Implementing highly efficient matrix multiplication routines that approach peak performance demands significant effort, strong linear algebra knowledge, and a deep understanding of the underlying hardware architecture (even down to the microarchitectural level[23]). This is why vendors provide highly optimized implementations of the Basic Linear Algebra Subprograms (BLAS)[1], including

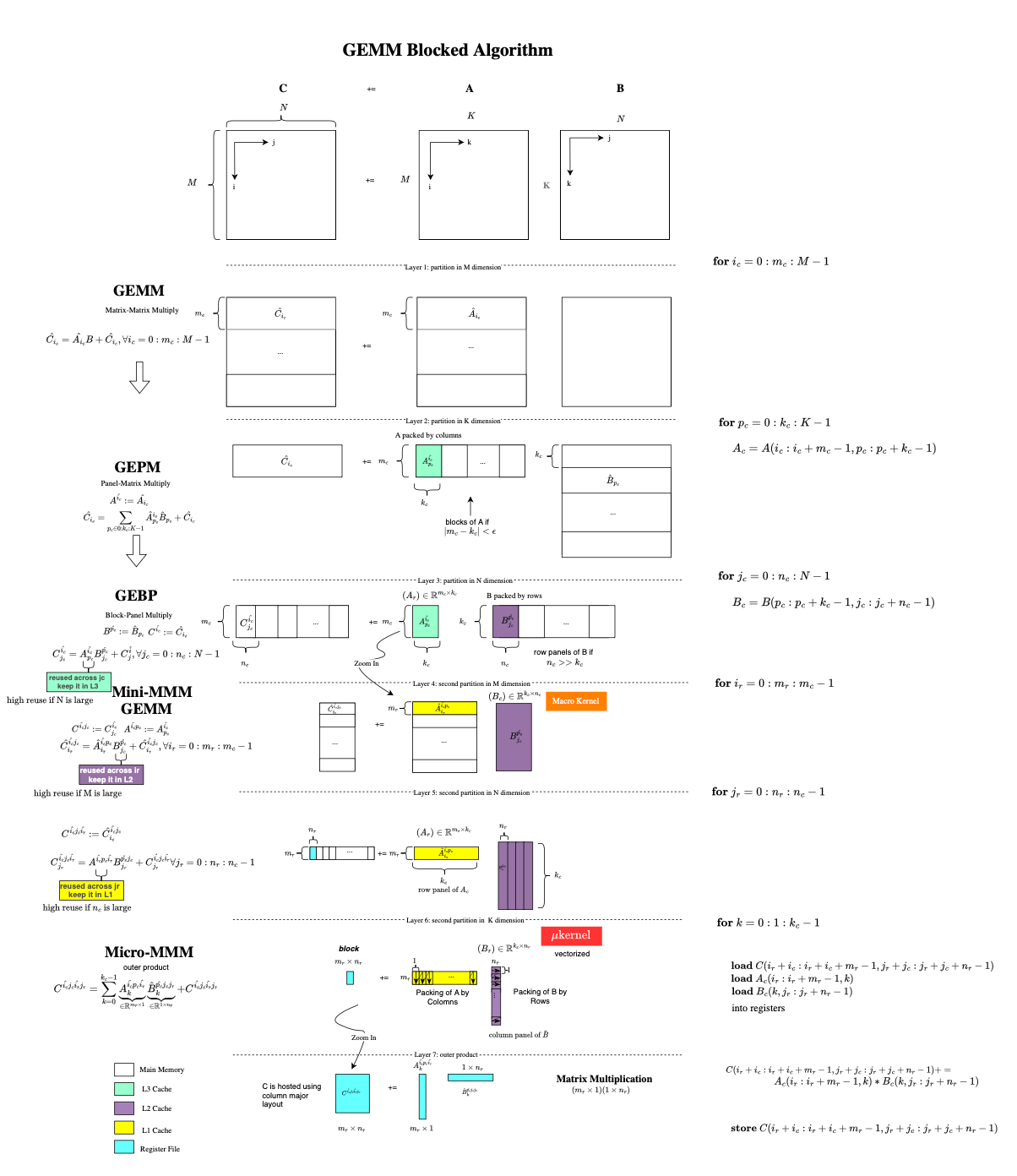
Beyond the microkernel, performance is achieved through loop transformations and multi-level tiling that target different levels of the memory hierarchy (registers, L1, L2, and L3 caches). The goal is to minimize data movement. In fact, while processors can perform floating-point operations extremely fast, matrix multiplication only reaches high performance when data reuse translates into locality (e.g when loops are localized). Additional optimizations include prefetching [7] to overlap computation and data movement, and loop unrolling [8] to expose instruction-level parallelism and reduce control overhead.
This post is the first in a series dedicated to high-performance programming for scientific computing, machine learning, and deep learning applications. We will study both fundamental optimization techniques and high-quality open-source implementations such as OpenBLAS. In practice, it is often best to express computations in terms of such libraries in order to benefit from the extensive expertise embedded in them (instead of trying to implement it on your own).
To motivate this post, let us consider a simple matrix multiplication using PyTorch, i.e., \( C \mathrel{+}= AB \), where \( A \), \( B \), and \( C \) are square matrices of size \( N = 2^{11} \). A matrix multiplication of the form \( C \mathrel{+}= AB \) requires \( N \) fused multiply--add (FMA) operations for each of the \( N^2 \) output elements, yielding a total of \( 2N^3 \) floating-point operations (FLOPs).def bench_torch(N):
A = torch.rand(N, N, dtype=torch.float64)
B = torch.rand(N, N, dtype=torch.float64)
for _ in range(warmup):
_ = torch.matmul(A, B)
start = time.perf_counter()
for _ in range(iterations):
C = torch.matmul(A, B)
end = time.perf_counter()
avg_time = (end - start) / iterations
gflops = (2 * N ** 3) / (avg_time * 1e9)
return gflops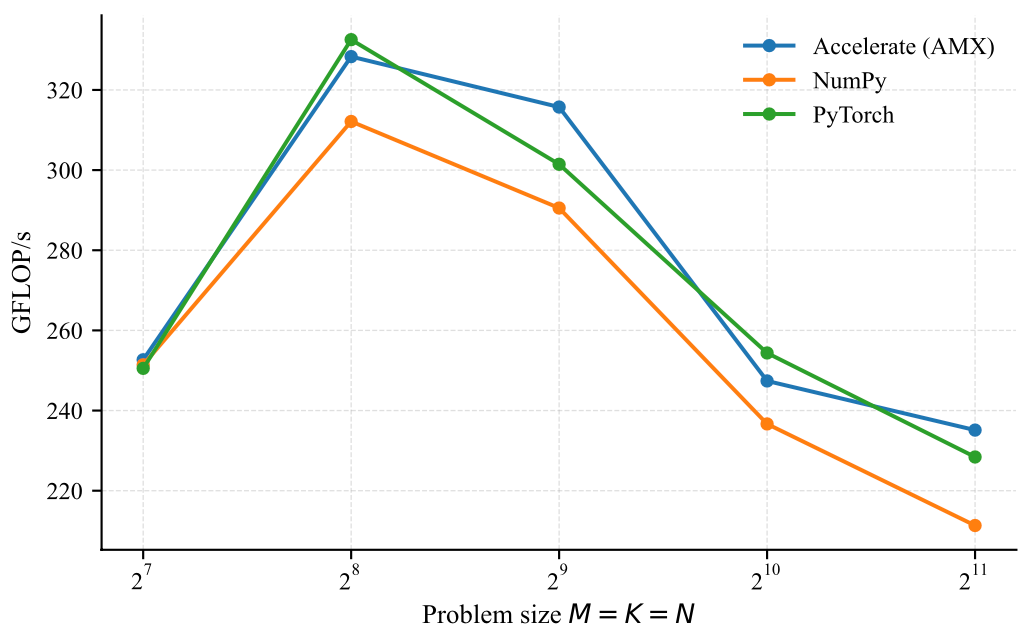
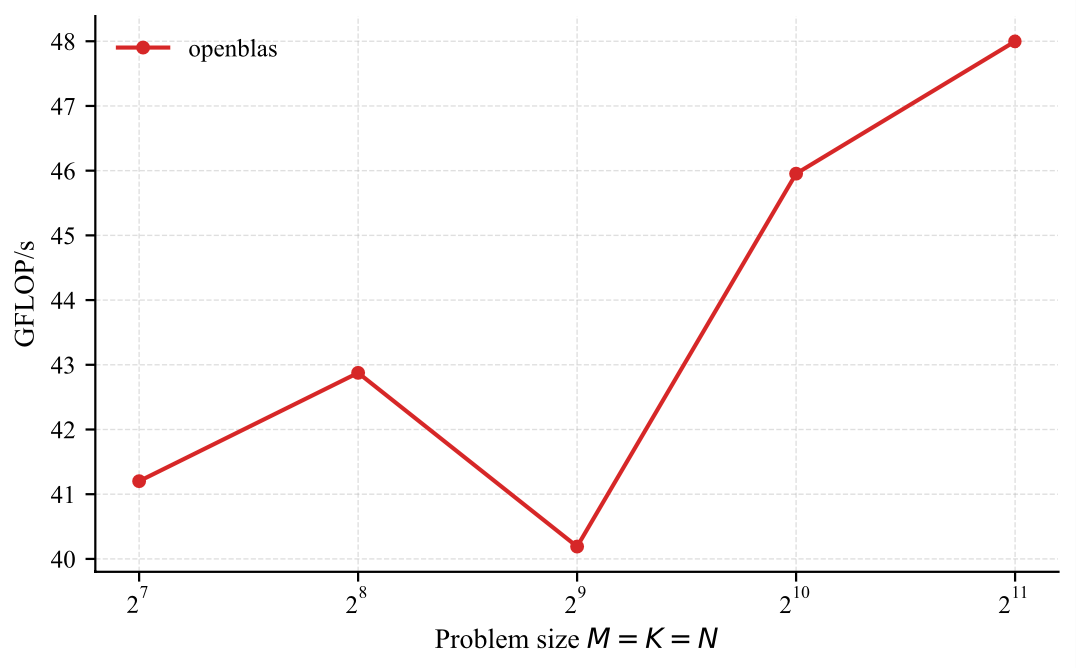
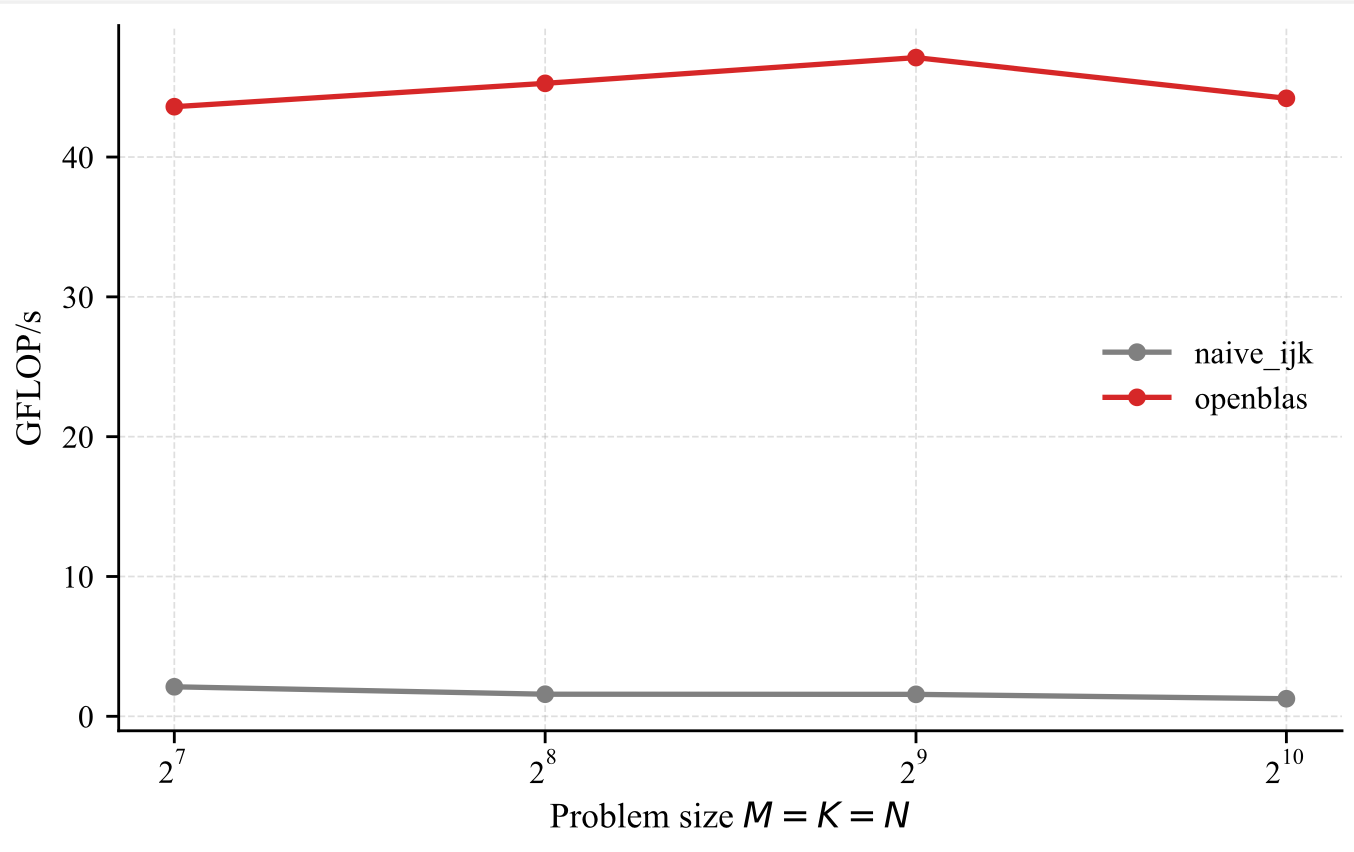
From now on, we will use OpenBLAS [21] as our reference (single threaded) implementation. Its performance is depicted below.
BLAS was basically introduced to define a standard interface for dense linear algebra routines that researchers or developers can invoke in their applications. It promotes portability of high-performance implementations, as each platform may provide its own highly optimized version. As said briefly before, GEMM routines are carefully tuned for specific hardware architectures, where memory is organized as a multi-level hierarchy, and access cost (in cycles) increases with each level. Lower-level caches offer lower latency but smaller capacity.
High-performance implementations aim to fully exploit hardware features such as vector units and multi-threading to accelerate computation and approach peak performance. A key objective is to maximize the time spent in the architecture-specific microkernel while ensuring that reused data remains in cache across iterations, thereby enjoying locality.
