism reduces the risk of pointer hijacking, as was done with
Safe-Unlinking in the double-linked lists of Small-Bins.
It assumes a minimum page size of 4096 bytes (12 bits). Systems with
larger pages provide less entropy, although the pointer mangling
still works. */
#define PROTECT_PTR(pos, ptr) \
((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))
#define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)Relying on the randomness provided by the ASLR, the heap address of the next pointer field (i.e the address of the tcache_entry->next field) is shifted by 12 bits and xor ed with the next pointer (that we want to mask, that is, the next chunk in the free list). The mmap_base or brk base is randomized by the kernel using the following offset random_base = ((1 << rndbits) - 1) << PAGE_SHIFT; providing 2^rndbits uniformly possible heap start addresses, each aligned to a page.
\(\text{PROTECT_PTR}(p, x) = \left( \left\lfloor \frac{p}{2^{12}} \right\rfloor \oplus x \right) \)
\(\text{REVEAL_PTR}(x') = \text{PROTECT_PTR}(p, x') = \left( \left\lfloor \frac{p}{2^{12}} \right\rfloor \oplus x' \right) \)
Thus the key is basically the heap address shifted and xored meaning a heap leak defeats the above protection. In order to reveal a pointer housed inside a linked list entry, the address of the next pointer is used, as bitwise XOR operations are involutive i.e (x XOR k) XOR k = x.
If tcache cannot serve the request, control is passed to __libc_malloc2, which continues allocation using the arena:
static void * __attribute_noinline__
__libc_malloc2 (size_t bytes)
{
mstate ar_ptr;
void *victim;
if (SINGLE_THREAD_P)
{
victim = tag_new_usable (_int_malloc (&main_arena, bytes));
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
&main_arena == arena_for_chunk (mem2chunk (victim)));
return victim;
}
arena_get (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
/* Retry with another arena only if we were able to find a usable arena
before. */
if (!victim && ar_ptr != NULL)
{
LIBC_PROBE (memory_malloc_retry, 1, bytes);
ar_ptr = arena_get_retry (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
}
if (ar_ptr != NULL)
__libc_lock_unlock (ar_ptr->mutex);
victim = tag_new_usable (victim);
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
ar_ptr == arena_for_chunk (mem2chunk (victim)));
return victim;
}In case we are in a single thread scenario, there is no potential race condition. The user chunk is allocated and tagged if applicable victim = tag_new_usable (_int_malloc (&main_arena, bytes));, next either the allocation happened i.e the pointer is not null, otherwise the chunk is either mmapped or belongs to the main arena (which can be inferred by inspecting the size field).
#define chunk_main_arena(p) (((p)->mchunk_size & NON_MAIN_ARENA) == 0)
...
static __always_inline struct malloc_state *
arena_for_chunk (mchunkptr ptr)
{
return chunk_main_arena (ptr) ? &main_arena : heap_for_ptr (ptr)->ar_ptr;
}In case the program supports multiple threads, arena_get() is invoked to acquire the arena's mutex associated with the underlying thread.
#define arena_get(ptr, size) do { \
ptr = thread_arena; \
arena_lock (ptr, size); \
} while (0)
#define arena_lock(ptr, size) do { \
if (ptr) \
__libc_lock_lock (ptr->mutex); \
else \
ptr = arena_get2 ((size), NULL); \
} while (0)
If a thread is not yet attached to any arena, the allocator will assign it to an existing arena if possible, or create a new one and associate the thread with it.
static mstate
arena_get2 (size_t size, mstate avoid_arena)
{
mstate a;
static size_t narenas_limit;
a = get_free_list ();
if (a == NULL)
{
/* Nothing immediately available, so generate a new arena. */
if (narenas_limit == 0)
{
if (mp_.arena_max != 0)
narenas_limit = mp_.arena_max;
else if (narenas > mp_.arena_test)
{
int n = __get_nprocs ();
if (n >= 1)
narenas_limit = NARENAS_FROM_NCORES (n);
else
/* We have no information about the system. Assume two
cores. */
narenas_limit = NARENAS_FROM_NCORES (2);
}
}
repeat:;
size_t n = narenas;
/* NB: the following depends on the fact that (size_t)0 - 1 is a
very large number and that the underflow is OK. If arena_max
is set the value of arena_test is irrelevant. If arena_test
is set but narenas is not yet larger or equal to arena_test
narenas_limit is 0. There is no possibility for narenas to
be too big for the test to always fail since there is not
enough address space to create that many arenas. */
if (__glibc_unlikely (n <= narenas_limit - 1))
{
if (catomic_compare_and_exchange_bool_acq (&narenas, n + 1, n))
goto repeat;
a = _int_new_arena (size);
if (__glibc_unlikely (a == NULL))
catomic_decrement (&narenas);
}
else
a = reused_arena (avoid_arena);
}
return a;
}Specifically, the allocator will try first to serve an arena from the free list:
static mstate
get_free_list (void)
{
mstate replaced_arena = thread_arena;
mstate result = free_list;
if (result != NULL)
{
__libc_lock_lock (free_list_lock);
result = free_list;
if (result != NULL)
{
free_list = result->next_free;
/* The arena will be attached to this thread. */
assert (result->attached_threads == 0);
result->attached_threads = 1;
detach_arena (replaced_arena);
}
__libc_lock_unlock (free_list_lock);
if (result != NULL)
{
LIBC_PROBE (memory_arena_reuse_free_list, 1, result);
__libc_lock_lock (result->mutex);
thread_arena = result;
}
}
return result;
}Otherwise if the number of created arenas does not exceed the limit, a new one is created:
if (__glibc_unlikely (n <= narenas_limit - 1))
{
if (catomic_compare_and_exchange_bool_acq (&narenas, n + 1, n))
goto repeat;
a = _int_new_arena (size);
if (__glibc_unlikely (a == NULL))
catomic_decrement (&narenas);
}If the number of arenas reaches the limit, the allocator iterate over available arenas, starting from the main arena. Specifically, if attempts to return the first less solicited arena i.e for which the lock can be acquired without contention if (!__libc_lock_trylock (result->mutex)) (unlike spinlocks, mutexes cause threads that fail to acquire the lock to be descheduled, rather than spinning, which reduces cpu usage under contention; for more details about locks, please refer to my previous post: https://www.deep-kondah.com/on-the-complexity-of-synchronization-memory-barriers-locks-and-scalability/).If none can be returned, then the current thread needs to wait for the lock __libc_lock_lock (result->mutex); and finally once the task is resumed, the allocator attaches the arena to the current thread.
static mstate
reused_arena (mstate avoid_arena)
{
mstate result;
/* FIXME: Access to next_to_use suffers from data races. */
static mstate next_to_use;
if (next_to_use == NULL)
next_to_use = &main_arena;
/* Iterate over all arenas (including those linked from
free_list). */
result = next_to_use;
do
{
if (!__libc_lock_trylock (result->mutex))
goto out;
/* FIXME: This is a data race, see _int_new_arena. */
result = result->next;
}
while (result != next_to_use);
/* Avoid AVOID_ARENA as we have already failed to allocate memory
in that arena and it is currently locked. */
if (result == avoid_arena)
result = result->next;
/* No arena available without contention. Wait for the next in line. */
LIBC_PROBE (memory_arena_reuse_wait, 3, &result->mutex, result, avoid_arena);
__libc_lock_lock (result->mutex);
out:
/* Attach the arena to the current thread. */
{
/* Update the arena thread attachment counters. */
mstate replaced_arena = thread_arena;
__libc_lock_lock (free_list_lock);
detach_arena (replaced_arena);
/* We may have picked up an arena on the free list. We need to
preserve the invariant that no arena on the free list has a
positive attached_threads counter (otherwise,
arena_thread_freeres cannot use the counter to determine if the
arena needs to be put on the free list). We unconditionally
remove the selected arena from the free list. The caller of
reused_arena checked the free list and observed it to be empty,
so the list is very short. */
remove_from_free_list (result);
++result->attached_threads;
__libc_lock_unlock (free_list_lock);
}
LIBC_PROBE (memory_arena_reuse, 2, result, avoid_arena);
thread_arena = result;
next_to_use = result->next;
return result;
}Now once the thread has an arena attached (housing memory chunks), the allocator can use it to allocate a chunk of memory by delegating the control to _int_malloc(), victim = _int_malloc (ar_ptr, bytes). Finally the arena lock is released __libc_lock_unlock (ar_ptr->mutex); and the memory chunk is served (with memory tagging if applicable victim = tag_new_usable (victim)).
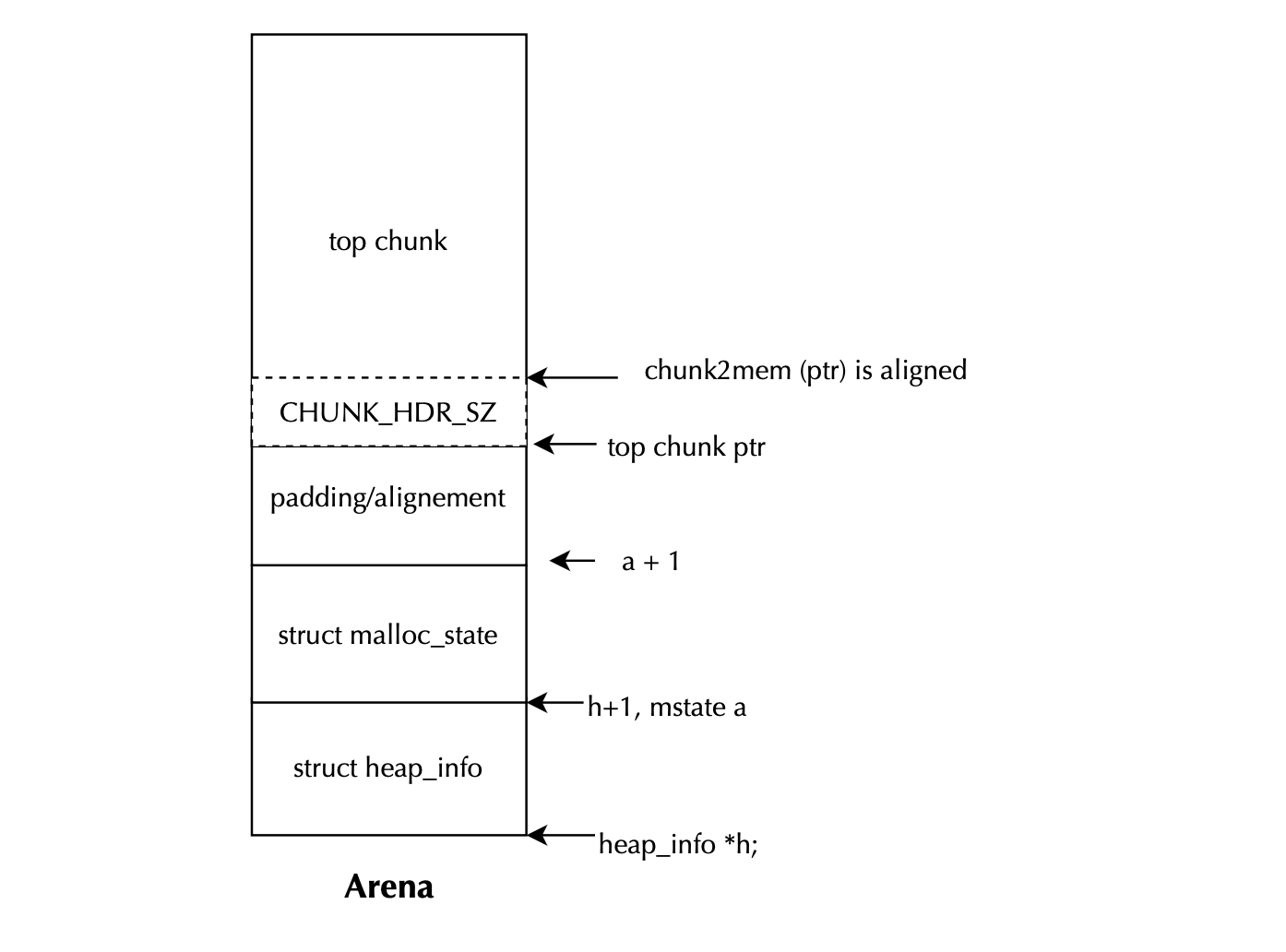
The code for creating a new arena is located in _int_new_arena() and works as follows. Given a request size plus overhead, it allocates a new heap (via alloc_new_heap). The heap is described by a heap_info struct, followed in memory by an mstate (the malloc state data structure representing the arena), and finally padding is added for alignment purposes.
The top_pad value (stored in malloc_par or _mp) is added on top of the requested size to accommodate future allocations without immediately requiring additional mmap calls. The heap is allocated via new_heap (discussed in the next subsection):
h = new_heap(size + (sizeof(*h) + sizeof(*a) + MALLOC_ALIGNMENT), mp_.top_pad);
Here, MALLOC_ALIGNMENT is added to ensure that after placing heap_info and malloc_state, there is enough padding to allow the start of the user allocations (i.e chunk2mem (ptr)) to be rounded up to the next aligned address. This is sufficient because, in the worst case, the starting address could be misaligned by up toMALLOC_ALIGNMENT - 1. The malloc state pointer is then initialized:
a = h->ar_ptr = (mstate)(h + 1);
Adding 1 to a pointer of type heap_info * advances it by sizeof(heap_info) bytes. Next, the arena is initialized via malloc_init_state, which was covered earlier. The top chunk of the arena begins at:
ptr = (char *)(a + 1);
This pointer is checked for alignment to MALLOC_ALIGNMENT to ensure the memory returned to the user is properly aligned:
misalign = (uintptr_t)chunk2mem(ptr) & MALLOC_ALIGN_MASK;
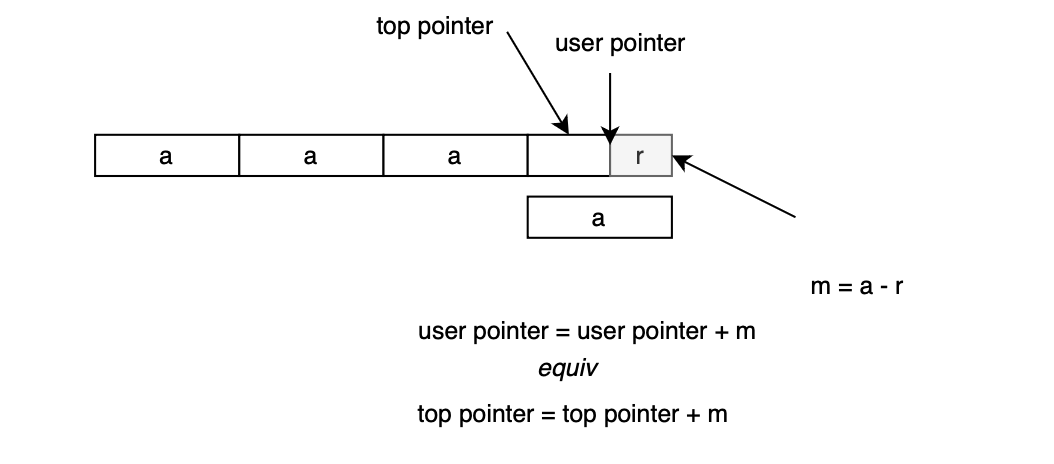
If not aligned, the top chunk pointer is adjusted:
ptr += MALLOC_ALIGNMENT - misalign;
This ensures ptr is properly aligned by advancing it past the misalignment. The arena’s top chunk is then set top(a) = (mchunkptr)ptr; and metadata of the top chunk is updated as well:
set_head(top(a), (((char *)h + h->size) - ptr) | PREV_INUSE);
This sets the top chunk’s size to cover the remaining heap space (from the aligned ptr to the end of the heap i.e (char *)h + h->size) - ptr) and marks it asPREV_INUSE. The PREV_INUSE bit is always set for the top chunk. Finally, the new arena is chained to main_arena, and the previous arena is detached from the current thread via detach_arena(replaced_arena);.