Deep learning workloads, including large language models (LLMs), transformers, and fully connected layers, rely heavily on matrix operations during both training and inference. They typically involve a mix of GEMM and GEMV operations, where GEMM is compute-bound and GEMV is memory-bound.
Consider a fully connected layer defined by a weight matrix \( W \in \mathbb{R}^{m \times d} \) and a bias vector \( b \in \mathbb{R}^{m} \), mapping an input \( x \in \mathbb{R}^{d} \) to an output \( y \in \mathbb{R}^{m} \) via \( y = W x + b \). This computation requires \( m \times d \) fused multiply-add (FMA) operations, i.e., \( 2md \) floating-point operations (FLOPs). When processing a batch of inputs, this generalizes to \( Y = W X + b \mathbf{1}^T \), where \( X \in \mathbb{R}^{d \times n} \), each column of \( X \) corresponds to a sample, and \( \mathbf{1} \in \mathbb{R}^{n} \) is a vector of ones. Backpropagation can also be expressed in terms of GEMM operations. After the linear transformation, a nonlinearity is often applied: \( Y = \sigma(Y) \) (otherwise your can not cope with non linear problems). Transformer architectures [9] make extensive use of self-attention and feedforward layers, which can largely be expressed as GEMM operations. During training, most computations can be reformulated as GEMM (e.g., via masking), making training predominantly compute-bound. In contrast, inference in large language models involves a mix of GEMM and GEMV operations. GEMM is primarily used during the prompt prefill phase[9], where input tokens are processed in parallel. Subsequent token generation relies on the key-value (KV) cache and follows an autoregressive process. Since the number of generated tokens is typically large, inference becomes dominated by GEMV operations, which have lower arithmetic intensity than GEMM. As a result, inference is generally memory-bound.In this post, we present techniques for optimizing matrix multiplication kernels so that they become compute-bound and approach peak performance on CPU architectures by reducing data movement across the memory hierarchy. We consider both macro-level optimizations (such as loop transformations and tiling) and micro-level optimizations (such as microkernel design) to achieve data locality and efficient use of the memory hierarchy. A subsequent post will focus on GEMM and GEMV optimizations for GPU architectures.
Modern processors are incredibly complex. At the microarchitectural level, many techniques are employed to hide latency and increase throughput. These include caches, instruction and data pipelining, register renaming [10], and out-of-order execution. Additionally, multicore architectures are used to further increase peak performance and exploit thread-level parallelism.
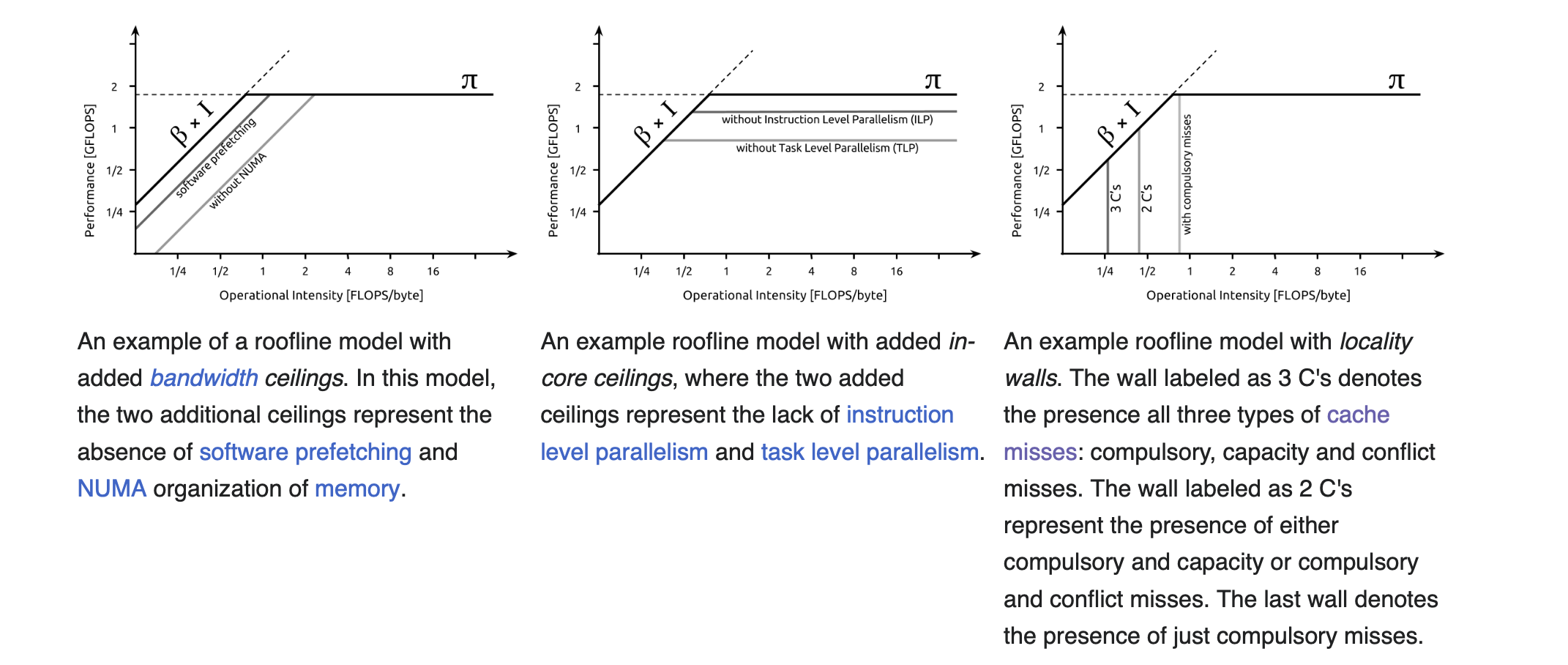
While hardware evolves to compute FLOPs very fast, organizing computational kernels to exploit all these features and get close to peak performance is not trivial and requires significant effort. This includes loop unrolling to increase ILP, SIMD [11] to reduce fetch and decode overhead, balancing floating-point operation mix to exploit FMA units (e.g., parity between MULTs and ADDs), prefetching[7] to overlap computation and data movement, and reduction of memory traffic so that kernels approach the compulsory memory traffic.