The code for creating a new heap is shown below.
static heap_info *
new_heap (size_t size, size_t top_pad)
{
if (mp_.hp_pagesize != 0 && mp_.hp_pagesize <= heap_max_size ())
{
heap_info *h = alloc_new_heap (size, top_pad, mp_.hp_pagesize,
mp_.hp_flags);
if (h != NULL)
return h;
}
return alloc_new_heap (size, top_pad, GLRO (dl_pagesize), 0);
}
...
static heap_info *
alloc_new_heap (size_t size, size_t top_pad, size_t pagesize,
int mmap_flags)
{
char *p1, *p2;
unsigned long ul;
heap_info *h;
size_t min_size = heap_min_size ();
size_t max_size = heap_max_size ();
if (size + top_pad < min_size)
size = min_size;
else if (size + top_pad <= max_size)
size += top_pad;
else if (size > max_size)
return NULL;
else
size = max_size;
size = ALIGN_UP (size, pagesize);
/* A memory region aligned to a multiple of max_size is needed.
No swap space needs to be reserved for the following large
mapping (on Linux, this is the case for all non-writable mappings
anyway). */
p2 = MAP_FAILED;
if (aligned_heap_area)
{
p2 = (char *) MMAP (aligned_heap_area, max_size, PROT_NONE, mmap_flags);
aligned_heap_area = NULL;
if (p2 != MAP_FAILED && ((unsigned long) p2 & (max_size - 1)))
{
__munmap (p2, max_size);
p2 = MAP_FAILED;
}
}
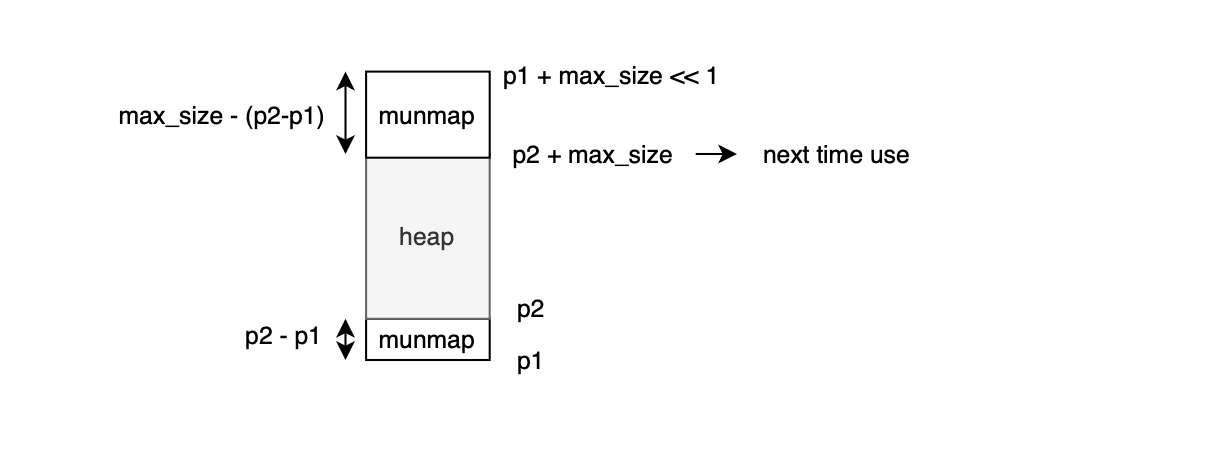
if (p2 == MAP_FAILED)
{
p1 = (char *) MMAP (NULL, max_size << 1, PROT_NONE, mmap_flags);
if (p1 != MAP_FAILED)
{
p2 = (char *) (((uintptr_t) p1 + (max_size - 1))
& ~(max_size - 1));
ul = p2 - p1;
if (ul)
__munmap (p1, ul);
else
aligned_heap_area = p2 + max_size;
__munmap (p2 + max_size, max_size - ul);
}
else
{
/* Try to take the chance that an allocation of only max_size
is already aligned. */
p2 = (char *) MMAP (NULL, max_size, PROT_NONE, mmap_flags);
if (p2 == MAP_FAILED)
return NULL;
if ((unsigned long) p2 & (max_size - 1))
{
__munmap (p2, max_size);
return NULL;
}
}
}
if (__mprotect (p2, size, mtag_mmap_flags | PROT_READ | PROT_WRITE) != 0)
{
__munmap (p2, max_size);
return NULL;
}
/* Only considere the actual usable range. */
__set_vma_name (p2, size, " glibc: malloc arena");
madvise_thp (p2, size);
h = (heap_info *) p2;
h->size = size;
h->mprotect_size = size;
h->pagesize = pagesize;
LIBC_PROBE (memory_heap_new, 2, h, h->size);
return h;
}In its simplest form, the allocator first reserves virtual address space using MMAP(NULL, max_size, PROT_NONE, mmap_flags);, if the address returned by mmap is aligned to max_size, it then change the protection flags of the already reserved virtual address range using __mprotect(p2, size, mtag_mmap_flags | PROT_READ | PROT_WRITE);. Otherwise, it unmaps the region. Specifically, it starts by requesting 2*max_sizeor max_size << 1 of virtual memory space, p1 = (char *) MMAP(NULL, max_size << 1, PROT_NONE, mmap_flags);, it then rounds up the base address to the next max_size-aligned boundary p2 = (char *) (((uintptr_t)p1 + (max_size - 1)) & ~(max_size - 1));, to reduce heap fragmentation and simplify management (e.g one can know heap from pointer by simply rounding down to nearest multiple of HEAP_MAX_SIZE i.e heap_info *h = (heap_info *) ((uintptr_t)p & ~(HEAP_MAX_SIZE - 1));), it updates a global variable for next heap allocation aligned_heap_area = p2 + max_size;, which marks the next aligned region that may be reused later. The allocator then unmaps any unused memory before the aligned address __munmap(p1, ul);, ul = p2 - p1 and also unmaps the unused tail __munmap(p2 + max_size, max_size - ul);. After storing aligned_heap_area = p2 + max_size, future heap allocations can attempt to reuse this address by passing it as a hint to mmap p2 = (char *) MMAP(aligned_heap_area, max_size, PROT_NONE, mmap_flags);. The newly mapped region is then labeled __set_vma_name(p2, size, "glibc: malloc arena");. Finally, it calls madvise_thp(p2, size);, to hint that the region should be backed by Transparent Huge Pages (THP), and returns the heap pointer h = (heap_info *) p2;.
As discussed earlier, when the number of arenas created exceeds a predefined threshold, the requesting thread must reuse an existing arena for memory allocation. The code implementing this logic is found in reused_arena(mstate avoid_arena). It attempts to acquire the lock without contention __libc_lock_trylock(result->mutex). If this fails immediately, it checks the next arena with result = result->next. If no arena is available without contention, it will then block and wait for an arena to become free using __libc_lock_lock(result->mutex). Once an arena is successfully acquired, it attaches the arena to the current thread, updates the attached thread counter with ++result->attached_threads, and updates next_to_use = result->next so that the next thread entering the function can start from there. The next_to_use variable is defined as a static function variable: static mstate next_to_use.
static mstate
reused_arena (mstate avoid_arena)
{
mstate result;
/* FIXME: Access to next_to_use suffers from data races. */
static mstate next_to_use;int_malloc takes as input the arena pointer and the amount of bytes requested by the user (without header or memory overhead).
static void *
_int_malloc (mstate av, size_t bytes)
{
INTERNAL_SIZE_T nb; /* normalized request size */
unsigned int idx; /* associated bin index */
.....
nb = checked_request2size (bytes);
if (nb == 0)
{
__set_errno (ENOMEM);
return NULL;
}
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from
mmap. */
if (__glibc_unlikely (av == NULL))
{
void *p = sysmalloc (nb, av);
if (p != NULL)
alloc_perturb (p, bytes);
return p;
}The size, which can not exceed PTRDIFF_MAX is first validated and aligned using checked_request2size which delegates tot the macro request2size for adding the memory overhead + alignment to MALLOC_ALIGNEMENT . If the arena pointer is null, meaning no suitable arena was found, then the allocator falls back to sysmalloc (will be covered later) and returns the memory perturbed with alloc_perturb if configured.
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)
#define MALLOC_ALIGNMENT (2 * SIZE_SZ < __alignof__ (long double) \
? __alignof__ (long double) : 2 * SIZE_SZ)The fast bin index traversal is listed below.
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
{
idx = fastbin_index (nb);
mfastbinptr *fb = &fastbin (av, idx);
mchunkptr pp;
victim = *fb;
if (victim != NULL)
{
if (__glibc_unlikely (misaligned_chunk (victim)))
malloc_printerr ("malloc(): unaligned fastbin chunk detected 2");
if (SINGLE_THREAD_P)
*fb = REVEAL_PTR (victim->fd);
else
REMOVE_FB (fb, pp, victim);
if (__glibc_likely (victim != NULL))
{
size_t victim_idx = fastbin_index (chunksize (victim));
if (__glibc_unlikely (victim_idx != idx))
malloc_printerr ("malloc(): memory corruption (fast)");
check_remalloced_chunk (av, victim, nb); If the requested size qualifies as a fastbin i.e. if ((unsigned long)(nb) <= (unsigned long)(get_max_fast())), the corresponding fastbin index is computed. Next, the memory chunk is validated.
/*
Properties of chunks recycled from fastbins
*/
static void
do_check_remalloced_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T s)
{
INTERNAL_SIZE_T sz = chunksize_nomask (p) & ~(PREV_INUSE | NON_MAIN_ARENA);
if (!chunk_is_mmapped (p))
{
assert (av == arena_for_chunk (p));
if (chunk_main_arena (p))
assert (av == &main_arena);
else
assert (av != &main_arena);
}
do_check_inuse_chunk (av, p);
/* Legal size ... */
assert ((sz & MALLOC_ALIGN_MASK) == 0);
assert ((unsigned long) (sz) >= MINSIZE);
/* ... and alignment */
assert (!misaligned_chunk (p));
/* chunk is less than MINSIZE more than request */
assert ((long) (sz) - (long) (s) >= 0);
assert ((long) (sz) - (long) (s + MINSIZE) < 0);
}Now, even if a chunk is present, it cannot be taken blindly due to the possibility of a race condition. Specifically, if the program is in single threaded mode (checked via the SINGLE_THREAD_P macro), it is safe to update the bin directly by advancing the linked list after revealing the actual pointer (deobfuscating with REVEAL_PTR, we discussed pointer obfuscation earlier):
mfastbinptr *fb = &fastbin (av, idx);
*fb = REVEAL_PTR(victim->fd);
However, if there are several threads in the process, the operation must be done atomically using catomic_compare_and_exchange_val_acq. This ensures the update only occurs if the value we read hasn't changed in the meantime preventing concurrent modification (basically read again pp = REVEAL_PTR (victim->fd);).
do \
{ \
victim = pp; \
if (victim == NULL) \
break; \
pp = REVEAL_PTR (victim->fd); \
if (__glibc_unlikely (pp != NULL && misaligned_chunk (pp))) \
malloc_printerr ("malloc(): unaligned fastbin chunk detected"); \
} \
while ((pp = catomic_compare_and_exchange_val_acq (fb, pp, victim)) \
!= victim);Next, it checks that the size indicated in the chunk is correct with if (__builtin_expect(victim_idx != idx, 0)), meaning it maps to the same index; this is to catch memory corruptions. It then calls check_remalloced_chunk to perform sanity checks. For example, if the chunk is not mmaped, its associated arena (main or heap) is retrieved and compared with the one expected from the function parameters to ensure consistency. The function do_check_inuse_chunk is called to verify properties of in-use chunks (do_check_inuse_chunk(mstate av, mchunkptr p)). The properties of in-use chunks are as follows: first, do_check_chunk validates general chunk properties, i.e., if the chunk is not served by mmap and is not the top chunk, it must have a legal address: assert(((char *)p) >= min_address); and assert(((char *)p + sz) <= ((char *)(av->top)));. If the arena is contiguous (determined by inspecting the arena flag), and the chunk is the top chunk, it must always be at least MINSIZE in size and must have its previous-in-use bit marked: assert(prev_inuse(p));. If the chunk is mmaped, its size must be page-aligned: assert(((prev_size(p) + sz) & (GLRO(dl_pagesize) - 1)) == 0);, and its memory pointer must also be aligned: assert(aligned_OK(chunk2mem(p)));. Additionally, if the arena is contiguous, the legal address check is added: assert(((char *)p) < min_address || ((char *)p) >= max_address); (with top previously initialized, i.e., av->top != initial_top(av)). do_check_inuse_chunk terminates immediately if the chunk is mmap-ed, as mmap-ed chunks have no next/previous linkage. Otherwise, it asserts that the chunk is in use: assert(inuse(p)); (i.e., the next chunk has the PREV_INUSE bit set; fast bins chunks are not consolidated). Once the chunk is validated, surrounding chunks are also validated: the next chunk is fetched with next = next_chunk(p);, and if free, do_check_free_chunk(av, next); is called. Similarly, if next == av->top, assertions check assert(prev_inuse(next)); and assert(chunksize(next) >= MINSIZE);. The previous chunk mchunkptr prv = prev_chunk(p); is also checked: if not in use (if (!prev_inuse(p))), it verifies assert(next_chunk(prv) == p); and calls do_check_free_chunk(av, prv);, which performs similar sanity checks as do_check_chunk to validate general properties: the chunk claims to be free, so confirm assert(!inuse(p));, it is not mmaped assert(!chunk_is_mmapped(p));, size is aligned assert((sz & MALLOC_ALIGN_MASK) == 0);, the user pointer is aligned assert(aligned_OK(chunk2mem(p)));, the footer matches assert(prev_size(next_chunk(p)) == sz);, and the chunk is consolidated, i.e., assert(prev_inuse(p)); (otherwise it would have been merged) and assert(next == av->top || inuse(next)); . Lastly, linked list properties are verified: assert(p->fd->bk == p); and assert(p->bk->fd == p);.
static void
do_check_free_chunk (mstate av, mchunkptr p)
{
INTERNAL_SIZE_T sz = chunksize_nomask (p) & ~(PREV_INUSE | NON_MAIN_ARENA);
mchunkptr next = chunk_at_offset (p, sz);
do_check_chunk (av, p);
/* Chunk must claim to be free ... */
assert (!inuse (p));
assert (!chunk_is_mmapped (p));
/* Unless a special marker, must have OK fields */
if ((unsigned long) (sz) >= MINSIZE)
{
assert ((sz & MALLOC_ALIGN_MASK) == 0);
assert (!misaligned_chunk (p));
/* ... matching footer field */
assert (prev_size (next_chunk (p)) == sz);
/* ... and is fully consolidated */
assert (prev_inuse (p));
assert (next == av->top || inuse (next));
/* ... and has minimally sane links */
assert (p->fd->bk == p);
assert (p->bk->fd == p);
}
else /* markers are always of size SIZE_SZ */
assert (sz == SIZE_SZ);
}Now after do_check_inuse_chunk completes, the following checks are performed: the chunk size, cleared of metadata flags (chunksize_nomask(p) & ~(PREV_INUSE | NON_MAIN_ARENA)), must be properly aligned:
assert((sz & MALLOC_ALIGN_MASK) == 0);
The size must be at least MINSIZE:
assert((unsigned long)(sz) >= MINSIZE);
The chunk size must be greater than or equal to the request size (including overhead):
assert((long)(sz) - (long)(s) >= 0);
and less than the request size plus MINSIZE:
assert((long)(sz) - (long)(s + MINSIZE) < 0);
Once the chunk is validated, and if tcache is enabled (USE_TCACHE), the allocator computes the tcache index (tc_idx) corresponding to the chunk size and stash all bins with same size in the thread-local cache by traversing the bin index i.e linked list improving performance through temporal and spatial locality.