For example, using good stride access enables spatial locality, reuse enables temporal locality, and organizing data avoids conflict misses (e.g., padding arrays using cache arithmetic) during hotspots. Especially important is distributing the data on which computation kernels operate across different memory layers, i.e., register and cache tiling or multi level tiling.
Naturally, all of this exacerbates the difficult job of engineers who seek to understand the primary factors affecting the performance of a floating-point kernel, i.e., which optimization yields the highest benefit. One way to understand how to optimize code and make it run faster is to look at the operational intensity \(I\), defined as the ratio of compute to memory traffic, which tells us which ceilings to consider.
Let \(C\) denote the number of cycles spent on some kernel, \(F\) the number of FLOPs, and \(L\) the number of bytes loaded. Let \(\pi\) be the attainable peak performance (e.g., FLOPs per cycle) and \(\beta\) the memory bandwidth (bytes per cycle). If we assume that computation and data movement (traffic between caches and memory rather than between core and caches) cannot be overlapped, then the number of cycles required is \(C = \frac{F}{\pi} + \frac{L}{\beta}\). To compare the relative contribution of computation and memory traffic, we rewrite both terms with a common factor \(\frac{1}{\beta} \): \(C = \left(\frac{F\beta}{\pi}\right)\frac{1}{\beta} + L \cdot \frac{1}{\beta}\). Thus, if \(L >> \frac{F\beta}{\pi}\) then the cycles are dominated by memory, i.e., the kernel is memory-bound. This also implies \(I \beta < \pi\) where \(I = \frac{F}{L}\) is the arithmetic or operational intensity.
In practice, computation and data movement can overlap to some extent. This leads to the bound \( \max\left(\frac{F}{\pi}, \frac{L}{\beta}\right) \leq C \leq \frac{F}{\pi} + \frac{L}{\beta}\). In the ideal case of perfect overlap, we obtain: \(C = \max\left(\frac{F}{\pi}, \frac{L}{\beta}\right)\). Thus, the performance (FLOPs per cycle) is:
\(P = \frac{F}{\max\left(\frac{F}{\pi}, \frac{L}{\beta}\right)} \leq \pi\)
\(P = \frac{1}{\max\left(\frac{1}{\pi}, \frac{L}{F\beta}\right)}\)
\(= \min\left(\pi, \underbrace{\frac{F}{L}}_{I:= \text{arithmetic intensity}}\beta\right)\)
\(= \min\left(\pi, I\beta\right)\)
This shows that performance is limited either by compute capability \(\pi\) or by memory bandwidth scaled by arithmetic intensity \(I\beta\). If \(I > \frac{\pi}{\beta}\) then \(I\beta > \pi\), and performance can attain the peak \(\pi\), meaning the kernel is compute-bound. The term \(\frac{\pi}{\beta}\) is known as the ridge point [12], i.e., the minimum intensity required to achieve peak performance. On the other hand, low operational intensity (\(I < \frac{\pi}{\beta}\)) implies the kernel is memory-bound, i.e. sufficiently high intensity means compute-bound, while relatively low intensity means memory-bound. Before the ridge point, performance grows linearly with intensity with slope \(\beta\) i.e \(P = \beta I\) and after the ridge point, performance saturates at \(\pi\). Increasing intensity can move a kernel from the memory-bound regime to the compute-bound regime.
The roofline model, involving both computational and bandwidth complexity, is widely used in deep learning to understand bottlenecks in kernels such as GEMM and GEMV. For example, LSTM [13] kernels typically exhibit lower FLOP/s performance and higher data movement compared to convolutions or transformers due to limited parallelism.
Finally, let’s stress again that the roofline model is an optimistic model; it assumes that compute time can overlap with bandwidth time. In practice lower ceilings are hit and thus the model provides an upper bound on achievable performance.
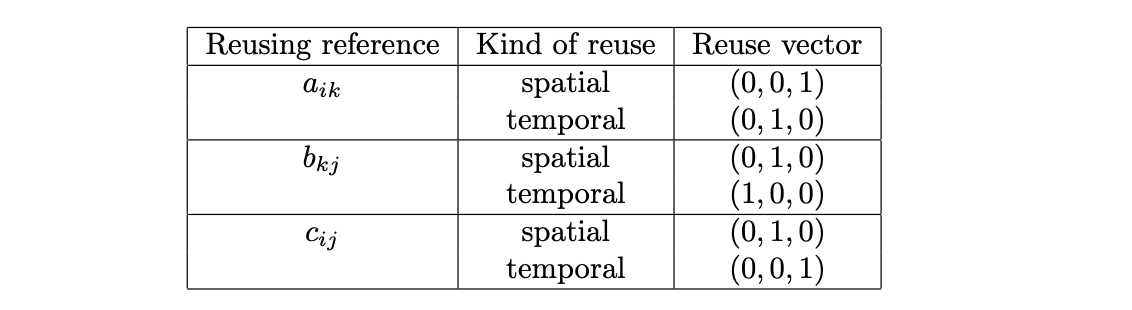
What is important to understand is that reuse does not necessarily imply locality (i.e., cache hits). Data locality can be characterized, in the polyhedral model [4], as the subset of iteration space directions along which data reuse results in cache hits which can be obtained by intersecting the data reuse vectors with the localized iteration space. For example, consider the (ikj) algorithm for matrix multiplication. When the matrices are large, the localized iteration space is \(\mathrm{span}(0,0,1)\) only.
Let \(A\), \(B\), and \(C\) denote matrices in \(\mathbb{R}^{M \times K}\),\(\mathbb{R}^{K \times N}\), and \(\mathbb{R}^{M \times N}\) respectively, with entries \(a_{ik}\), \(b_{kj}\), and \(c_{ij}\). For simplicity we assume that \(M= m_cM'\), \(N = n_cN'\), and \(K = k_cK'\), i.e \(M,N\) and \(K\) are multiples of \(m_c,n_c\) and \(k_c\) respectively. If we consider an \(l \times d\) submatrix \(A_{ld}\) of a matrix \(A\), then, if \(l\) and \(d\) are approximately equal, \(A_{ld}\) is said to be a block of \(A\), else if \(d \gg l\), then \(A_{ld}\) is called a row panel, and if \(d \ll l\), then \(A_{ld}\) is called a column panel of \(A\).
Regarding how arrays are mapped to memory, we assume that matrices are linearized in memory using a row-major layout. Let \(A\) be an \(n\)-dimensional array where \(\text{s}_k\) denotes the number of elements in dimension \(k\), and consider a loop nest of depth \(m\) represented by the iteration vector \(\vec{i}\). The row-major layout mapping \(a\) is a function \[ a : \mathbb{N}^m \rightarrow \mathbb{N} \] of the loop indices: \[ a(i_1, \ldots, i_n) = \text{offset} + i_1 \cdot \text{s}_2 \cdots \text{s}_n + i_2 \cdot \text{s}_3 \cdots \text{s}_n + \cdots + i_{n-1} \cdot \text{s}_n + i_n . \] where \(\text{offset}\) denotes the base address of the array \(A\), i.e. its displacement in memory. Thus the memory address of an element of array \(A\) (i.e. a reference) can be written as \[ \text{Memory\_Address\_of\_A}[i_1, \ldots, i_n] = \text{Mem}_{R_A}(\vec{i}) = a(i_1, \ldots, i_n). \] The cache set accessed by the reference \(R_A\) is given by \[ \text{Cache\_Set}_{R_A}(\vec{i}) = \underbrace{\left \lfloor \frac{\text{Mem}_{R_A}(\vec{i})}{L_s} \right \rfloor}_{Mem^{L}_{R_A(\vec{i})}} \bmod N_S \] where \(L_S\) denotes the cache line size and \(N_S\) the number of cache lines. We have a cache interference (self or cross) when the cache set accessed by \(R_A\) at \(\vec{i}\) is the same as any of the cache sets accessed by \(R_B\) at every potentially interfering iteration \(\vec{j}\) between \(\vec{p}\) and \(\vec{i}\) i.e when \[ \text{CacheSet}_{R_A}(\vec{i}) = \text{CacheSet}_{R_B}(\vec{j}) \] which implies \[ \text{mem}_{R_A}^{L}(\vec{i}) \bmod N_S = \text{mem}_{R_B}^{L}(\vec{j}) \bmod N_S \] Recall that \[ x = \left\lfloor \frac{x}{N} \right\rfloor N + (x \bmod N) \] Thus \[ \text{mem}_{R_A}^{L}(\vec{i}) \bmod N_S = \text{mem}_{R_B}^{L}(\vec{j}) \bmod N_S \] Since \[ C_S = k L_S N_S \] we obtain \[ N_S = \frac{C_S}{kL_S} \] Thus \[ \left\lfloor \frac{\text{Mem}_{R_A}(\vec{i})}{L_S} \right\rfloor \bmod N_S = \left\lfloor \frac{\text{Mem}_{R_B}(\vec{j})}{L_S} \right\rfloor \bmod N_S \] which implies \[ \left\lfloor \frac{\text{Mem}_{R_A}(\vec{i})}{L_S} \right\rfloor - \left\lfloor \frac{\text{Mem}_{R_B}(\vec{j})}{L_S} \right\rfloor = 0 \pmod{N_S} \] or equivalently \[ \left\lfloor \frac{\text{Mem}_{R_A}(\vec{i})}{L_S} \right\rfloor = n \frac{C_S}{kL_S} + \left\lfloor \frac{\text{Mem}_{R_B}(\vec{j})}{L_S} \right\rfloor \] Multiplying by \(L_S\): \[ \text{Mem}_{R_A}(\vec{i}) = n\frac{C_S}{k} + \text{Mem}_{R_B}(\vec{j}) + \underbrace{((\text{Mem}_{R_A}(\vec{i}) \mod L_S) - (\text{Mem}_{R_B}(\vec{j}) \mod L_S))}_{\in [-(L_S-1), L_S-1]} \] i.e \[ \text{Mem}_{R_A}(\vec{i}) = n\frac{C_S}{k} + \text{Mem}_{R_B}(\vec{j}) + b \] where \[ b \in [-L_S+1, L_S-1] \] This is the general cache replacement miss equation[5]. We conclude that an interference occurs when \[ \text{Mem}_{R_A}(\vec{i}) = \text{Mem}_{R_B}(\vec{j}) + n\frac{C_S}{k} + b \] with \[ b \in [-L_S+1,L_S-1] \]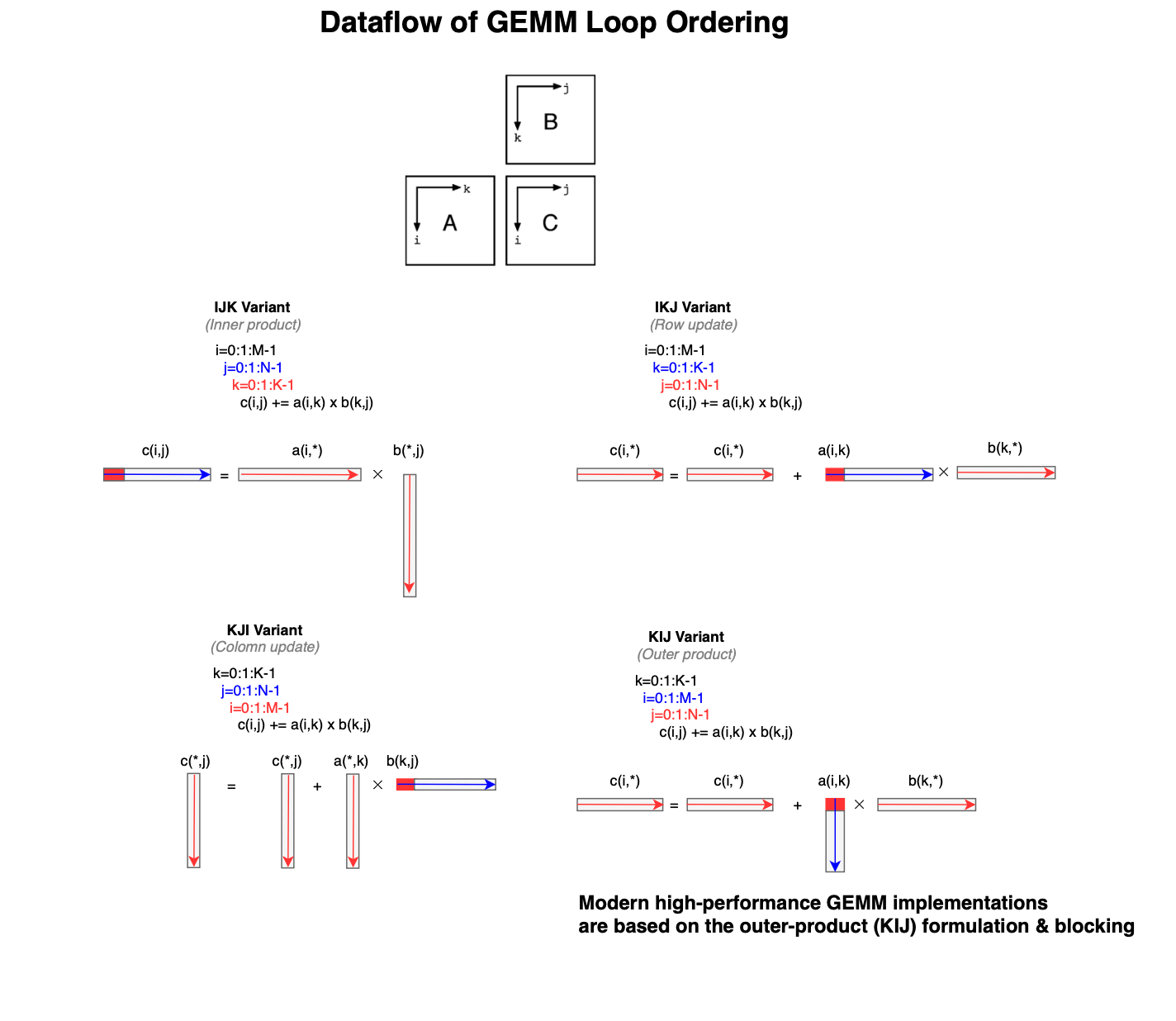
We look at the variant ijk and analyse its memory traffic.
For i=0:1:M-1
For j=0:1:N-1
For k=0:1:K-1
c_ij += a_ik b_kjThe implementation in c is listed below:
void matmul_naive_ijk(const double *A, const double *B, double *C, int64_t n) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++)
C[i * n + j] += A[i * n + k] * B[k * n + j];
}
}If we inspect the produced assembly code, there is only one early load of c reused during the entire k loop, A and B references are loaded and one FMA instruction is used i.e 2 FLOPS per cycle instead of one multiply followed by one add. However, the compiler did not unroll the loop nor used vector hardware, and 2 flops per iteration means very low operational intensity.
ldr d0, [x2, x14, lsl #3]
mov x15, x12
ldr d1, [x0, x13, lsl #3]
ldr d2, [x15]
fmadd d0, d1, d2, d0
Looking at the figure below, the performance gap between openblas (1 core) and our custom implementation is huge. We will focusing on shrinking this gap in the rest of this post. But first lets understand why is the performance is terrible.
Suppose that N,M and K are very large. The reuse vectors for each reference are listed below. Temporal reuse means a reference accesses the same data element in different iterations of the loop, while spatial reuse means a reference accesses the same memory or cache line in different iterations of the loop.
For i=0:1:M-1
For k=0:1:K-1
For j=0:1:N-1
c_ij += a_ik b_kjThe c code is listed below:
void matmul_ikj(const double *restrict A, const double *restrict B, double *restrict C, int64_t n) {
for (int i = 0; i < n; i++)
for (int k = 0; k < n; k++)
for (int j = 0; j < n; j++)
C[i * n + j] += A[i * n + k] * B[k * n + j];
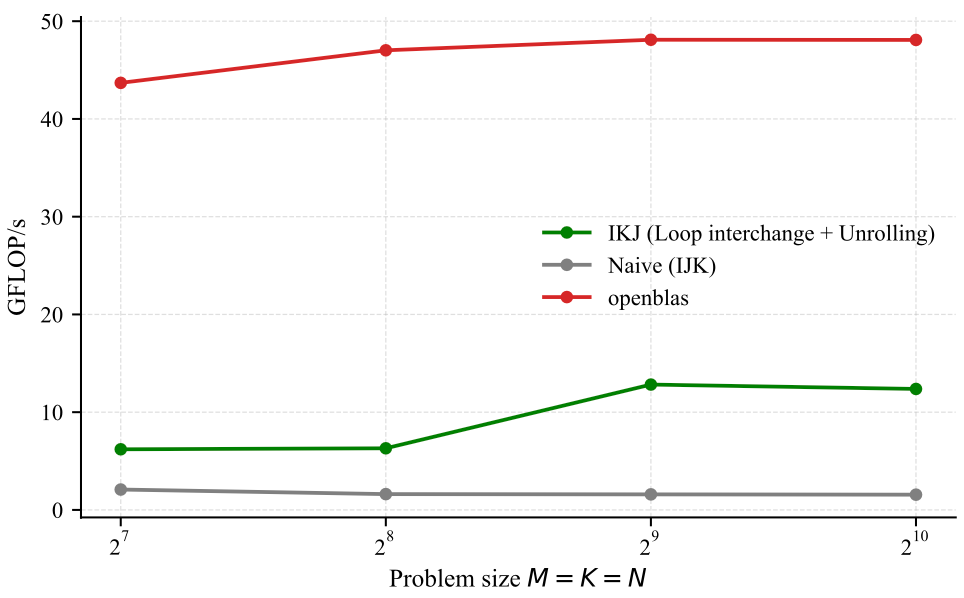
}Inspecting the produced assembly code, thanks to the loop interchange transformation, the compiler was capable of applying a loop unrolling and thereby reducing loop overhead in addition to reducing cache misses. Additionally, the compiler used vector instructions as listed below (fmla.2d is a vector fma ).
ldp q2, q3, [x5, #-32]
ldp q4, q5, [x5], #64
ldp q6, q7, [x4, #-32]
ldp q16, q17, [x4]
fmla.2d v6, v2, v1
fmla.2d v7, v3, v1
fmla.2d v16, v4, v1
fmla.2d v17, v5, v1
So now with the loop interchange we unlocked loop unrolling and also the use of vectorization which leads to higher arithmetic intensity and this better performance. This can be confirmed below. We still have some gap to bridge but we will work on it.