#if USE_TCACHE
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache != NULL && tc_idx < mp_.tcache_small_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */
while (tcache->num_slots[tc_idx] != 0 && (tc_victim = *fb) != NULL)
{
if (__glibc_unlikely (misaligned_chunk (tc_victim)))
malloc_printerr ("malloc(): unaligned fastbin chunk detected 3");
size_t victim_tc_idx = csize2tidx (chunksize (tc_victim));
if (__glibc_unlikely (tc_idx != victim_tc_idx))
malloc_printerr ("malloc(): chunk size mismatch in fastbin");
if (SINGLE_THREAD_P)
*fb = REVEAL_PTR (tc_victim->fd);
else
{
REMOVE_FB (fb, pp, tc_victim);
if (__glibc_unlikely (tc_victim == NULL))
break;
}
tcache_put (tc_victim, tc_idx);
}
}
#endifFinally, allocation completes by returning a pointer to the usable memory i.e. the memory address just after the chunk header void *p = chunk2mem (victim);, with optional perturbation if enabled alloc_perturb (p, bytes);.
Now that we are done with the fastbin lookup, next, let's see what happens during small bin index searching i.e. when in_smallbin_range(size) is true.
if (in_smallbin_range (nb))
{
idx = smallbin_index (nb);
bin = bin_at (av, idx);
if ((victim = last (bin)) != bin)
{
bck = victim->bk;
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): smallbin double linked list corrupted");
set_inuse_bit_at_offset (victim, nb);
bin->bk = bck;
bck->fd = bin;
if (av != &main_arena)
set_non_main_arena (victim);
check_malloced_chunk (av, victim, nb);
#if USE_TCACHE
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache != NULL && tc_idx < mp_.tcache_small_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */
while (tcache->num_slots[tc_idx] != 0
&& (tc_victim = last (bin)) != bin)
{
if (tc_victim != NULL)
{
bck = tc_victim->bk;
set_inuse_bit_at_offset (tc_victim, nb);
if (av != &main_arena)
set_non_main_arena (tc_victim);
bin->bk = bck;
bck->fd = bin;
tcache_put (tc_victim, tc_idx);
}
}
}
#endif
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}We start by mapping the index using smallbin_index(nb). Then we retrieve the corresponding bin bin_at(av, idx); remember, each smallbin has a sentinel node, index i holds the forward pointer (fd), and index i+1 holds the backward pointer (bk). If the bin is not empty (i.e. bin->bk != bin), we get the last chunk: victim = last(bin). Before using the chunk, a sanity check is performed to guard against corruption:
if (__glibc_unlikely(bck->fd != victim)) {
malloc_printerr ("malloc(): smallbin double linked list corrupted");
}
If valid, the chunk is marked as in-use by setting the in-use bit in the metadata set_inuse_bit_at_offset(victim, nb); and set the non-main arena bit if needed set_non_main_arena(victim); Then the double linked list is updated to remove the victim chunk:
bin->bk = bck;
bck->fd = bin;
As with fastbins, do_check_remalloced_chunk is called to validate additional chunk properties (via do_check_malloced_chunk)
If there are other chunks of the same size, they may be stashed in the tcache to improve temporal and spatial locality. Finally, the user receives a pointer to the usable memory, chunk2mem (victim).
As said before, the chunks in fast bin are marked as in_use. malloc_consolidate() basically performs the consolidation of theses chunks i.e for each bin index, it traverse the list and performs backward:
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size in fastbins");
unlink_chunk (av, p);
}
and forward consolidation:
if (nextchunk != av->top) {
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
if (!nextinuse) {
size += nextsize;
unlink_chunk (av, nextchunk);
} else
clear_inuse_bit_at_offset(nextchunk, 0);
first_unsorted = unsorted_bin->fd;
unsorted_bin->fd = p;
first_unsorted->bk = p;
if (!in_smallbin_range (size)) {
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
set_head(p, size | PREV_INUSE);
p->bk = unsorted_bin;
p->fd = first_unsorted;
set_foot(p, size);
}
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
}static void malloc_consolidate(mstate av)
{
mfastbinptr* fb; /* current fastbin being consolidated */
mfastbinptr* maxfb; /* last fastbin (for loop control) */
mchunkptr p; /* current chunk being consolidated */
mchunkptr nextp; /* next chunk to consolidate */
mchunkptr unsorted_bin; /* bin header */
mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */
mchunkptr nextchunk;
INTERNAL_SIZE_T size;
INTERNAL_SIZE_T nextsize;
INTERNAL_SIZE_T prevsize;
int nextinuse;
atomic_store_relaxed (&av->have_fastchunks, false);
unsorted_bin = unsorted_chunks(av);
/*
Remove each chunk from fast bin and consolidate it, placing it
then in unsorted bin. Among other reasons for doing this,
placing in unsorted bin avoids needing to calculate actual bins
until malloc is sure that chunks aren't immediately going to be
reused anyway.
*/
maxfb = &fastbin (av, NFASTBINS - 1);
fb = &fastbin (av, 0);
do {
p = atomic_exchange_acquire (fb, NULL);
if (p != NULL) {
do {
{
if (__glibc_unlikely (misaligned_chunk (p)))
malloc_printerr ("malloc_consolidate(): "
"unaligned fastbin chunk detected");
unsigned int idx = fastbin_index (chunksize (p));
if ((&fastbin (av, idx)) != fb)
malloc_printerr ("malloc_consolidate(): invalid chunk size");
}
check_inuse_chunk(av, p);
nextp = REVEAL_PTR (p->fd);
/* Slightly streamlined version of consolidation code in free() */
size = chunksize (p);
nextchunk = chunk_at_offset(p, size);
nextsize = chunksize(nextchunk);
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size in fastbins");
unlink_chunk (av, p);
}
if (nextchunk != av->top) {
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
if (!nextinuse) {
size += nextsize;
unlink_chunk (av, nextchunk);
} else
clear_inuse_bit_at_offset(nextchunk, 0);
first_unsorted = unsorted_bin->fd;
unsorted_bin->fd = p;
first_unsorted->bk = p;
if (!in_smallbin_range (size)) {
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
set_head(p, size | PREV_INUSE);
p->bk = unsorted_bin;
p->fd = first_unsorted;
set_foot(p, size);
}
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
}
} while ( (p = nextp) != NULL);
}
} while (fb++ != maxfb);
}Note that, as shown above, while fast chunk consolidation happens, the update of the have_fast_chunks must be done atomically (only relaxed as one only need to defeat compiler optimization or reordering as arena is already owned via the mutex and using more aggressive barrier will only incurs unnecessary overhead) i.e atomic_store_relaxed (&av->have_fastchunks, false);.
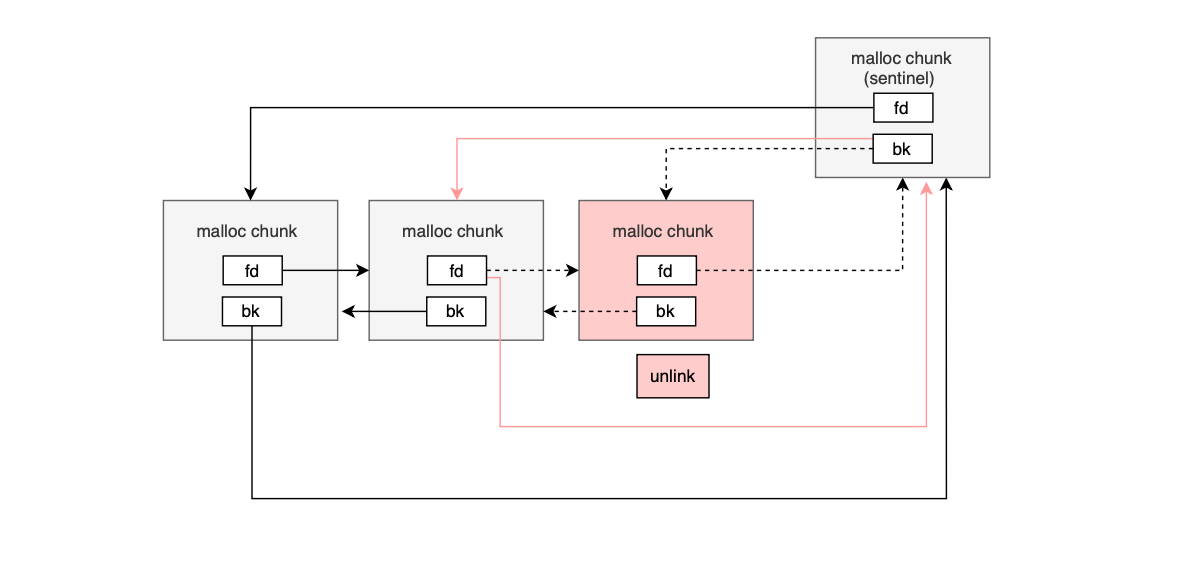
The logic for unlinking a malloc chunk from a free or bin list is listed below.
static void
unlink_chunk (mstate av, mchunkptr p)
{
if (chunksize (p) != prev_size (next_chunk (p)))
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__glibc_unlikely (fd->bk != p || bk->fd != p))
malloc_printerr ("corrupted double-linked list");
fd->bk = bk;
bk->fd = fd;
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
{
if (p->fd_nextsize->bk_nextsize != p
|| p->bk_nextsize->fd_nextsize != p)
malloc_printerr ("corrupted double-linked list (not small)");
if (fd->fd_nextsize == NULL)
{
if (p->fd_nextsize == p)
fd->fd_nextsize = fd->bk_nextsize = fd;
else
{
fd->fd_nextsize = p->fd_nextsize;
fd->bk_nextsize = p->bk_nextsize;
p->fd_nextsize->bk_nextsize = fd;
p->bk_nextsize->fd_nextsize = fd;
}
}
else
{
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
}
}
}Before unliking happens, the size, forward and backward pointers are validated in order to catch memory corruptions if (chunksize (p) != prev_size (next_chunk (p))), __builtin_expect (fd->bk != p || bk->fd != p, 0). Next unlinking is performed i.e fd->bk = bk; bk->fd = fd;. When the chunk belongs to large bin index i.e !in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL, the pointers fd_nextsizeand bk_nextsize must also be updated. Specifically, if the next chunk has the same size we must fill its fd_nextsize/bk_nextsize .
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
{
if (p->fd_nextsize->bk_nextsize != p
|| p->bk_nextsize->fd_nextsize != p)
malloc_printerr ("corrupted double-linked list (not small)");
if (fd->fd_nextsize == NULL)
{
if (p->fd_nextsize == p)
fd->fd_nextsize = fd->bk_nextsize = fd;
else
{
fd->fd_nextsize = p->fd_nextsize;
fd->bk_nextsize = p->bk_nextsize;
p->fd_nextsize->bk_nextsize = fd;
p->bk_nextsize->fd_nextsize = fd;
}
}
else
{
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
}
}
}otherwise we just perform a usual unlinking as depicted below:
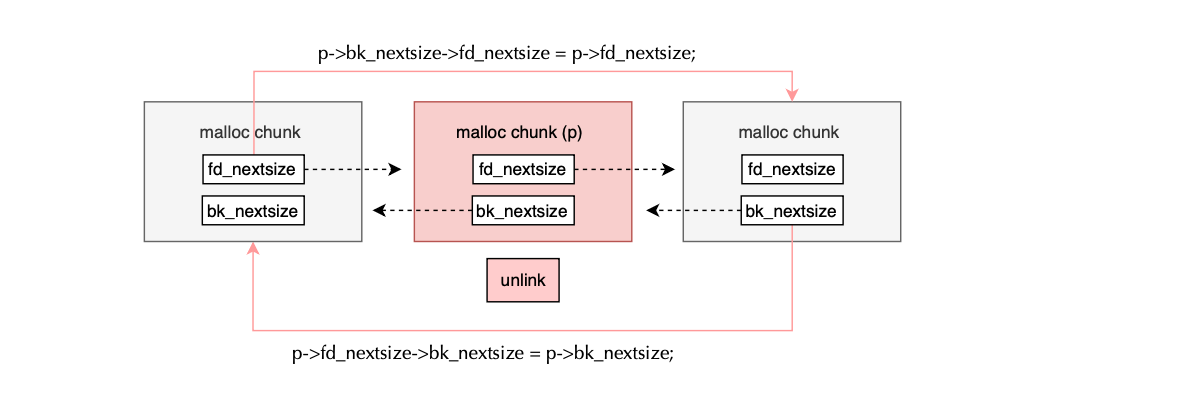
Before inspecting the large bin index (because the request could not be served by the fast, tcache or small bin indexes), consolidation is first triggered via malloc_consolidate(). Naturally, this is only relevant if fast chunks are indexed: atomic_load_relaxed(&av->have_fastchunks) (see the consolidation section for details).
else
{
...
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate (av);
}
This consolidation step processes fast bins, creates potentially augmented chunks, and places them into the unsorted bin (unless chunks are merged with top chunk).
The allocator then traverses the unsorted bin while ((victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) and exercise various integrity checks:
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
{
bck = victim->bk;
size = chunksize (victim);
mchunkptr next = chunk_at_offset (victim, size);
if (__glibc_unlikely (size <= CHUNK_HDR_SZ)
|| __glibc_unlikely (size > av->system_mem))
malloc_printerr ("malloc(): invalid size (unsorted)");
if (__glibc_unlikely (chunksize_nomask (next) < CHUNK_HDR_SZ)
|| __glibc_unlikely (chunksize_nomask (next) > av->system_mem))
malloc_printerr ("malloc(): invalid next size (unsorted)");
if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size))
malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)");
if (__glibc_unlikely (bck->fd != victim)
|| __glibc_unlikely (victim->fd != unsorted_chunks (av)))
malloc_printerr ("malloc(): unsorted double linked list corrupted");
if (__glibc_unlikely (prev_inuse (next)))
malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");Next, if the request is for a small chunk and the only chunk in the unsorted bin is the last remainder, and there would still be space left after split i.e. (unsigned long)(size) > (unsigned long)(nb + MINSIZE) then the allocator splits the chunk, reattaches the remainder to the unsorted bin, update the header set_head (victim, nb | PREV_INUSE |(av != &main_arena ? NON_MAIN_ARENA : 0));. Finally, the chunk is validated check_malloced_chunk() and user pointer memory is returned void *p = chunk2mem(victim);
if (in_smallbin_range (nb) &&
bck == unsorted_chunks (av) &&
victim == av->last_remainder &&
(unsigned long) (size) > (unsigned long) (nb + MINSIZE))
{
/* split and reattach remainder */
remainder_size = size - nb;
remainder = chunk_at_offset (victim, nb);
unsorted_chunks (av)->bk = unsorted_chunks (av)->fd = remainder;
av->last_remainder = remainder;
remainder->bk = remainder->fd = unsorted_chunks (av);
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}If the chunk’s size exactly matches the requested size (size == nb), then the allocator first fills the tcache up to capacity, and only then returns the chunk:void *p = chunk2mem(victim); . If tcache is not enabled, the malloc chunk is returned immediately i.e without going through the tcache.
if (size == nb)
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
#if USE_TCACHE
/* Fill cache first, return to user only if cache fills.
We may return one of these chunks later. */
if (tcache_nb > 0
&& tcache->num_slots[tc_idx] != 0)
{
tcache_put (victim, tc_idx);
return_cached = 1;
continue;
}
else
{
#endif
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
#if USE_TCACHE
}
#endifNow we are in situation where either the unsorted bin contains more than one last reminder bin or the tcache was filled with bin with exact size; the allocator proceeds with placing the bin to the appropriate bin index i.e if the size is for small bin index i.e if (__glibc_unlikely (in_smallbin_range (size))) place the bin in the corresponding small bin:
/* Place chunk in bin. Only malloc_consolidate() and splitting can put
small chunks into the unsorted bin. */
if (__glibc_unlikely (in_smallbin_range (size)))
{
victim_index = smallbin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
}
otherwise place it in large bin index.
else
{
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
/* maintain large bins in sorted order */
if (fwd != bck)
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
if ((unsigned long) (size)
< (unsigned long) chunksize_nomask (bck->bk))
{
fwd = bck;
bck = bck->bk;
if (__glibc_unlikely (fwd->fd->bk_nextsize->fd_nextsize != fwd->fd))
malloc_printerr ("malloc(): largebin double linked list corrupted (nextsize)");
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
else
{
assert (chunk_main_arena (fwd));
while ((unsigned long) size < chunksize_nomask (fwd))
{
fwd = fwd->fd_nextsize;
assert (chunk_main_arena (fwd));
}
if ((unsigned long) size
== (unsigned long) chunksize_nomask (fwd))
/* Always insert in the second position. */
fwd = fwd->fd;
else
{
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd))
malloc_printerr ("malloc(): largebin double linked list corrupted (nextsize)");
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
if (bck->fd != fwd)
malloc_printerr ("malloc(): largebin double linked list corrupted (bk)");
}
}
else
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;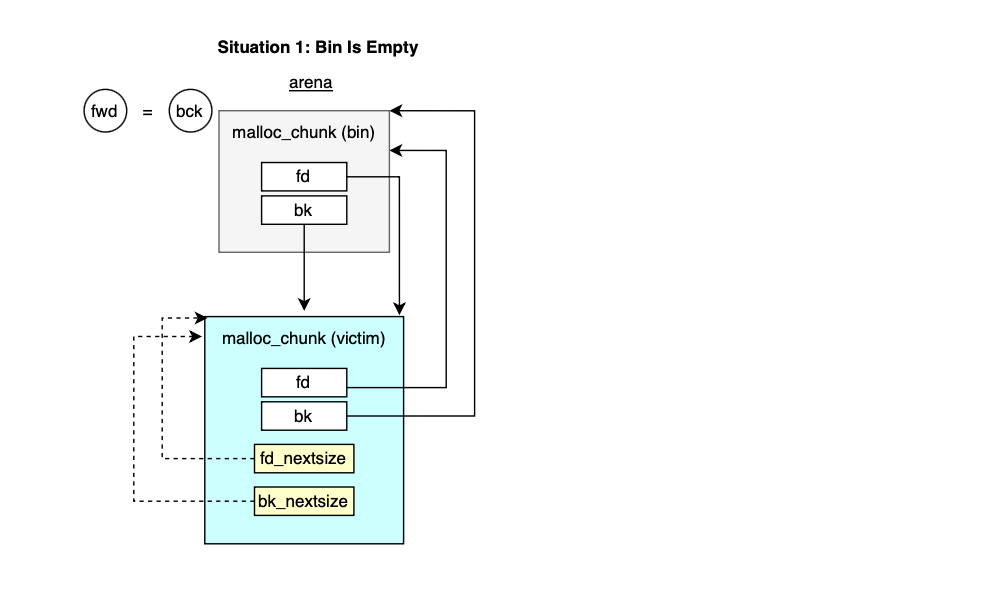
As discussed earlier, two pointers, fd_nextsize and bk_nextsize, are introduced in large bins to maintain indexes in order. The fd_nextsize pointer points to the next smaller chunk, while bk_nextsize points to the next larger chunk.
When a bin needs to be indexed, two situations are possible. Either the chunk is smaller than the current smallest; in this case, the chunk is placed ahead of the current smallest, i.e., next to the sentinel node.
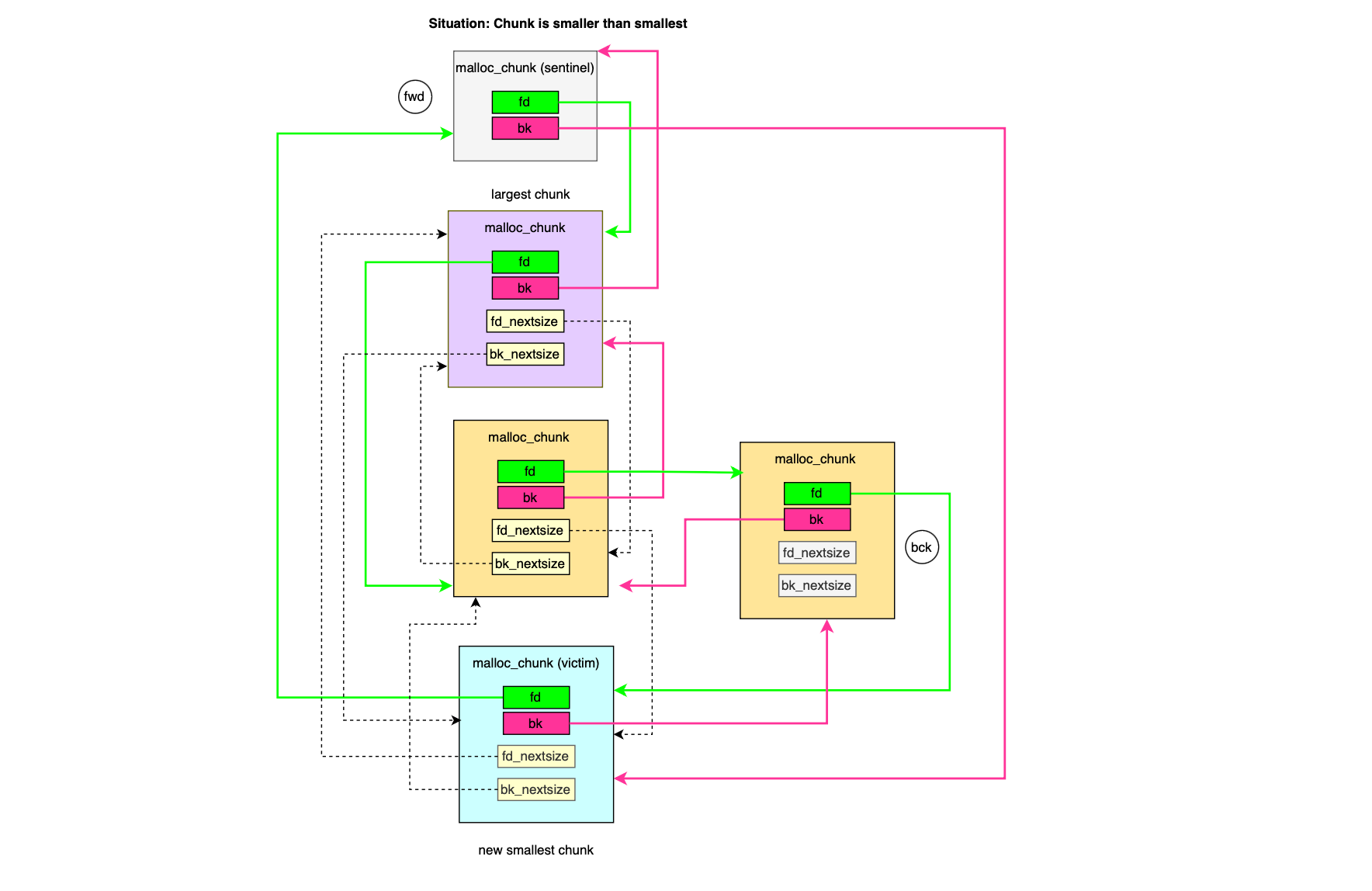
The second scenario consists of traversing the doubly-linked list using fd_nextsize, starting from the largest chunk, until a smaller or equal size is observed. If the traversal stops at a chunk of the same size, the current chunk is inserted in the second position, in this case the fd_nextsizeand bk_nextsize are not filled; as discussed earlier, it would be achieved during unlinking.
if ((unsigned long) size
== (unsigned long) chunksize_nomask (fwd))
/* Always insert in the second position. */
fwd = fwd->fd;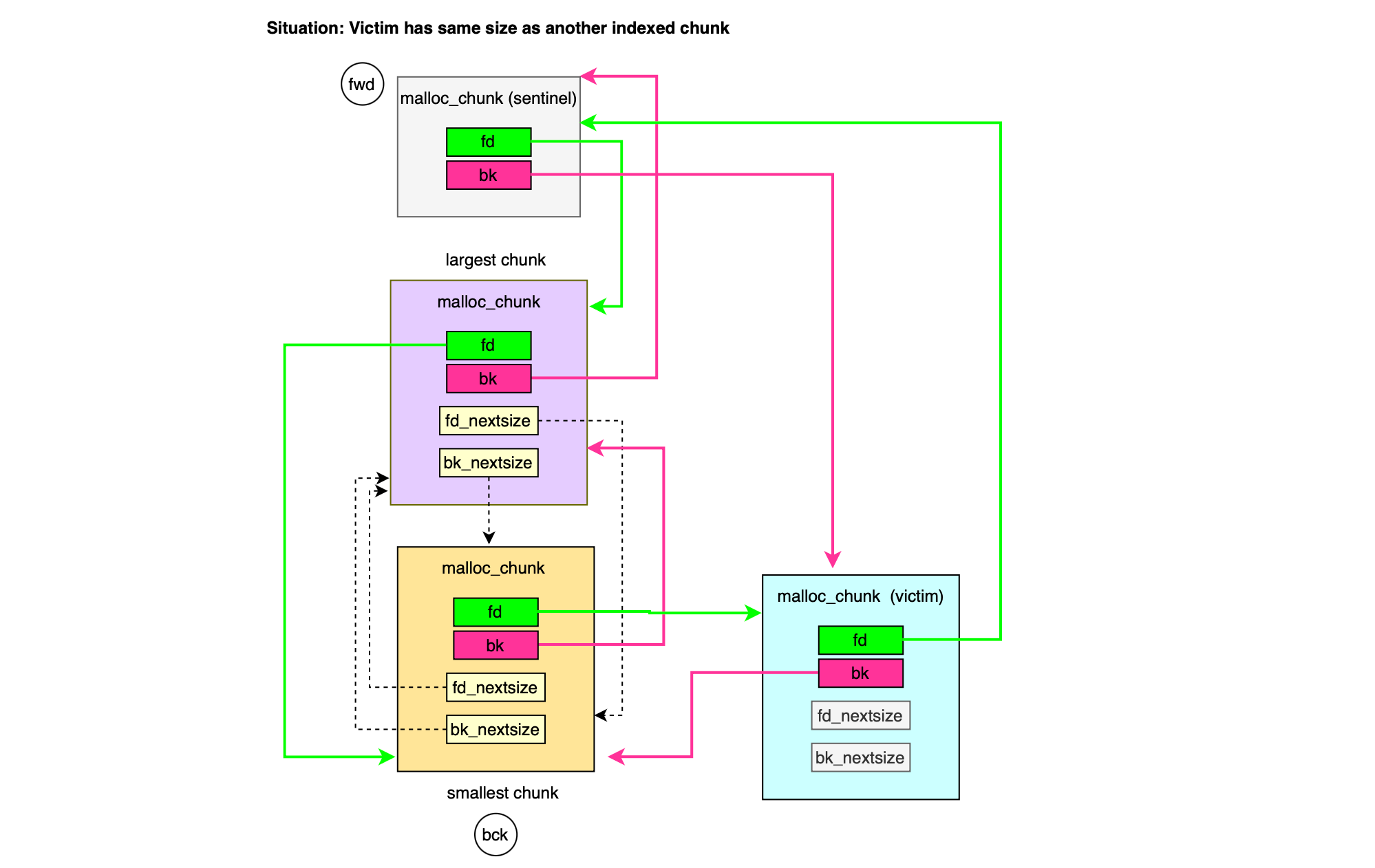
When a bin is indexed, the binmap is always updated mark_bin (av, victim_index); for the associated index.