For jj=0:n_c:N-n_c-1
For i=0:1:M-1
For k=0:1:K-1
For j=jj:1:jj+n_c-1
c_ij += a_ik b_kjFor ii=0:m_c:M-m_c-1
For jj=0:n_c:N-n_c-1
For i=ii:1:ii+m_c-1
For k=0:1:K-1
For j=jj:1:jj+n_c-1
c_ij += a_ik b_kjFor ii=0:m_c:M-m_c-1
For kk=0:k_c:K-k_c-1
For jj=0:n_c:N-n_c-1
For i=ii:1:ii+m_c-1
For k=kk:1:kk+k_c-1
For j=jj:1:jj+n_c-1
c_ij += a_ik b_kjFor iii=0:m_c:M-1
For kkk=0:k_c:K-1
For jjj=0:n_c:N-1
For ii=iii:m_r:iii+m_c-1
For kk=kkk:k_r:kkk+k_c-1
For jj=jjj:n_r:jjj+n_c-1
For k=kk:1:kk+k_r-1
For i=ii:1:ii+m_r-1
For j=jj:1:jj+n_r-1
C[i,j] += A[i,k] * B[k,j]For iii = 0 : m_c : M-1
For kkk = 0 : k_c : K-1
For jjj = 0 : n_c : N-1
// macro kernel
For ii = iii : m_r : iii + m_c - 1
For jj = jjj : n_r : jjj + n_c - 1
# LR : micro-kernel operating on C_r (m_r × n_r)
For k = kkk : 1 : kkk + k_c - 1
For i = ii : 1 : ii + m_r - 1
For j = jj : 1 : jj + n_r - 1
C[i,j] += A[i,k] * B[k,j]or equivalently represented as:
For iii = 0 : m_c : M-1
For kk = 0 : k_c : K-1
For jjj = 0 : n_c : N-1
For ii = iii : m_r : iii + m_c - 1
For jj = jjj : n_r : jjj + n_c - 1
# LR : micro-kernel operating on C_r (m_r × n_r)
For k = kk : 1 : kk + k_c - 1
C[ii:ii+m_r-1, jj:jj+n_r-1] +=
A[ii:ii+m_r-1, k] * B[k, jj:jj+n_r-1]For iii = 0 : m_c : M-1
For kkk = 0 : k_c : K-1
// Pack A_c (m_c × k_c)
Ac = A[iii:iii+m_c-1 , kkk:kkk+k_c-1]
For jjj = 0 : n_c : N-1
// Pack B_c (k_c × n_c)
Bc = B[kkk:kkk+k_c-1 , jjj:jjj+n_c-1]
For ii = iii : m_r : iii + m_c - 1
For jj = jjj : n_r : jjj + n_c - 1
# LR : micro-kernel operating on C_r (m_r × n_r)
For k = 0 : 1 : k_c - 1
C[ii:ii+m_r-1, jj:jj+n_r-1] +=
Ac[ii-iii:ii-iii+m_r-1, k] *
Bc[k, jj-jjj:jj-jjj+n_r-1]or if you will
For iii = 0 : m_c : M-1
For kkk = 0 : k_c : K-1
// Pack A_c (m_c × k_c)
Ac = A[iii:iii+m_c-1 , kkk:kkk+k_c-1]
For jjj = 0 : n_c : N-1
// Pack B_c (k_c × n_c)
Bc = B[kkk:kkk+k_c-1 , jjj:jjj+n_c-1]
For ii = 0 : m_r : m_c - 1
For jj = 0 : n_r : n_c - 1
# LR : micro-kernel operating on C_r (m_r × n_r)
For k = 0 : 1 : k_c - 1
C[iii+ii:iii+ii+m_r-1, jjj+jj:jjj+jj+n_r-1] +=
Ac[ii:ii+m_r-1, k] *
Bc[k, jj:jj+n_r-1]Example code for register and cache tiling are listed below:
void matmul_register_tiling(const double *__restrict A,
const double *__restrict B,
double *__restrict C,
int64_t n) {
for (int64_t ii = 0; ii < n; ii += 2) {
for (int64_t jj = 0; jj < n; jj += 2) {
double c00 = C[(ii + 0) * n + (jj + 0)];
double c01 = C[(ii + 0) * n + (jj + 1)];
double c10 = C[(ii + 1) * n + (jj + 0)];
double c11 = C[(ii + 1) * n + (jj + 1)];
for (int64_t k = 0; k < n; ++k) {
double a0 = A[(ii + 0) * n + k];
double a1 = A[(ii + 1) * n + k];
double b0 = B[k * n + (jj + 0)];
double b1 = B[k * n + (jj + 1)];
c00 += a0 * b0;
c01 += a0 * b1;
c10 += a1 * b0;
c11 += a1 * b1;
}
C[(ii + 0) * n + (jj + 0)] = c00;
C[(ii + 0) * n + (jj + 1)] = c01;
C[(ii + 1) * n + (jj + 0)] = c10;
C[(ii + 1) * n + (jj + 1)] = c11;
}
}
}void matmul_cache_tiling(const double *restrict A, const double *restrict B, double *restrict C, int64_t n) {
const int bs = 32;
for (int ii = 0; ii < n; ii += bs) {
for (int kk = 0; kk < n; kk += bs) {
for (int i = ii; i < ii + bs; i++) {
for (int k = kk; k < kk + bs; k++) {
double aik = A[i * n + k];
for (int j = 0; j < n; j++) {
C[i * n + j] += aik * B[k * n + j];
}
}
}
}
}
}A naive combination of cache and register tiling would look like this:
void matmul_cache_and_register_tiling(
const double *restrict A,
const double *restrict B,
double *restrict C,
int64_t n)
{
const int64_t bs = 32;
for (int64_t iii = 0; iii < n; iii += bs) {
for (int64_t kkk = 0; kkk < n; kkk += bs) {
for (int64_t jjj = 0; jjj < n; jjj += bs) {
for (int64_t ii = iii; ii < iii + bs; ii += 4) {
for (int64_t jj = jjj; jj < jjj + bs; jj += 4) {
double c00 = C[(ii + 0) * n + (jj + 0)];
double c01 = C[(ii + 0) * n + (jj + 1)];
double c02 = C[(ii + 0) * n + (jj + 2)];
double c03 = C[(ii + 0) * n + (jj + 3)];
double c10 = C[(ii + 1) * n + (jj + 0)];
double c11 = C[(ii + 1) * n + (jj + 1)];
double c12 = C[(ii + 1) * n + (jj + 2)];
double c13 = C[(ii + 1) * n + (jj + 3)];
double c20 = C[(ii + 2) * n + (jj + 0)];
double c21 = C[(ii + 2) * n + (jj + 1)];
double c22 = C[(ii + 2) * n + (jj + 2)];
double c23 = C[(ii + 2) * n + (jj + 3)];
double c30 = C[(ii + 3) * n + (jj + 0)];
double c31 = C[(ii + 3) * n + (jj + 1)];
double c32 = C[(ii + 3) * n + (jj + 2)];
double c33 = C[(ii + 3) * n + (jj + 3)];
for (int64_t k = kkk; k < kkk + bs; ++k) {
double a0 = A[(ii + 0) * n + k];
double a1 = A[(ii + 1) * n + k];
double a2 = A[(ii + 2) * n + k];
double a3 = A[(ii + 3) * n + k];
double b0 = B[k * n + (jj + 0)];
double b1 = B[k * n + (jj + 1)];
double b2 = B[k * n + (jj + 2)];
double b3 = B[k * n + (jj + 3)];
c00 += a0 * b0;
c01 += a0 * b1;
c02 += a0 * b2;
c03 += a0 * b3;
c10 += a1 * b0;
c11 += a1 * b1;
c12 += a1 * b2;
c13 += a1 * b3;
c20 += a2 * b0;
c21 += a2 * b1;
c22 += a2 * b2;
c23 += a2 * b3;
c30 += a3 * b0;
c31 += a3 * b1;
c32 += a3 * b2;
c33 += a3 * b3;
}
C[(ii + 0) * n + (jj + 0)] = c00;
C[(ii + 0) * n + (jj + 1)] = c01;
C[(ii + 0) * n + (jj + 2)] = c02;
C[(ii + 0) * n + (jj + 3)] = c03;
C[(ii + 1) * n + (jj + 0)] = c10;
C[(ii + 1) * n + (jj + 1)] = c11;
C[(ii + 1) * n + (jj + 2)] = c12;
C[(ii + 1) * n + (jj + 3)] = c13;
C[(ii + 2) * n + (jj + 0)] = c20;
C[(ii + 2) * n + (jj + 1)] = c21;
C[(ii + 2) * n + (jj + 2)] = c22;
C[(ii + 2) * n + (jj + 3)] = c23;
C[(ii + 3) * n + (jj + 0)] = c30;
C[(ii + 3) * n + (jj + 1)] = c31;
C[(ii + 3) * n + (jj + 2)] = c32;
C[(ii + 3) * n + (jj + 3)] = c33;
}
}
}
}
}
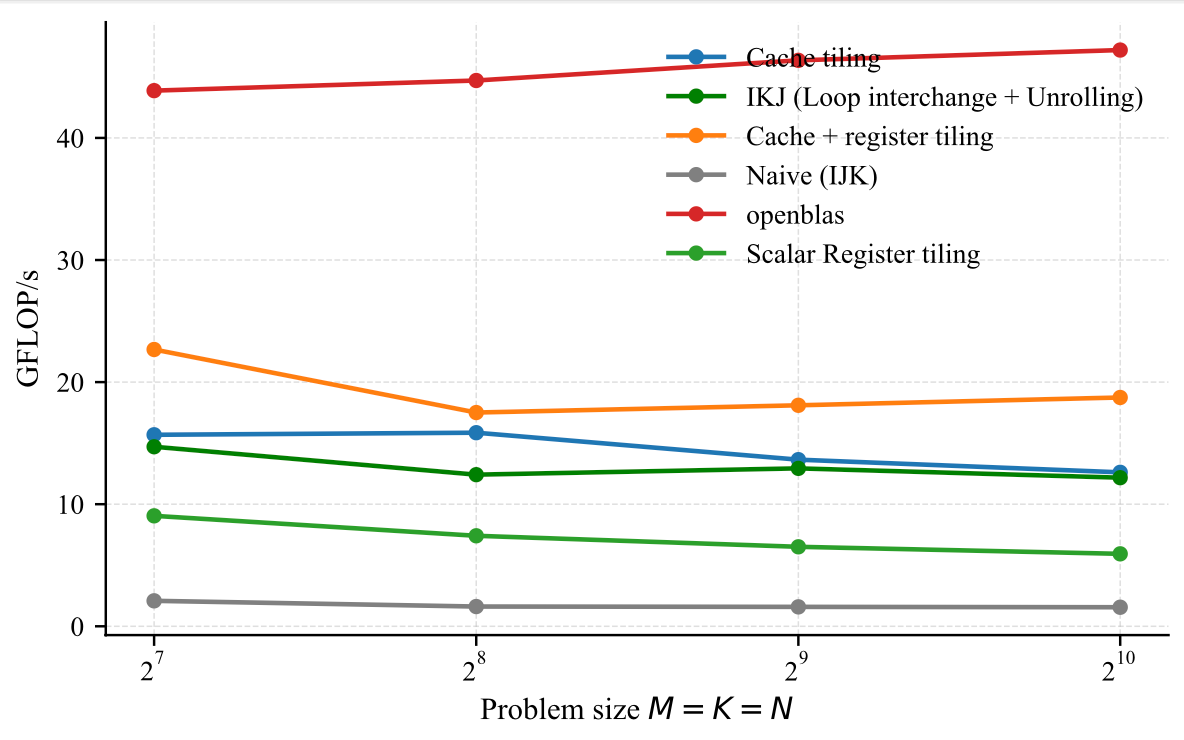
}If we look at the performance, we have closed a bit the gap but we are still far behind openblas; yes I was desperate at some point but we don't give up and lets see how to can we get close to openblas by writing a code that looks close to high computational kernels.