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;If the allocator have have processed as many chunks as allowed tcache_unsorted_count while filling the cache, return the chunk in the cache:
#if USE_TCACHE
/* If we've processed as many chunks as we're allowed while
filling the cache, return one of the cached ones. */
++tcache_unsorted_count;
if (return_cached
&& mp_.tcache_unsorted_limit > 0
&& tcache_unsorted_count > mp_.tcache_unsorted_limit)
{
return tcache_get (tc_idx);
}
#endifIn summary, if there is only one last remainder chunk in unsorted bin and size is within small bin range and can be split (i.e (unsigned long) (size) > (unsigned long) (nb + MINSIZE))) then split the chunk, update last remainder and return the chunk to user immediatly. Otherwise continue draining the unsorted bin and place the bins in small or large bin index until max iteration is reached; in this case return the cached chunk if any. In the next subsections we discuss how large bin index traversal works (e.g when the unsorted bin traversal did not serve the user request).
Large bins can hold chunks of various size, but each bin is maintained in sorted order. The code is listed below:
if (!in_smallbin_range (nb))
{
bin = bin_at (av, idx);
/* skip scan if empty or largest chunk is too small */
if ((victim = first (bin)) != bin
&& (unsigned long) chunksize_nomask (victim)
>= (unsigned long) (nb))
{
victim = victim->bk_nextsize;
while (((unsigned long) (size = chunksize (victim)) <
(unsigned long) (nb)))
victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip
list does not have to be rerouted. */
if (victim != last (bin)
&& chunksize_nomask (victim)
== chunksize_nomask (victim->fd))
victim = victim->fd;
remainder_size = size - nb;
unlink_chunk (av, victim);
/* Exhaust */
if (remainder_size < MINSIZE)
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
}
/* Split */
else
{
remainder = chunk_at_offset (victim, nb);
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
bck = unsorted_chunks (av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("malloc(): corrupted unsorted chunks");
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
}
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}The allocator begins by computing the bin index and accessing it using bin = bin_at(av, idx); and inspect if the bin is empty or largest chunk is too small (forward from sentinel node is largest) if ((victim= first (bin)) != bin && (unsigned long) chunksize_nomask (victim) >= (unsigned long) (nb)). Next it set the pointer to smallest chunk (largest's bk_nextsize points to smallest) and find the first chunk that is larger or equal the request size (i.e smallest that fit).
victim = victim->bk_nextsize;
while (((unsigned long) (size = chunksize (victim)) <
(unsigned long) (nb)))
victim = victim->bk_nextsize;Next, it unlink the chunk unlink_chunk (av, victim);, check if there is a remainder remainder_size = size - nb;, and if the remainder size is greater than the minimum chunk size (MINSIZE), the allocator splits the chunk and places the remainder back into the unsorted bin (the unlinking code was covered earlier), otherwise if the chunk size exceeds the requested size but the remainder is too small to be useful, it sets the in_use bit set_inuse_bit_at_offset (victim, size); and return the entire chunk to the user i.e the user code receives more memory than requested.
When a memory allocation request still cannot be satisfied, it goes an index further ++idx; i.e starting with next largest bin and searches the smallest chunk that can fit the request.
As covered earlier, malloc maintains an array of bins, each corresponding to different chunk sizes. To track which bins are non-empty efficiently, malloc uses a bitmap represented by 32-bit or 64-bit integers, where each bit corresponds to one bin index.
Given a bin index i, the block integer can be found by dividing the index by the number of bits per map word:
i >> BINMAPSHIFT
Once the block is found, the bit within that block is determined by taking the index modulo the block size:
1U << (i & ((1U << BINMAPSHIFT) - 1))
Setting this bit marks the bin as non-empty; clearing it marks the bin as empty.
#define BINMAPSHIFT 5
#define BITSPERMAP (1U << BINMAPSHIFT) // 2^5 = 32 bins per block
#define BINMAPSIZE (NBINS / BITSPERMAP)
#define idx2block(i) ((i) >> BINMAPSHIFT) // i / 2^5
#define idx2bit(i) ((1U << ((i) & ((1U << BINMAPSHIFT) - 1)))) // i % 32Note that the number of bins, NBINS , is always a multiple of BITSPERMAP (both powers of two) and although 64-bit or 32-bit integers may be used, 32-bit integers are sufficient to represent a bin block.
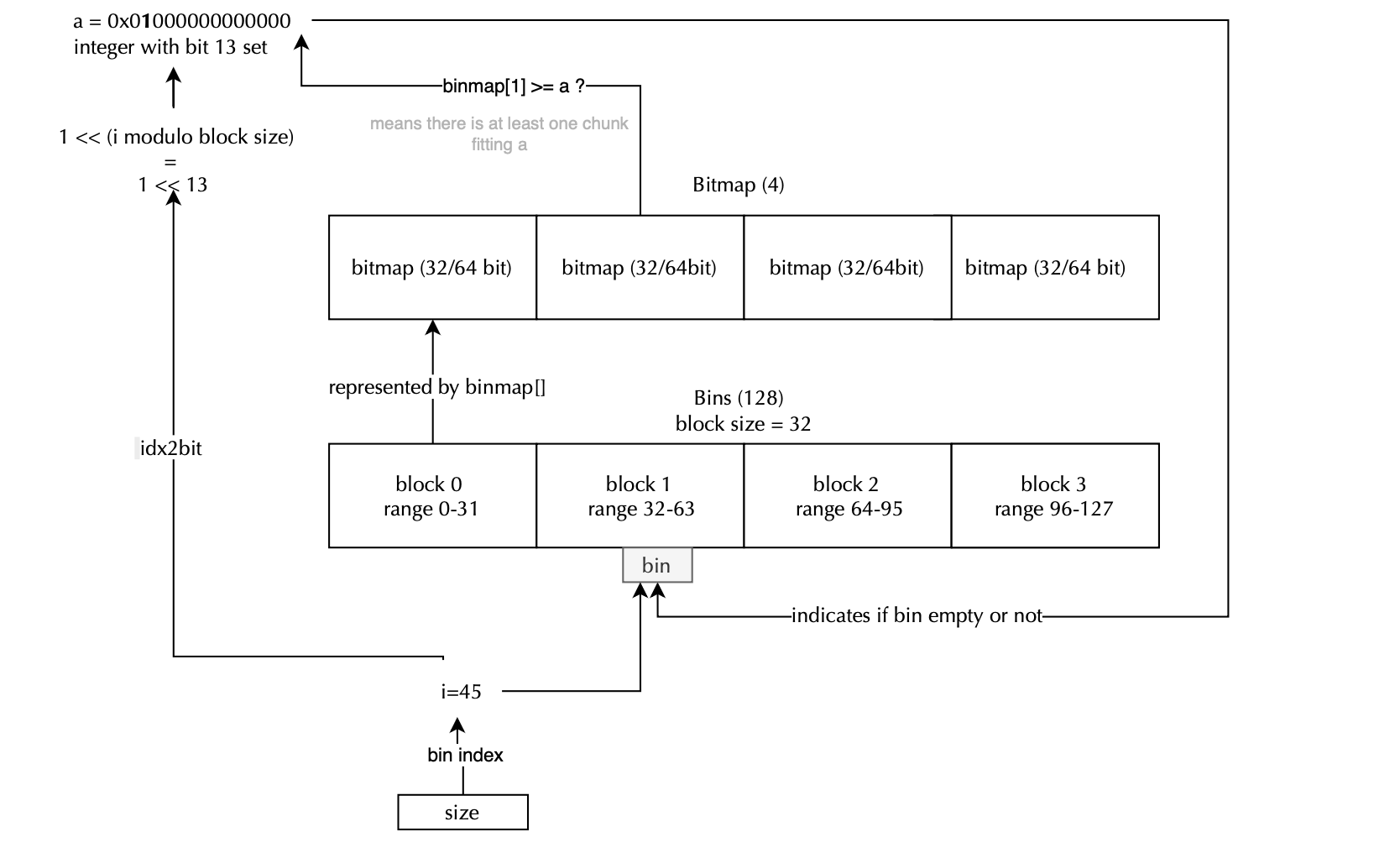
Given a request size, malloc computes the corresponding bin index, which is then used to determine the binmap block and the bit representing that bin:
++idx;
bin = bin_at (av, idx);
block = idx2block (idx);
map = av->binmap[block];
bit = idx2bit (idx);If the current binmap block does not contain any chunk large enough to satisfy the request (i.e., the computed bit is not set or has wrapped around), we advance to the next non-empty block (bit > map means no suitable bin in this block and bit == 0 protects against bit overflow when shifting left repeatedly):
for (;; )
{
/* Skip rest of block if there are no more set bits in this block. */
if (bit > map || bit == 0)
{
do
{
if (++block >= BINMAPSIZE) /* out of bins */
goto use_top;
}
while ((map = av->binmap[block]) == 0);
bin = bin_at (av, (block << BINMAPSHIFT));
bit = 1;
}At this point, we know the block has at least one suitable bin. We then advance both the bin pointer and the bit until we reach the correct bin index:
/* Advance to bin with set bit. There must be one. */
while ((bit & map) == 0)
{
bin = next_bin (bin);
bit <<= 1;
assert (bit != 0);
}
The candidate chunk is taken as the last chunk in the bin victim = last (bin); in large bins it corresponds to the smallest chunk. If the bin turns out to be empty (false alarm), we clear the bit in the binmap and advance again; this also means we need to protect against bit wrapping around which explains the need for the condition || bit == 0 in the beginning of the loop if (bit > map || bit == 0).
if (victim == bin)
{
av->binmap[block] = map &= ~bit; /* Write through */
bin = next_bin (bin);
bit <<= 1;
}If a valid chunk is found, it is split and unlinked from the bin. If the remainder is at least MIN_SIZE, it is inserted into the unsorted bin; otherwise, the user receives slightly more memory than requested.
If no suitable bin is found during bitmap scanning, malloc falls back to using the top chunk, which will be discussed in the next subsection.
Finally, if all bin indexes have been exhausted and no suitable free chunk is found, the allocator attempts to satisfy the request using the top chunk. The top chunk pointer is obtained from the arena victim = av->top;, next, the size is validated against corruption if (__glibc_unlikely (size > av->system_mem)). If the size can satisfy the request and there would be a useful leftover if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE)) then the remainder chunk is set as new top av->top = remainder; and the user gets the pointer to the malloc chunk. Otherwise check again if there are fast chunk available ( if (atomic_load_relaxed(&av->have_fastchunks)) and trigger the malloc consolidation malloc_consolidate (av); if turns out that free chunks were placed, restore the index so that the loop inspect it in the next iteration.
use_top:
/*
If large enough, split off the chunk bordering the end of memory
(held in av->top). Note that this is in accord with the best-fit
search rule. In effect, av->top is treated as larger (and thus
less well fitting) than any other available chunk since it can
be extended to be as large as necessary (up to system
limitations).
We require that av->top always exists (i.e., has size >=
MINSIZE) after initialization, so if it would otherwise be
exhausted by current request, it is replenished. (The main
reason for ensuring it exists is that we may need MINSIZE space
to put in fenceposts in sysmalloc.)
*/
victim = av->top;
size = chunksize (victim);
if (__glibc_unlikely (size > av->system_mem))
malloc_printerr ("malloc(): corrupted top size");
if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE))
{
remainder_size = size - nb;
remainder = chunk_at_offset (victim, nb);
av->top = remainder;
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
/* When we are using atomic ops to free fast chunks we can get
here for all block sizes. */
else if (atomic_load_relaxed (&av->have_fastchunks))
{
malloc_consolidate (av);
/* restore original bin index */
if (in_smallbin_range (nb))
idx = smallbin_index (nb);
else
idx = largebin_index (nb);
}
/*
Otherwise, relay to handle system-dependent cases
*/
else
{
void *p = sysmalloc (nb, av);
if (p != NULL)
alloc_perturb (p, bytes);
return p;
}
}
}Finally last resort is to delegate to sysmalloc(nb, av), which may either extend the heap using sbrk(), or use mmap() for large allocations.
When no chunk can satisfy the request size, the allocator delegates to sysmalloc(nb, av). The routine can grow the heap by either setting the protection flags of the remaining blocks (i.e make them accessible), initialize a new heap and link it to the current one, or expand the heap using the brk system call (in the case of the main arena).
static void *
sysmalloc (INTERNAL_SIZE_T nb, mstate av)
{If the arena pointer is NULL or the request qualifies for mmap (i.e., the request size is above the mmap_threshold and the number of mmaps is still below the allowed maximum), then it delegates to sysmalloc_mmap():
if (av == NULL
|| ((unsigned long) (nb) >= (unsigned long) (mp_.mmap_threshold)
&& (mp_.n_mmaps < mp_.n_mmaps_max)))
{
char *mm;
if (mp_.hp_pagesize > 0 && nb >= mp_.hp_pagesize)
{
/* There is no need to issue the THP madvise call if Huge Pages are
used directly. */
mm = sysmalloc_mmap (nb, mp_.hp_pagesize, mp_.hp_flags, av);
if (mm != MAP_FAILED)
return mm;
}
mm = sysmalloc_mmap (nb, pagesize, 0, av);
if (mm != MAP_FAILED)
return mm;
tried_mmap = true;
}
The chunk obtained via mmap is not be subject to bin indexing. Since mmapped chunks do not have neighboring chunks, they cannot borrow memory from the next chunk as normal heap chunks do.
/* Round up size to nearest page. For mmapped chunks, the overhead is one SIZE_SZ unit larger than for normal chunks, because there is no following chunk whose prev_size field could be used. */
Thus, the allocator adds one word of overhead (SIZE_SZ), and rounds the total up to the nearest page boundary:
if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
size = ALIGN_UP (nb + SIZE_SZ, pagesize);
else
size = ALIGN_UP (nb + SIZE_SZ + MALLOC_ALIGN_MASK, pagesize);As shown above, to guarantee alignment of the user pointer (chunk2mem(mm)), it reserves extra space with MALLOC_ALIGN_MASK. If MALLOC_ALIGNMENT == CHUNK_HDR_SZ, the adjustment is irrelevant, because pagesize is always a multiple of MALLOC_ALIGNMENT.
If correction is needed, the correction is stored in the chunk’s prev_size field:
if (front_misalign > 0)
{
ptrdiff_t correction = MALLOC_ALIGNMENT - front_misalign;
p = (mchunkptr) (mm + correction);
set_prev_size (p, correction);
set_head (p, (size - correction) | IS_MMAPPED);
}
else
{
p = (mchunkptr) mm;
set_prev_size (p, 0);
set_head (p, size | IS_MMAPPED);
}
/* update statistics */
int new = atomic_fetch_add_relaxed (&mp_.n_mmaps, 1) + 1;
atomic_max (&mp_.max_n_mmaps, new);
unsigned long sum;
sum = atomic_fetch_add_relaxed (&mp_.mmapped_mem, size) + size;
atomic_max (&mp_.max_mmapped_mem, sum);
check_chunk (av, p);
return chunk2mem (p);
}If mmap is not applicable, the allocator attempts to grow the top chunk. Some sanity checks are performed:
old_top = av->top;
old_size = chunksize (old_top);
old_end = (char *) (chunk_at_offset (old_top, old_size));
brk = snd_brk = (char *) (MORECORE_FAILURE);
/*
If not the first time through, we require old_size to be
at least MINSIZE and to have prev_inuse set.