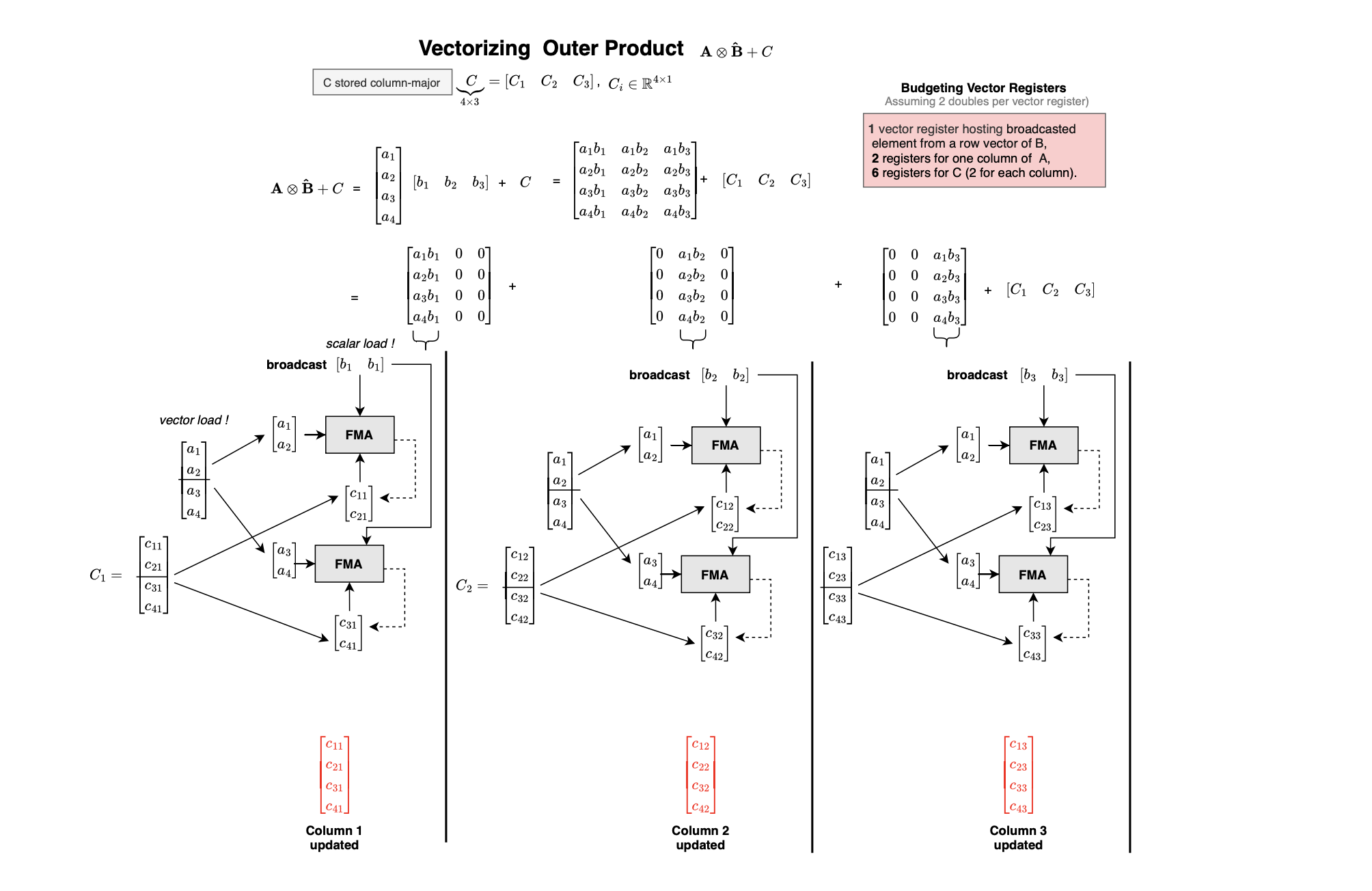
Most high-performance code is written using in-lined assembly code (e.g openblas or blis microkernel) or using vector intrinsic functions that enable access the vector instructions and vector registers within the c programming language. The microkernel code is listed below.
void matmul_micro_kernel_4x8(
const double *restrict A,
const double *restrict B,
double *restrict C,
int64_t n)
{
const int64_t m_c = 64, n_c = 64, k_c = 64;// this can be determined using analytic or empirical approach
// it is assumed that n is larger thatn 64 and power of two
#pragma omp parallel
{
size_t size_Ac = m_c * k_c;
size_t size_Bc = k_c * n_c;
size_t pad = 8;
double *base = NULL;
posix_memalign((void**)&base, 64,
(size_Ac + size_Bc + pad) * sizeof(double));
double *A_c = base;
double *B_c = base + size_Ac + pad;
#pragma omp for schedule(static)
for (int64_t iii = 0; iii < n; iii += m_c) {
for (int64_t kkk = 0; kkk < n; kkk += k_c) {
// we pack A_c by column and A is originally stored using row major layout
// this maps to Ac = A(iii:iii+mc-1, kkk:kkk+kc-1)
// i.e Ac(0,0) = A(iii,kkk) = A[iii*n + kkk]
// and thus Ac(k,i) = A(iii + i,kkk+k) = A[(iii+i)*n + kkk+k] and this explains the code below
for (int64_t k = 0 ; k < k_c; ++k) {
for (int64_t i = 0; i < m_c; ++i) {
A_c[k * m_c + i] = A[(iii + i) * n + (kkk + k)];
}
}
for (int64_t jjj = 0; jjj < n; jjj += n_c) {
// B is already stored using row major layout so we merely just copy the block
// Bc(k,j) = B(kkk+k,jjj+j) = B[(kkk+k)*n + jjj+j]
for (int64_t k = 0; k < k_c; ++k) {
for (int64_t j = 0; j < n_c; ++j) {
B_c[k * n_c + j] = B[(kkk + k) * n + (jjj + j)];
}
}
for (int64_t ii = iii; ii < iii + m_c; ii += 4) {
for (int64_t jj = jjj; jj < jjj + n_c; jj += 8) {
// as explained micro tile C is resident so we load the 4x8 micro tile
// for each row we need 4 registers i.e one register for each two consecutive elements
// and we use axpy ops on the rows not colomns
// because C is stored using row major layout
// below is one row (c00 is first row and c00_i is block if row 0)
float64x2_t c00_0 = vld1q_f64(&C[(ii+0)*n + jj + 0]);
float64x2_t c00_1 = vld1q_f64(&C[(ii+0)*n + jj + 2]);
float64x2_t c01_0 = vld1q_f64(&C[(ii+0)*n + jj + 4]);
float64x2_t c01_1 = vld1q_f64(&C[(ii+0)*n + jj + 6]);
float64x2_t c10_0 = vld1q_f64(&C[(ii+1)*n + jj + 0]);
float64x2_t c10_1 = vld1q_f64(&C[(ii+1)*n + jj + 2]);
float64x2_t c11_0 = vld1q_f64(&C[(ii+1)*n + jj + 4]);
float64x2_t c11_1 = vld1q_f64(&C[(ii+1)*n + jj + 6]);
float64x2_t c20_0 = vld1q_f64(&C[(ii+2)*n + jj + 0]);
float64x2_t c20_1 = vld1q_f64(&C[(ii+2)*n + jj + 2]);
float64x2_t c21_0 = vld1q_f64(&C[(ii+2)*n + jj + 4]);
float64x2_t c21_1 = vld1q_f64(&C[(ii+2)*n + jj + 6]);
float64x2_t c30_0 = vld1q_f64(&C[(ii+3)*n + jj + 0]);
float64x2_t c30_1 = vld1q_f64(&C[(ii+3)*n + jj + 2]);
float64x2_t c31_0 = vld1q_f64(&C[(ii+3)*n + jj + 4]);
float64x2_t c31_1 = vld1q_f64(&C[(ii+3)*n + jj + 6]);
// now that all the micro tiles are loaded in vector registers
// we start doing rank-1 updates for all
// I use unrolling with factor 2
for (int64_t k = 0; k < k_c; k += 2) {
// unroll factor k
//C[ii:ii+m_r-1, jj:jj+n_r-1] +=
// Ac[ii-iii:ii-iii+m_r-1, k] *
// Bc[k, jj-jjj:jj-jjj+n_r-1]
float64x2_t br_0 = vld1q_f64(&B_c[(k + 0) * n_c + (jj - jjj) + 0]);
float64x2_t br_2 = vld1q_f64(&B_c[(k + 0) * n_c + (jj - jjj) + 2]);
//load second part of the row of b
float64x2_t br_4 = vld1q_f64(&B_c[(k + 0) * n_c + (jj - jjj) + 4]);
float64x2_t br_6 = vld1q_f64(&B_c[(k + 0) * n_c + (jj - jjj) + 6]);
// I repeat it here for convenience
//C[ii:ii+m_r-1, jj:jj+n_r-1] +=
// Ac[ii-iii:ii-iii+m_r-1, k] *
// Bc[k, jj-jjj:jj-jjj+n_r-1]
double *ar = &A_c[(k + 0) * m_c + (ii - iii)];
// because C is stored using row major layout we must brodcast a and not b
// you can do the math to convice yourself
// we load one column of Ac which demands two vector registers for the 4 elements as mr =4
float64x2_t ar0 = vld1q_f64(ar);
float64x2_t ar1 = vld1q_f64(ar + 2);
// axpy ops
float64x2_t ar00 = vdupq_laneq_f64(ar0, 0);
c00_0 = vfmaq_f64(c00_0, ar00, br_0);
c00_1 = vfmaq_f64(c00_1, ar00, br_2);
c01_0 = vfmaq_f64(c01_0, ar00, br_4);
c01_1 = vfmaq_f64(c01_1, ar00, br_6);
float64x2_t ar01 = vdupq_laneq_f64(ar0, 1);
c10_0 = vfmaq_f64(c10_0, ar01, br_0);
c10_1 = vfmaq_f64(c10_1, ar01, br_2);
c11_0 = vfmaq_f64(c11_0, ar01, br_4);
c11_1 = vfmaq_f64(c11_1, ar01, br_6);
float64x2_t ar10 = vdupq_laneq_f64(ar1, 0);
c20_0 = vfmaq_f64(c20_0, ar10, br_0);
c20_1 = vfmaq_f64(c20_1, ar10, br_2);
c21_0 = vfmaq_f64(c21_0, ar10, br_4);
c21_1 = vfmaq_f64(c21_1, ar10, br_6);
float64x2_t ar11 = vdupq_laneq_f64(ar1, 1);
c30_0 = vfmaq_f64(c30_0, ar11, br_0);
c30_1 = vfmaq_f64(c30_1, ar11, br_2);
c31_0 = vfmaq_f64(c31_0, ar11, br_4);
c31_1 = vfmaq_f64(c31_1, ar11, br_6);
// now we do the same as above but for the second unroll factor k+1
float64x2_t br1_0 = vld1q_f64(&B_c[(k + 1) * n_c + (jj - jjj) + 0]);
float64x2_t br1_2 = vld1q_f64(&B_c[(k + 1) * n_c + (jj - jjj) + 2]);
float64x2_t br1_4 = vld1q_f64(&B_c[(k + 1) * n_c + (jj - jjj) + 4]);
float64x2_t br1_6 = vld1q_f64(&B_c[(k + 1) * n_c + (jj - jjj) + 6]);
double *ar_1 = &A_c[(k + 1) * m_c + (ii - iii)];
float64x2_t ar1_0 = vld1q_f64(ar_1);
float64x2_t ar1_2 = vld1q_f64(ar_1 + 2);
float64x2_t ar1_00 = vdupq_laneq_f64(ar1_0, 0);
c00_0 = vfmaq_f64(c00_0, ar1_00, br1_0);
c00_1 = vfmaq_f64(c00_1, ar1_00, br1_2);
c01_0 = vfmaq_f64(c01_0, ar1_00, br1_4);
c01_1 = vfmaq_f64(c01_1, ar1_00, br1_6);
float64x2_t ar1_01 = vdupq_laneq_f64(ar1_0, 1);
c10_0 = vfmaq_f64(c10_0, ar1_01, br1_0);
c10_1 = vfmaq_f64(c10_1, ar1_01, br1_2);
c11_0 = vfmaq_f64(c11_0, ar1_01, br1_4);
c11_1 = vfmaq_f64(c11_1, ar1_01, br1_6);
float64x2_t ar1_20 = vdupq_laneq_f64(ar1_2, 0);
c20_0 = vfmaq_f64(c20_0, ar1_20, br1_0);
c20_1 = vfmaq_f64(c20_1, ar1_20, br1_2);
c21_0 = vfmaq_f64(c21_0, ar1_20, br1_4);
c21_1 = vfmaq_f64(c21_1, ar1_20, br1_6);
float64x2_t ar1_21 = vdupq_laneq_f64(ar1_2, 1);
c30_0 = vfmaq_f64(c30_0, ar1_21, br1_0);
c30_1 = vfmaq_f64(c30_1, ar1_21, br1_2);
c31_0 = vfmaq_f64(c31_0, ar1_21, br1_4);
c31_1 = vfmaq_f64(c31_1, ar1_21, br1_6);
}
// after ranks updates we store the microtile C 4x8
vst1q_f64(&C[(ii+0)*n + jj + 0], c00_0);
vst1q_f64(&C[(ii+0)*n + jj + 2], c00_1);
vst1q_f64(&C[(ii+0)*n + jj + 4], c01_0);
vst1q_f64(&C[(ii+0)*n + jj + 6], c01_1);
vst1q_f64(&C[(ii+1)*n + jj + 0], c10_0);
vst1q_f64(&C[(ii+1)*n + jj + 2], c10_1);
vst1q_f64(&C[(ii+1)*n + jj + 4], c11_0);
vst1q_f64(&C[(ii+1)*n + jj + 6], c11_1);
vst1q_f64(&C[(ii+2)*n + jj + 0], c20_0);
vst1q_f64(&C[(ii+2)*n + jj + 2], c20_1);
vst1q_f64(&C[(ii+2)*n + jj + 4], c21_0);
vst1q_f64(&C[(ii+2)*n + jj + 6], c21_1);
vst1q_f64(&C[(ii+3)*n + jj + 0], c30_0);
vst1q_f64(&C[(ii+3)*n + jj + 2], c30_1);
vst1q_f64(&C[(ii+3)*n + jj + 4], c31_0);
vst1q_f64(&C[(ii+3)*n + jj + 6], c31_1);
}
}
}
}
}
free(base);
}
}
We use vld1q_f64() and vst1q_f64() to load and store vectors of two doubles, respectively. The intrinsic vdupq_laneq_f64() is used to broadcast a selected lane across all elements of a vector, and vfmaq_f64() performs a fused multiply-add or fma operation on vectors. Before using these intrinsic functions, you must include the header file #include <arm_neon.h>. In order to reduce cache misses, A and B panels are packed using colomn and row major layout respectively.
Looking at the performance plot, we have significantly closed the gap.
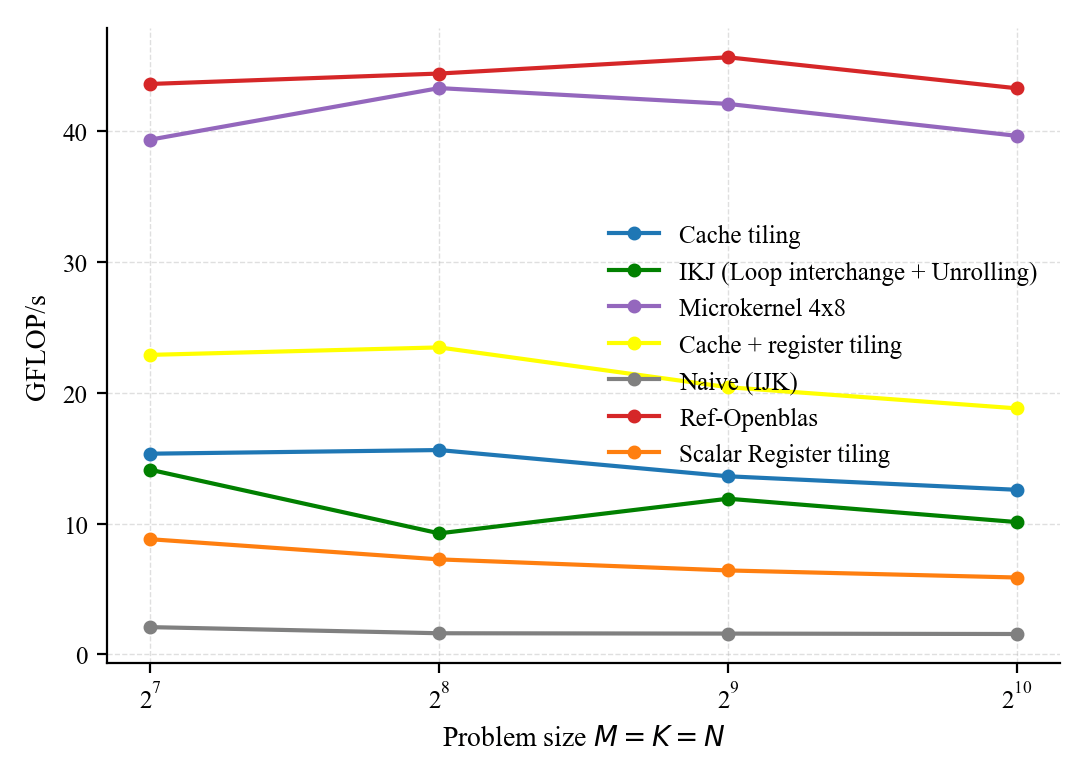
We can even improve further the performance using multithreading (using OpenMP for instance). The performance for both our custom micro kernel and openblas is show below (remember that our micro kernel assumes ideal sizes and comparison here is not really very fair; but again the goal is not to compete with openblas and to develop a library, instead the post aims to illustrate how fast GEMM are implemented).