*/
assert ((old_top == initial_top (av) && old_size == 0) ||
((unsigned long) (old_size) >= MINSIZE &&
prev_inuse (old_top) &&
((unsigned long) old_end & (pagesize - 1)) == 0));
/* Precondition: not enough current space to satisfy nb request */
assert ((unsigned long) (old_size) < (unsigned long) (nb + MINSIZE));
If this is the first time then old size should be equal to 0 (old_top == initial_top (av) && old_size == 0), otherwise old top size should be at least MINSIZE, top chunk should have previous in use bit set, and the end address should be page aligned ((unsigned long) (old_size) >= MINSIZE && prev_inuse (old_top) && ((unsigned long) old_end & (pagesize - 1)) == 0)). Additionally the top size should not be able to serve the request otherwise we wouldn't be here assert ((unsigned long) (old_size) < (unsigned long) (nb + MINSIZE));.
For non-main arenas, the allocator tries to extend the current heap by MINSIZE + nb - old_size i.e grow_heap (old_heap, MINSIZE + nb - old_size):
if (av != &main_arena)
{
heap_info *old_heap, *heap;
size_t old_heap_size;
/* First try to extend the current heap. */
old_heap = heap_for_ptr (old_top);
old_heap_size = old_heap->size;
if ((long) (MINSIZE + nb - old_size) > 0
&& grow_heap (old_heap, MINSIZE + nb - old_size) == 0)
{
av->system_mem += old_heap->size - old_heap_size;
set_head (old_top, (((char *) old_heap + old_heap->size) - (char *) old_top)
| PREV_INUSE);
}
else if ((heap = new_heap (nb + (MINSIZE + sizeof (*heap)), mp_.top_pad)))
{
/* Use a newly allocated heap. */
heap->ar_ptr = av;
heap->prev = old_heap;
av->system_mem += heap->size;
/* Set up the new top. */
top (av) = chunk_at_offset (heap, sizeof (*heap));
set_head (top (av), (heap->size - sizeof (*heap)) | PREV_INUSE);
/* Setup fencepost and free the old top chunk with a multiple of
MALLOC_ALIGNMENT in size. */
/* The fencepost takes at least MINSIZE bytes, because it might
become the top chunk again later. Note that a footer is set
up, too, although the chunk is marked in use. */
old_size = (old_size - MINSIZE) & ~MALLOC_ALIGN_MASK;
set_head (chunk_at_offset (old_top, old_size + CHUNK_HDR_SZ),
0 | PREV_INUSE);
if (old_size >= MINSIZE)
{
set_head (chunk_at_offset (old_top, old_size),
CHUNK_HDR_SZ | PREV_INUSE);
set_foot (chunk_at_offset (old_top, old_size), CHUNK_HDR_SZ);
set_head (old_top, old_size | PREV_INUSE | NON_MAIN_ARENA);
_int_free_chunk (av, old_top, chunksize (old_top), 1);
}
else
{
set_head (old_top, (old_size + CHUNK_HDR_SZ) | PREV_INUSE);
set_foot (old_top, (old_size + CHUNK_HDR_SZ));
}
}
else if (!tried_mmap)
{
/* We can at least try to use to mmap memory. If new_heap fails
it is unlikely that trying to allocate huge pages will
succeed. */
char *mm = sysmalloc_mmap (nb, pagesize, 0, av);
if (mm != MAP_FAILED)
return mm;
}
}grow_heap will align the requested size to a page boundary, then check it does not exceed the arena’s heap_max_size() and finally use __mprotect to lazily map new physical pages into the existing virtual address space. If growth is not possible, a new heap is created with new_heap().
static int
grow_heap (heap_info *h, long diff)
{
size_t pagesize = h->pagesize;
size_t max_size = heap_max_size ();
long new_size;
diff = ALIGN_UP (diff, pagesize);
new_size = (long) h->size + diff;
if ((unsigned long) new_size > (unsigned long) max_size)
return -1;
if ((unsigned long) new_size > h->mprotect_size)
{
if (__mprotect ((char *) h + h->mprotect_size,
(unsigned long) new_size - h->mprotect_size,
mtag_mmap_flags | PROT_READ | PROT_WRITE) != 0)
return -2;
h->mprotect_size = new_size;
}
h->size = new_size;
LIBC_PROBE (memory_heap_more, 2, h, h->size);
return 0;
}Basically, the routine updates the arena pointer (heap->ar_ptr = av), links the previous heap (heap->prev = old_heap), increments the arena size (av->system_mem += heap->size), and resets the top chunk (top(av) = chunk_at_offset(heap, sizeof(*heap)), set_head(top(av), (heap->size - sizeof(*heap)) | PREV_INUSE)). To prevent malloc from merging across heap boundaries, a fencepost is placed at the end of the old heap: the old size is reduced (old_size = (old_size - MINSIZE) & ~MALLOC_ALIGN_MASK), and a dummy chunk with size 0 and PREV_INUSE set is placed at old_top + old_size + CHUNK_HDR_SZ. When malloc encounters such a chunk, it recognizes it as a fencepost (size is 0) and avoids merging. After this, if the remaining old size is at leastMINSIZE, a real free chunk is created at old_top and indexed into the bins via _int_free_chunk(av, old_top, chunksize(old_top), 1); otherwise, the old top is simply kept as one last chunk with its header updated. This allows the allocator to reuse the old top by splitting it into a fencepost and, if possible, a usable free chunk. Calling _int_free_chunk ensures that the free chunk is immediately inserted into the bins and discoverable by future allocations, without it, the chunk would remain idle until a later consolidation pass.
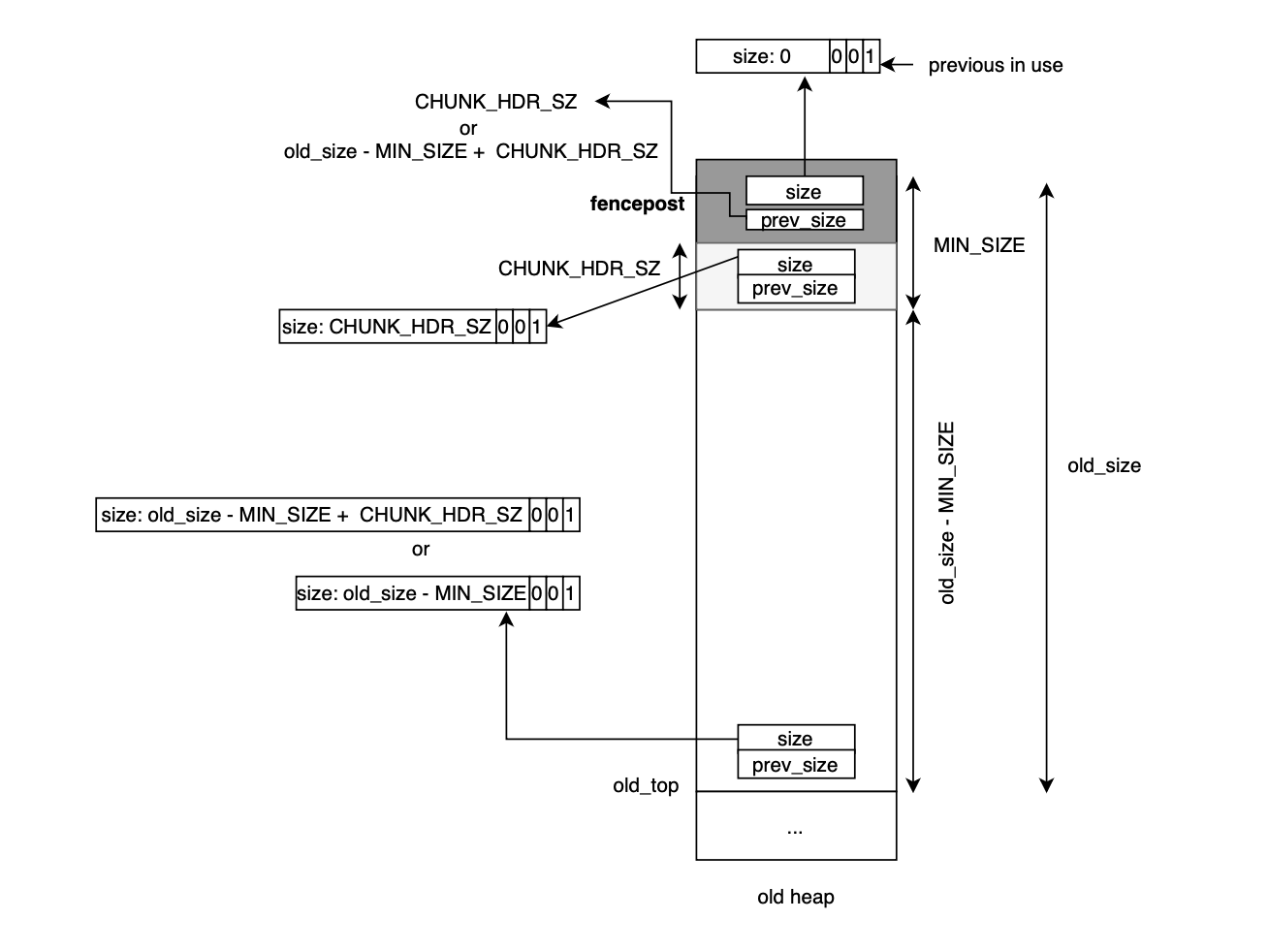
If the arena is the main arena, the requested size is first increased to include padding and overhead (nb + mp_.top_pad + MINSIZE),
{ /* Request enough space for nb + pad + overhead */
size = nb + mp_.top_pad + MINSIZE;
/*
If contiguous, we can subtract out existing space that we hope to
combine with new space. We add it back later only if
we don't actually get contiguous space.
*/
if (contiguous (av))
size -= old_size;
/*
Round to a multiple of page size or huge page size.
If MORECORE is not contiguous, this ensures that we only call it
with whole-page arguments. And if MORECORE is contiguous and
this is not first time through, this preserves page-alignment of
previous calls. Otherwise, we correct to page-align below.
*/and if the heap is contiguous, the old top size is subtracted since it will later be merged; the result is page-aligned and MORECORE(size) (sbrk) is tried,
if (size > 0)
{
brk = (char *) (MORECORE (size));
if (brk != (char *) (MORECORE_FAILURE))
madvise_thp (brk, size);
LIBC_PROBE (memory_sbrk_more, 2, brk, size);
}If sbrk fails, the allocator falls back to mmap via sysmalloc_mmap_fallback, marking the arena non-contiguous.
if (brk == (char *) (MORECORE_FAILURE))
{
/*
If have mmap, try using it as a backup when MORECORE fails or
cannot be used. This is worth doing on systems that have "holes" in
address space, so sbrk cannot extend to give contiguous space, but
space is available elsewhere. Note that we ignore mmap max count
and threshold limits, since the space will not be used as a
segregated mmap region.
*/
char *mbrk = MAP_FAILED;
if (mp_.hp_pagesize > 0)
mbrk = sysmalloc_mmap_fallback (&size, nb, old_size,
mp_.hp_pagesize, mp_.hp_pagesize,
mp_.hp_flags, av);
if (mbrk == MAP_FAILED)
mbrk = sysmalloc_mmap_fallback (&size, nb, old_size, MMAP_AS_MORECORE_SIZE,
pagesize, 0, av);
if (mbrk != MAP_FAILED)
{
/* We do not need, and cannot use, another sbrk call to find end */
brk = mbrk;
snd_brk = brk + size;
}
}
...
static void *
sysmalloc_mmap_fallback (long int *s, INTERNAL_SIZE_T nb,
INTERNAL_SIZE_T old_size, size_t minsize,
size_t pagesize, int extra_flags, mstate av)
{
long int size = *s;
/* Cannot merge with old top, so add its size back in */
if (contiguous (av))
size = ALIGN_UP (size + old_size, pagesize);
/* If we are relying on mmap as backup, then use larger units */
if ((unsigned long) (size) < minsize)
size = minsize;
/* Don't try if size wraps around 0 */
if ((unsigned long) (size) <= (unsigned long) (nb))
return MORECORE_FAILURE;
char *mbrk = (char *) (MMAP (NULL, size,
mtag_mmap_flags | PROT_READ | PROT_WRITE,
extra_flags));
if (mbrk == MAP_FAILED)
return MAP_FAILED;
#ifdef MAP_HUGETLB
if (!(extra_flags & MAP_HUGETLB))
madvise_thp (mbrk, size);
#endif
__set_vma_name (mbrk, size, " glibc: malloc");
/* Record that we no longer have a contiguous sbrk region. After the first
time mmap is used as backup, we do not ever rely on contiguous space
since this could incorrectly bridge regions. */
set_noncontiguous (av);
*s = size;
return mbrk;
}Once the memory is obtained, av->system_mem is updated:
if (brk != (char *) (MORECORE_FAILURE))
{
if (mp_.sbrk_base == NULL)
mp_.sbrk_base = brk;
av->system_mem += size;
and if the new space is contiguous with the old heap, the top chunk is extended,
if (brk == old_end && snd_brk == (char *) (MORECORE_FAILURE))
set_head (old_top, (size + old_size) | PREV_INUSE);while if brk > old_end (e.g., from a foreign sbrk) a correction is then computed to align the user pointer (chunk2mem(brk)), possibly requiring a second MORECORE call (adding back old_size in the non-contiguous case):
else
{
front_misalign = 0;
end_misalign = 0;
correction = 0;
aligned_brk = brk;
/* handle contiguous cases */
if (contiguous (av))
{
/* Count foreign sbrk as system_mem. */
if (old_size)
av->system_mem += brk - old_end;
/* Guarantee alignment of first new chunk made from this space */
front_misalign = (INTERNAL_SIZE_T) chunk2mem (brk) & MALLOC_ALIGN_MASK;
if (front_misalign > 0)
{
/*
Skip over some bytes to arrive at an aligned position.
We don't need to specially mark these wasted front bytes.
They will never be accessed anyway because
prev_inuse of av->top (and any chunk created from its start)
is always true after initialization.
*/
correction = MALLOC_ALIGNMENT - front_misalign;
aligned_brk += correction;
}
/*
If this isn't adjacent to existing space, then we will not
be able to merge with old_top space, so must add to 2nd request.
*/
correction += old_size;
/* Extend the end address to hit a page boundary */
end_misalign = (INTERNAL_SIZE_T) (brk + size + correction);
correction += (ALIGN_UP (end_misalign, pagesize)) - end_misalign;
assert (correction >= 0);
snd_brk = (char *) (MORECORE (correction));
/*
If can't allocate correction, try to at least find out current
brk. It might be enough to proceed without failing.
Note that if second sbrk did NOT fail, we assume that space
is contiguous with first sbrk. This is a safe assumption unless
program is multithreaded but doesn't use locks and a foreign sbrk
occurred between our first and second calls.
*/
if (snd_brk == (char *) (MORECORE_FAILURE))
{
correction = 0;
snd_brk = (char *) (MORECORE (0));
}
else
madvise_thp (snd_brk, correction);
}
/* handle non-contiguous cases */
else
{
if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
/* MORECORE/mmap must correctly align */
assert (((unsigned long) chunk2mem (brk) & MALLOC_ALIGN_MASK) == 0);
else
{
front_misalign = (INTERNAL_SIZE_T) chunk2mem (brk) & MALLOC_ALIGN_MASK;
if (front_misalign > 0)
{
/*
Skip over some bytes to arrive at an aligned position.
We don't need to specially mark these wasted front bytes.
They will never be accessed anyway because
prev_inuse of av->top (and any chunk created from its start)
is always true after initialization.
*/
aligned_brk += MALLOC_ALIGNMENT - front_misalign;
}
}
/* Find out current end of memory */
if (snd_brk == (char *) (MORECORE_FAILURE))
{
snd_brk = (char *) (MORECORE (0));
}
}
and finally the new top is set to the aligned address with its size updated via set_head(av->top, (snd_brk - aligned_brk + correction) | PREV_INUSE), increasing system_mem further if alignment correction was applied; in the non-contiguous case, two fencepost chunks may are placed to prevent accidental merging with memory regions we no longer control, as explained earlier.
if (snd_brk != (char *) (MORECORE_FAILURE))
{
av->top = (mchunkptr) aligned_brk;
set_head (av->top, (snd_brk - aligned_brk + correction) | PREV_INUSE);
av->system_mem += correction;
/*
If not the first time through, we either have a
gap due to foreign sbrk or a non-contiguous region. Insert a
double fencepost at old_top to prevent consolidation with space
we don't own. These fenceposts are artificial chunks that are
marked as inuse and are in any case too small to use. We need
two to make sizes and alignments work out.
*/
if (old_size != 0)
{
/*
Shrink old_top to insert fenceposts, keeping size a
multiple of MALLOC_ALIGNMENT. We know there is at least
enough space in old_top to do this.
*/
old_size = (old_size - 2 * CHUNK_HDR_SZ) & ~MALLOC_ALIGN_MASK;
set_head (old_top, old_size | PREV_INUSE);
/*
Note that the following assignments completely overwrite
old_top when old_size was previously MINSIZE. This is
intentional. We need the fencepost, even if old_top otherwise gets
lost.
*/
set_head (chunk_at_offset (old_top, old_size),
CHUNK_HDR_SZ | PREV_INUSE);
set_head (chunk_at_offset (old_top,
old_size + CHUNK_HDR_SZ),
CHUNK_HDR_SZ | PREV_INUSE);
/* If possible, release the rest. */
if (old_size >= MINSIZE)
{
_int_free_chunk (av, old_top, chunksize (old_top), 1);
}
}
}
}
}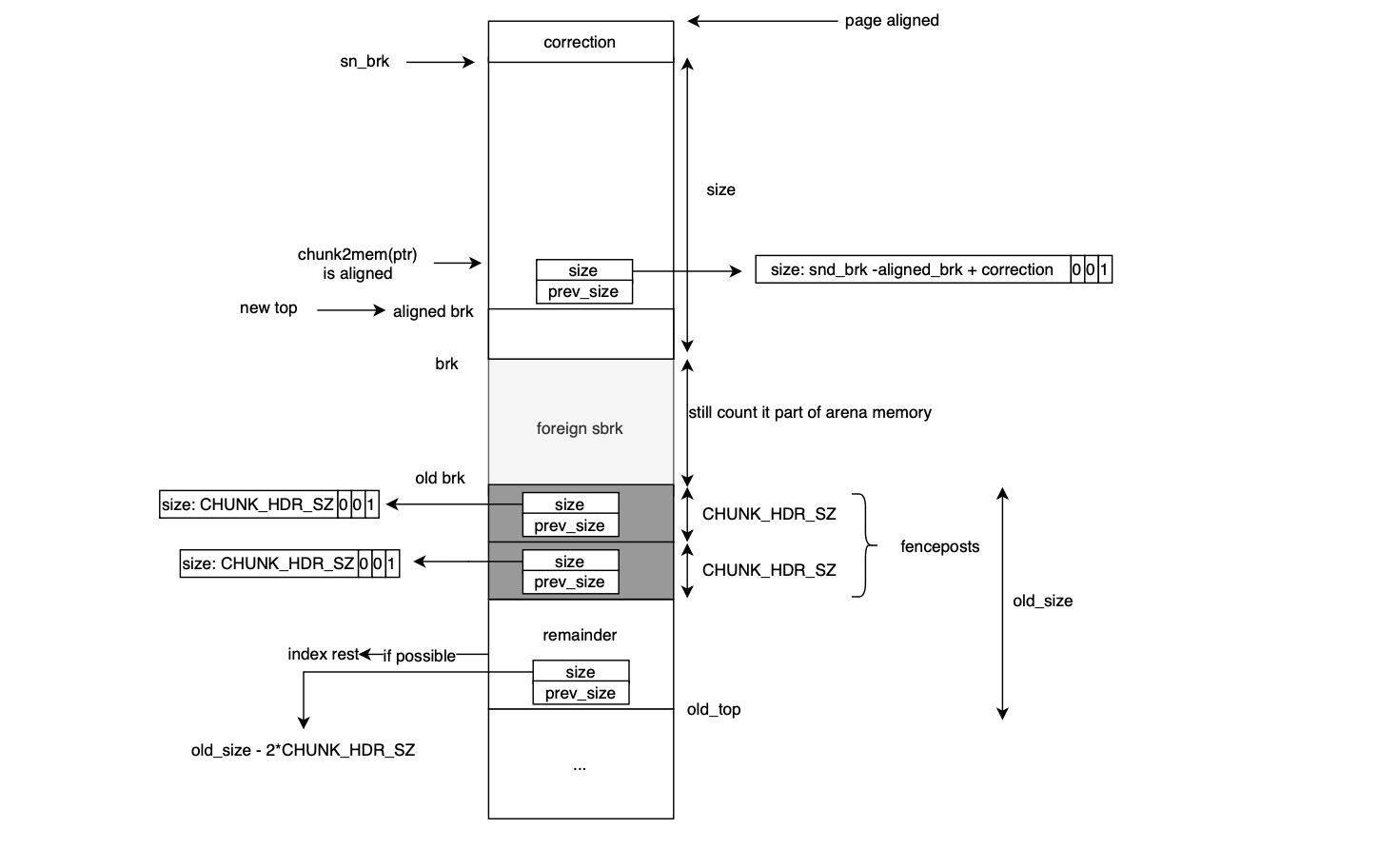
Finally, the top chunk of the arena is updated and split to satisfy the allocation, and the user pointer is returned.
if ((unsigned long) av->system_mem > (unsigned long) (av->max_system_mem))
av->max_system_mem = av->system_mem;
check_malloc_state (av);
/* finally, do the allocation */
p = av->top;
size = chunksize (p);
/* check that one of the above allocation paths succeeded */
if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE))
{
remainder_size = size - nb;
remainder = chunk_at_offset (p, nb);
av->top = remainder;
set_head (p, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
check_malloced_chunk (av, p, nb);
return chunk2mem (p);
}
/* catch all failure paths */
__set_errno (ENOMEM);
return NULL;
}The core function responsible for memory deallocation in glibc is __libc_free(). As shown below, in order to detect double free defects, the cpu is instructed to read from tagged memory at the address housed in the pointer mem, assuming memory tagging is supported and enabled. Specifically, *(volatile char *)mem forces the hardware to load one byte from memory into a register, volatile is a qualifier ensuring the compiler does not optimize the read away. In Memory Tagging or MT, memory is divided into fixed-size granules (e.g 16 bytes), and each granule is associated with a memory tag stored separately in memory managed by the hardware, in a way that is not visible or directly accessible to user. The pointer value itself (i.e., the virtual address) includes a tag in its high order bits (e.g 4 bits). During a memory access, the hardware or cpu compares the pointer tag against the memory tag of the addressed granule. If the tags do not match, a fault is triggered (alerting mode can be sync or async).
void
__libc_free (void *mem)
{
mchunkptr p; /* chunk corresponding to mem */
if (mem == NULL) /* free(0) has no effect */
return;
/* Quickly check that the freed pointer matches the tag for the memory.
This gives a useful double-free detection. */
if (__glibc_unlikely (mtag_enabled))
*(volatile char *)mem;
p = mem2chunk (mem);
/* Mark the chunk as belonging to the library again. */
tag_region (chunk2mem (p), memsize (p));
INTERNAL_SIZE_T size = chunksize (p);
if (__glibc_unlikely (misaligned_chunk (p)))
return malloc_printerr_tail ("free(): invalid pointer");
check_inuse_chunk (arena_for_chunk (p), p);
#if USE_TCACHE
if (__glibc_likely (size < mp_.tcache_max_bytes && tcache != NULL))
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* Check for double free - verify if the key matches. */
if (__glibc_unlikely (e->key == tcache_key))
return tcache_double_free_verify (e);
size_t tc_idx = csize2tidx (size);
if (__glibc_likely (tc_idx < TCACHE_SMALL_BINS))
{
if (__glibc_likely (tcache->num_slots[tc_idx] != 0))
return tcache_put (p, tc_idx);
}
else
{
tc_idx = large_csize2tidx (size);
if (size >= MINSIZE
&& !chunk_is_mmapped (p)
&& __glibc_likely (tcache->num_slots[tc_idx] != 0))
return tcache_put_large (p, tc_idx);
}
}
#endif
/* Check size >= MINSIZE and p + size does not overflow. */
if (__glibc_unlikely (__builtin_add_overflow_p ((uintptr_t) p, size - MINSIZE,
(uintptr_t) 0)))
return malloc_printerr_tail ("free(): invalid size");
_int_free_chunk (arena_for_chunk (p), p, size, 0);
}
In the above listing, __libc_mtag_tag_region(), applies a memory tag to a region of memory; it will issue stg/stg2 instructions behind the scene; stg is an instruction that writes a memory tag to the tag storage associated with a virtual memory address.
The chunk is then checked next for misalignment and coherence of metadata:
if (__glibc_unlikely (misaligned_chunk (p)))
return malloc_printerr_tail ("free(): invalid pointer");
check_inuse_chunk (arena_for_chunk (p), p);Once the chunk is validated, it will be indexed in tcache if possible/enabled. The memory allocator will also verify that chunk is not already indexed by inspecting the tcache_key; if the key matches, then it delegates to tcache_double_free_verify().
#if USE_TCACHE
if (__glibc_likely (size < mp_.tcache_max_bytes && tcache != NULL))
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* Check for double free - verify if the key matches. */
if (__glibc_unlikely (e->key == tcache_key))
return tcache_double_free_verify (e);
size_t tc_idx = csize2tidx (size);
if (__glibc_likely (tc_idx < TCACHE_SMALL_BINS))
{
if (__glibc_likely (tcache->num_slots[tc_idx] != 0))
return tcache_put (p, tc_idx);
}
else
{
tc_idx = large_csize2tidx (size);
if (size >= MINSIZE
&& !chunk_is_mmapped (p)
&& __glibc_likely (tcache->num_slots[tc_idx] != 0))
return tcache_put_large (p, tc_idx);
}
}
#endifThe routine additionally checks that the size does not overflow to detect invalid frees:
/* Check size >= MINSIZE and p + size does not overflow. */
if (__glibc_unlikely (__builtin_add_overflow_p ((uintptr_t) p, size - MINSIZE,
(uintptr_t) 0)))
return malloc_printerr_tail ("free(): invalid size");Next, the control is delegated to _int_free_chunk().
Chunks eligible for fast bin indexing are indexed immediately (placed at the head of the list i.e LIFO):
static void
_int_free_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size, int have_lock)
{
mfastbinptr *fb; /* associated fastbin */
/*
If eligible, place chunk on a fastbin so it can be found
and used quickly in malloc.
*/
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
#if TRIM_FASTBINS
/*
If TRIM_FASTBINS set, don't place chunks
bordering top into fastbins
*/
&& (chunk_at_offset(p, size) != av->top)
#endif
) {
if (__glibc_unlikely (
chunksize_nomask (chunk_at_offset(p, size)) <= CHUNK_HDR_SZ
|| chunksize (chunk_at_offset(p, size)) >= av->system_mem))
{
bool fail = true;
/* We might not have a lock at this point and concurrent modifications
of system_mem might result in a false positive. Redo the test after
getting the lock. */
if (!have_lock)
{
__libc_lock_lock (av->mutex);
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
__libc_lock_unlock (av->mutex);
}
if (fail)
malloc_printerr ("free(): invalid next size (fast)");
}
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
atomic_store_relaxed (&av->have_fastchunks, true);
unsigned int idx = fastbin_index(size);
fb = &fastbin (av, idx);
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
mchunkptr old = *fb, old2;
if (SINGLE_THREAD_P)
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__glibc_unlikely (old == p))
malloc_printerr ("double free or corruption (fasttop)");
p->fd = PROTECT_PTR (&p->fd, old);
*fb = p;
}
else
do
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__glibc_unlikely (old == p))
malloc_printerr ("double free or corruption (fasttop)");
old2 = old;
p->fd = PROTECT_PTR (&p->fd, old);
}
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
!= old2);
/* Check that size of fastbin chunk at the top is the same as
size of the chunk that we are adding. We can dereference OLD
only if we have the lock, otherwise it might have already been
allocated again. */
if (have_lock && old != NULL
&& __glibc_unlikely (fastbin_index (chunksize (old)) != idx))
malloc_printerr ("invalid fastbin entry (free)");
}mmaped chunks are released using munmap_chunk() which calls munmap behind the scene:
else {
/* Preserve errno in case munmap sets it. */
int err = errno;
/* See if the dynamic brk/mmap threshold needs adjusting.
Dumped fake mmapped chunks do not affect the threshold. */
if (!mp_.no_dyn_threshold
&& chunksize_nomask (p) > mp_.mmap_threshold
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX)
{
mp_.mmap_threshold = chunksize (p);
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
mp_.mmap_threshold, mp_.trim_threshold);
}
munmap_chunk (p);
__set_errno (err);
}
...
static void
munmap_chunk (mchunkptr p)
{
size_t pagesize = GLRO (dl_pagesize);
INTERNAL_SIZE_T size = chunksize (p);
assert (chunk_is_mmapped (p));
uintptr_t mem = (uintptr_t) chunk2mem (p);
uintptr_t block = (uintptr_t) p - prev_size (p);
size_t total_size = prev_size (p) + size;
/* Unfortunately we have to do the compilers job by hand here. Normally
we would test BLOCK and TOTAL-SIZE separately for compliance with the
page size. But gcc does not recognize the optimization possibility
(in the moment at least) so we combine the two values into one before
the bit test. */
if (__glibc_unlikely ((block | total_size) & (pagesize - 1)) != 0
|| __glibc_unlikely (!powerof2 (mem & (pagesize - 1))))
malloc_printerr ("munmap_chunk(): invalid pointer");
atomic_fetch_add_relaxed (&mp_.n_mmaps, -1);
atomic_fetch_add_relaxed (&mp_.mmapped_mem, -total_size);
/* If munmap failed the process virtual memory address space is in a
bad shape. Just leave the block hanging around, the process will
terminate shortly anyway since not much can be done. */
__munmap ((char *) block, total_size);
}And finally, other chunks are consolidated backward and forward:
else if (!chunk_is_mmapped(p)) {
/* Preserve errno in case block merging results in munmap. */
int err = errno;
/* If we're single-threaded, don't lock the arena. */
if (SINGLE_THREAD_P)
have_lock = true;
if (!have_lock)
__libc_lock_lock (av->mutex);
_int_free_merge_chunk (av, p, size);
if (!have_lock)
__libc_lock_unlock (av->mutex);
__set_errno (err);
}
...
static void
_int_free_merge_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size)
{
mchunkptr nextchunk = chunk_at_offset(p, size);
/* Lightweight tests: check whether the block is already the
top block. */
if (__glibc_unlikely (p == av->top))
malloc_printerr ("double free or corruption (top)");
/* Or whether the next chunk is beyond the boundaries of the arena. */
if (__glibc_unlikely (contiguous (av)
&& (char *) nextchunk
>= ((char *) av->top + chunksize(av->top))))
malloc_printerr ("double free or corruption (out)");
/* Or whether the block is actually not marked used. */
if (__glibc_unlikely (!prev_inuse(nextchunk)))
malloc_printerr ("double free or corruption (!prev)");
INTERNAL_SIZE_T nextsize = chunksize(nextchunk);
if (__glibc_unlikely (chunksize_nomask (nextchunk) <= CHUNK_HDR_SZ
|| nextsize >= av->system_mem))
malloc_printerr ("free(): invalid next size (normal)");
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
/* Consolidate backward. */
if (!prev_inuse(p))
{
INTERNAL_SIZE_T prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
}
/* Write the chunk header, maybe after merging with the following chunk. */
size = _int_free_create_chunk (av, p, size, nextchunk, nextsize);
_int_free_maybe_consolidate (av, size);
}
Large chunks are placed in the unsorted bin while small chunks are inserted in their associated small bin:
static INTERNAL_SIZE_T
_int_free_create_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size,
mchunkptr nextchunk, INTERNAL_SIZE_T nextsize)
{
if (nextchunk != av->top)
{
/* get and clear inuse bit */
bool nextinuse = inuse_bit_at_offset (nextchunk, nextsize);
/* consolidate forward */
if (!nextinuse) {
unlink_chunk (av, nextchunk);
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0);
mchunkptr bck, fwd;
if (!in_smallbin_range (size))
{
/* Place large chunks in unsorted chunk list. Large chunks are
not placed into regular bins until after they have
been given one chance to be used in malloc.
This branch is first in the if-statement to help branch
prediction on consecutive adjacent frees. */
bck = unsorted_chunks (av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("free(): corrupted unsorted chunks");
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
else
{
/* Place small chunks directly in their smallbin, so they
don't pollute the unsorted bin. */
int chunk_index = smallbin_index (size);
bck = bin_at (av, chunk_index);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("free(): chunks in smallbin corrupted");
mark_bin (av, chunk_index);
}
p->bk = bck;
p->fd = fwd;
bck->fd = p;
fwd->bk = p;
set_head(p, size | PREV_INUSE);
set_foot(p, size);
check_free_chunk(av, p);
}
else
{
/* If the chunk borders the current high end of memory,
consolidate into top. */
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}
return size;
}If the next chunk is the top chunk, the current chunk is consolidated into top:
{
/* If the chunk borders the current high end of memory,
consolidate into top. */
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}
Next, if FASTBIN_CONSOLIDATION_THRESHOLD is reached, then malloc_consolidate(av); is invoked to trigger the fastbins consolidation.
static void
_int_free_maybe_consolidate (mstate av, INTERNAL_SIZE_T size)
{
/* Unless max_fast is 0, we don't know if there are fastbins
bordering top, so we cannot tell for sure whether threshold has
been reached unless fastbins are consolidated. But we don't want
to consolidate on each free. As a compromise, consolidation is
performed if FASTBIN_CONSOLIDATION_THRESHOLD is reached. */
if (size >= FASTBIN_CONSOLIDATION_THRESHOLD)
{
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate(av);
if (av == &main_arena)
{
#ifndef MORECORE_CANNOT_TRIM
if (chunksize (av->top) >= mp_.trim_threshold)
systrim (mp_.top_pad, av);
#endif
}
else
{
/* Always try heap_trim, even if the top chunk is not large,
because the corresponding heap might go away. */
heap_info *heap = heap_for_ptr (top (av));
assert (heap->ar_ptr == av);
heap_trim (heap, mp_.top_pad);
}
}
}
Above, given a pointer, one can determine the arena the chunk belongs to as follows:
static __always_inline struct malloc_state *
arena_for_chunk (mchunkptr ptr)
{
return chunk_main_arena (ptr) ? &main_arena : heap_for_ptr (ptr)->ar_ptr;
}
...
static __always_inline heap_info *
heap_for_ptr (void *ptr)
{
size_t max_size = heap_max_size ();
return PTR_ALIGN_DOWN (ptr, max_size);
}Basicaly if the the chunk size is surfaced with main arena flag then it is main arena which is housed in static segment:
static struct malloc_state main_arena =
{
.mutex = _LIBC_LOCK_INITIALIZER,
.next = &main_arena,
.attached_threads = 1
};Otherwise, because the heap start an an address always aligned to max_size, one can easily get the pointer to the arena using modulo or by aligning down ( heap_for_ptr ) i.e PTR_ALIGN_DOWN (ptr, max_size).
Now back to _int_free_maybe_consolidate, if it turns out that the top chunk exceeds a threshold, i.e., chunksize(av->top) >= mp_.trim_threshold, and we are dealing with the main arena, systrim() is called. systrim() essentially does the inverse of sysmalloc: it releases memory back to the system in page-size units, rounding down the size using top_size - MINSIZE - 1 - pad. This only happens if no foreign sbrk call was observed, meaning the program break (brk) hasn't changed unexpectedly in the meantime. Finally, the top chunk header is updated with the new size, and the arena’s system memory counter is adjusted with av->system_mem -= released.
static int
systrim (size_t pad, mstate av)
{
long top_size; /* Amount of top-most memory */
long extra; /* Amount to release */
long released; /* Amount actually released */
char *current_brk; /* address returned by pre-check sbrk call */
char *new_brk; /* address returned by post-check sbrk call */
long top_area;
top_size = chunksize (av->top);
top_area = top_size - MINSIZE - 1;
if (top_area <= pad)
return 0;
/* Release in pagesize units and round down to the nearest page. */
#ifdef MADV_HUGEPAGE
if (__glibc_unlikely (mp_.thp_pagesize != 0))
extra = ALIGN_DOWN (top_area - pad, mp_.thp_pagesize);
else
#endif
extra = ALIGN_DOWN (top_area - pad, GLRO(dl_pagesize));
if (extra == 0)
return 0;
/*
Only proceed if end of memory is where we last set it.
This avoids problems if there were foreign sbrk calls.
*/
current_brk = (char *) (MORECORE (0));
if (current_brk == (char *) (av->top) + top_size)
{
/*
Attempt to release memory. We ignore MORECORE return value,
and instead call again to find out where new end of memory is.
This avoids problems if first call releases less than we asked,
of if failure somehow altered brk value. (We could still
encounter problems if it altered brk in some very bad way,
but the only thing we can do is adjust anyway, which will cause
some downstream failure.)
*/
MORECORE (-extra);
new_brk = (char *) (MORECORE (0));
LIBC_PROBE (memory_sbrk_less, 2, new_brk, extra);
if (new_brk != (char *) MORECORE_FAILURE)
{
released = (long) (current_brk - new_brk);
if (released != 0)
{
/* Success. Adjust top. */
av->system_mem -= released;
set_head (av->top, (top_size - released) | PREV_INUSE);
check_malloc_state (av);
return 1;
}
}
}
return 0;
}In case of dealing with a thread arena, a pointer to the heap_info * structure is obtained heap_info *heap = heap_for_ptr(top(av)); next, heap_trim is invoked; which will check if the corresponding heap can go away. The code is listed below:
static int
heap_trim (heap_info *heap, size_t pad)
{
mstate ar_ptr = heap->ar_ptr;
mchunkptr top_chunk = top (ar_ptr), p;
heap_info *prev_heap;
long new_size, top_size, top_area, extra, prev_size, misalign;
size_t max_size = heap_max_size ();
/* Can this heap go away completely? */
while (top_chunk == chunk_at_offset (heap, sizeof (*heap)))
{
prev_heap = heap->prev;
prev_size = prev_heap->size - (MINSIZE - 2 * SIZE_SZ);
p = chunk_at_offset (prev_heap, prev_size);
/* fencepost must be properly aligned. */
misalign = ((long) p) & MALLOC_ALIGN_MASK;
p = chunk_at_offset (prev_heap, prev_size - misalign);
assert (chunksize_nomask (p) == (0 | PREV_INUSE)); /* must be fencepost */
p = prev_chunk (p);
new_size = chunksize (p) + (MINSIZE - 2 * SIZE_SZ) + misalign;
assert (new_size > 0 && new_size < (long) (2 * MINSIZE));
if (!prev_inuse (p))
new_size += prev_size (p);
assert (new_size > 0 && new_size < max_size);
if (new_size + (max_size - prev_heap->size) < pad + MINSIZE
+ heap->pagesize)
break;
ar_ptr->system_mem -= heap->size;
LIBC_PROBE (memory_heap_free, 2, heap, heap->size);
if ((char *) heap + max_size == aligned_heap_area)
aligned_heap_area = NULL;
__munmap (heap, max_size);
heap = prev_heap;
if (!prev_inuse (p)) /* consolidate backward */
{
p = prev_chunk (p);
unlink_chunk (ar_ptr, p);
}
assert (((unsigned long) ((char *) p + new_size) & (heap->pagesize - 1))
== 0);
assert (((char *) p + new_size) == ((char *) heap + heap->size));
top (ar_ptr) = top_chunk = p;
set_head (top_chunk, new_size | PREV_INUSE);
/*check_chunk(ar_ptr, top_chunk);*/
}
/* Uses similar logic for per-thread arenas as the main arena with systrim
and _int_free by preserving the top pad and rounding down to the nearest
page. */
top_size = chunksize (top_chunk);
if ((unsigned long)(top_size) <
(unsigned long)(mp_.trim_threshold))
return 0;
top_area = top_size - MINSIZE - 1;
if (top_area < 0 || (size_t) top_area <= pad)
return 0;
/* Release in pagesize units and round down to the nearest page. */
extra = ALIGN_DOWN(top_area - pad, heap->pagesize);
if (extra == 0)
return 0;
/* Try to shrink. */
if (shrink_heap (heap, extra) != 0)
return 0;
ar_ptr->system_mem -= extra;
/* Success. Adjust top accordingly. */
set_head (top_chunk, (top_size - extra) | PREV_INUSE);
/*check_chunk(ar_ptr, top_chunk);*/
return 1;
}
Before attempting to shrink the heap, glibc checks whether the heap can be destroyed and removed from the linked list. This is possible only if top_chunk == chunk_at_offset(heap, sizeof(*heap))(malloc_state is added only once...) which means the top chunk is the only chunk in the heap (this does not necessarily imply the arena itself is unused, as several heaps can be linked). A pointer to the fencepost chunk of the previous heap is obtained by subtracting the fencepost size:prev_size = prev_heap->size - (MINSIZE - 2 * SIZE_SZ);, p = chunk_at_offset(prev_heap, prev_size);. The fencepost always has size 0, marks the previous chunk as in-use withPREV_INUSE, and must be properly aligned: assert(chunksize_nomask(p) == (0 | PREV_INUSE)); (for more details see earlier section about fenceposts). Now, the previous chunk of the fencepost becomes the new top chunk via p = prev_chunk(p);. The top chunk is then consolidated with the previous chunk if it is not in use. Only if the condition if (new_size + (max_size - prev_heap->size) < pad + MINSIZE + heap->pagesize) holds (i.e worth unmapping if remaining space in the previous heap is big enough), the heap subject for deletion is unmapped via __munmap(heap, max_size); reclaiming the memory and updating the arena's bookkeeping like av->system_mem ; the top chunk now has new size equals chunksize (p) + (MINSIZE - 2 * SIZE_SZ) + misalign;.
Now whether the heap was destroyed or not, the current heap is subject to trimming (if top size above trim_threshold ).
top_size = chunksize (top_chunk);
if ((unsigned long)(top_size) <
(unsigned long)(mp_.trim_threshold))
return 0; Similar to systrim(), top_size - MINSIZE - 1 - padding is aligned to page size (rounded down) and heap size is shrinked shrink_heap (heap, extra). As shown below, shrinking the heap by diff bytes consists of calling mmap to unmap the physical pages backing the virtual address memory area (the virtual address space still exists and is part of the heap, but the physical pages are freed to the kernel). If the heap cannot be shrunk, then __madvise((char *) h + new_size, diff, MADV_DONTNEED); is invoked to tell the kernel that the specified memory pages from h + new_size to h + new_size + diff are no longer needed and can be reclaimed immediately or lazily. This way, the virtual address range is preserved (so the heap layout doesn’t change), but the physical pages backing it can be dropped, reducing memory usage.
static int
shrink_heap (heap_info *h, long diff)
{
long new_size;
new_size = (long) h->size - diff;
if (new_size < (long) sizeof (*h))
return -1;
/* Try to re-map the extra heap space freshly to save memory, and make it
inaccessible. See malloc-sysdep.h to know when this is true. */
if (__glibc_unlikely (check_may_shrink_heap ()))
{
if ((char *) MMAP ((char *) h + new_size, diff, PROT_NONE,
MAP_FIXED) == (char *) MAP_FAILED)
return -2;
h->mprotect_size = new_size;
}
else
__madvise ((char *) h + new_size, diff, MADV_DONTNEED);
/*fprintf(stderr, "shrink %p %08lx\n", h, new_size);*/
h->size = new_size;
LIBC_PROBE (memory_heap_less, 2, h, h->size);
return 0;
}In this post, we covered the implementation of the glibc heap allocator (ptmalloc2), leveraging decades of maturity and integration of security related fixes shared by the community. While ptmalloc2 remains the default in glibc, other allocators such as TCMalloc (Google) and JeMalloc (Facebook, archived) also deserve attention, each offering their own design trade-offs.
Despite significant progress, heap vulnerabilities continue to affect high-profile applications. Many modern exploits target heap allocator metadata structures to escalate memory corruption bugs into arbitrary code execution. Hardened allocators can be highly effective in mitigating these attacks. Although not foolproof, they raise the bar significantly for adversaries. That said, these allocators often struggle to strike the right balance between performance and security.
If you think you found a mistake or think that I misunderstood something, please feel free to reach out!.