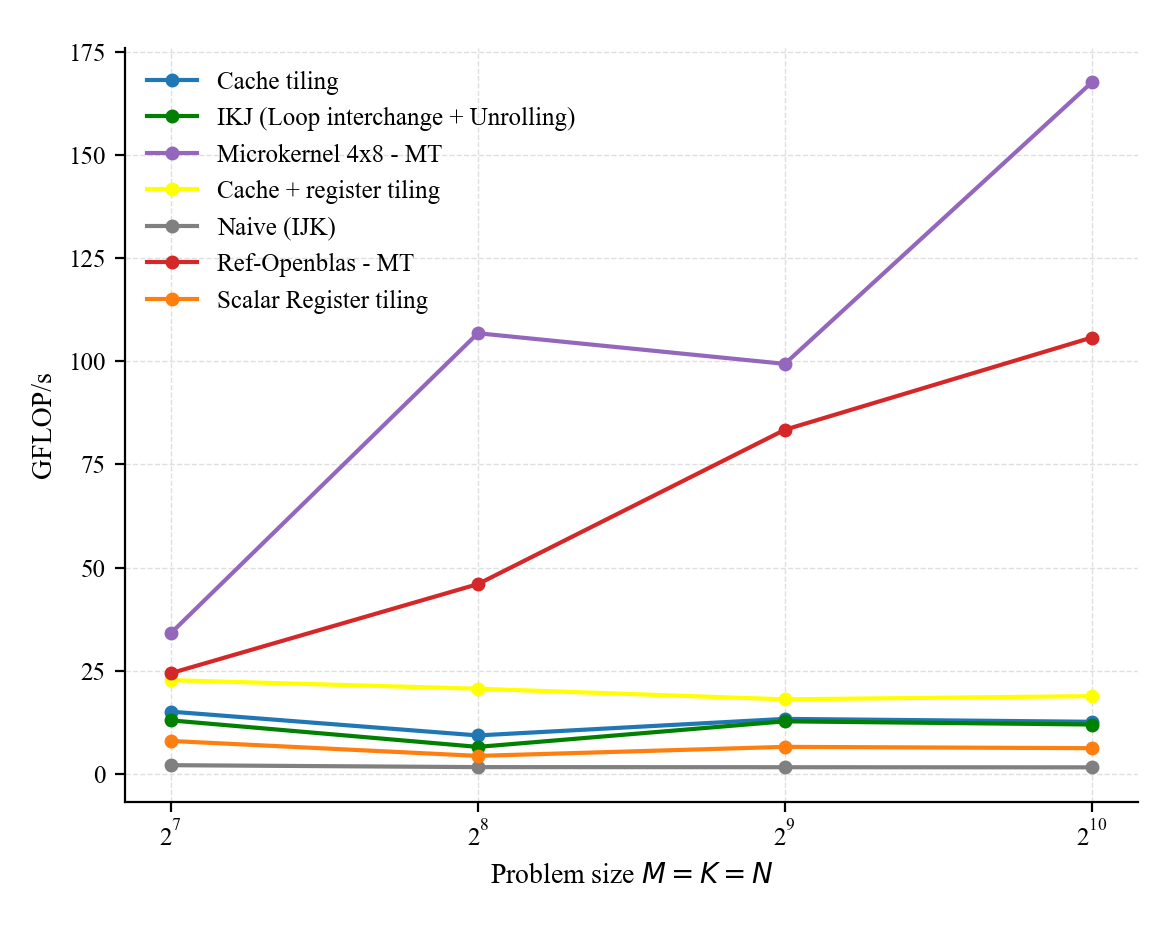
I did not really test prefetching but it can help a bit to overlap computation and data movement (and thus reduces the number of cycles required to perform the mult). Note however that prefetching does not increasing operational or arithmetic intensity as the blocks are still loaded in the cache (it is just when).
In addition to the NEON ISA, the Apple M1 supports AMX (Advanced Matrix Extensions) [6], as in other Apple Silicon M-series chips. AMX is an undocumented, specialized Apple matrix coprocessor controlled via dedicated cpu instructions, capable of accelerating matrix–matrix products (e.g., via outer-product computations) by an order of magnitude. Although not publicly documented, AMX can be utilized through the Accelerate framework’s BLAS routines, which provide highly optimized libraries. As shown below, Accelerate outperforms OpenBLAS for all FP64 matrix–matrix multiplication problem sizes. This is not a surprise, as OpenBLAS relies on 128-bit NEON instructions.
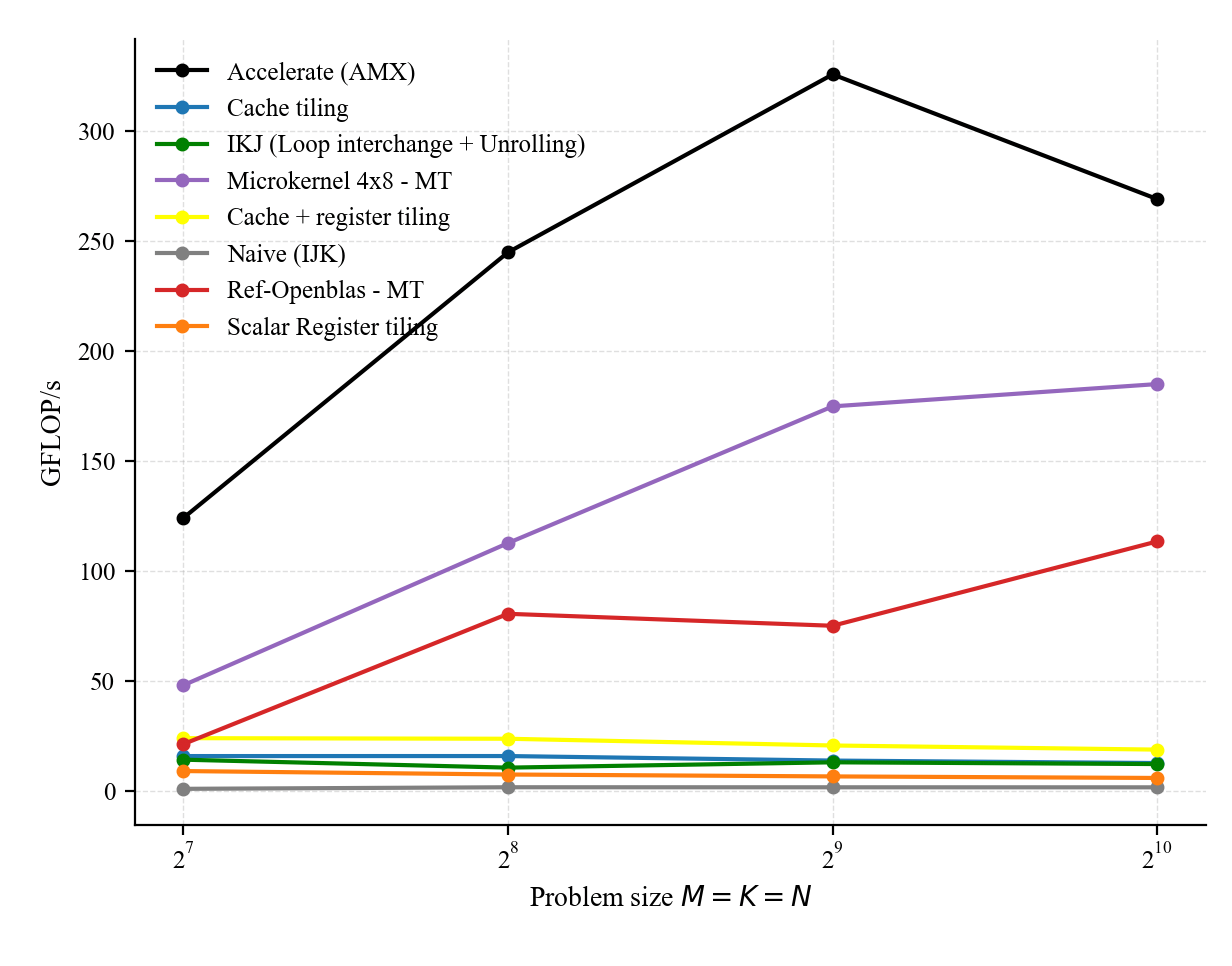
If we look at the blocking strategy used in OpenBLAS for the DGEMM routine [https://github.com/OpenMathLib/OpenBLAS/blob/develop/driver/level3/level3.c]:
void cblas_dgemm(const CBLAS_LAYOUT layout, const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N,
const int K, const double alpha, const double *A,
const int lda, const double *B, const int ldb,
const double beta, double *C, const int ldc)It computes the classic GEMM operation \( C = \alpha AB + \alpha C\). The implementation begins by allocating a contiguous buffer used for packing sub-blocks of matrices A and B and reduce cache conflict misses:
buffer = (XFLOAT *)blas_memory_alloc(0);
#if defined(ARCH_LOONGARCH64) && !defined(NO_AFFINITY)
sa = (XFLOAT *)((BLASLONG)buffer + (WhereAmI() & 0xf) * GEMM_OFFSET_A);
#else
sa = (XFLOAT *)((BLASLONG)buffer + GEMM_OFFSET_A);
#endif
sb = (XFLOAT *)(((BLASLONG)sa +
((GEMM_P * GEMM_Q * COMPSIZE * SIZE + GEMM_ALIGN) & ~GEMM_ALIGN))
+ GEMM_OFFSET_B);Here, sa and sb are buffers that hold packed panels of A and B, respectively. As discussed earlier, packing is critical as it ensures contiguous memory access within the compute kernel. The core computation is implemented using a blocking strategy. While the loop structure does not exactly follow the canonical GotoBLAS algorithm formulation, the same principles applies, multilevel tiling and data packing. The algorithm iterate over tiles:
for(js = n_from; js < n_to; js += GEMM_R){
...
for(ls = 0; ls < k; ls += min_l){
...
for(is = m_from + min_i; is < m_to; is += min_i) Packs subblocks:
ICOPY_OPERATION(..., sa);and invoke the micro-kernel:
KERNEL_OPERATION(min_i, min_jj, min_l, (void *)&xalpha,..)Specifically the macro-kernel delegates computation to architecture-specific micro-kernels in our case it is dgemm_kernel_8x4.S which implement rank-1 updates using vector instructions. For more details, please see the OpenBLAS kernel source: https://github.com/OpenMathLib/OpenBLAS/blob/develop/kernel/arm64/dgemm_kernel_8x4.S
The diagram below summarizes the structure of modern high-performance GEMM implementations. Each level of the loop nest corresponds to a level of the memory hierarchy, large panels are kept in higher-level caches (L3/L2), while progressively smaller tiles are brought closer to the processor until the micro-kernel operates entirely on data resident in registers.
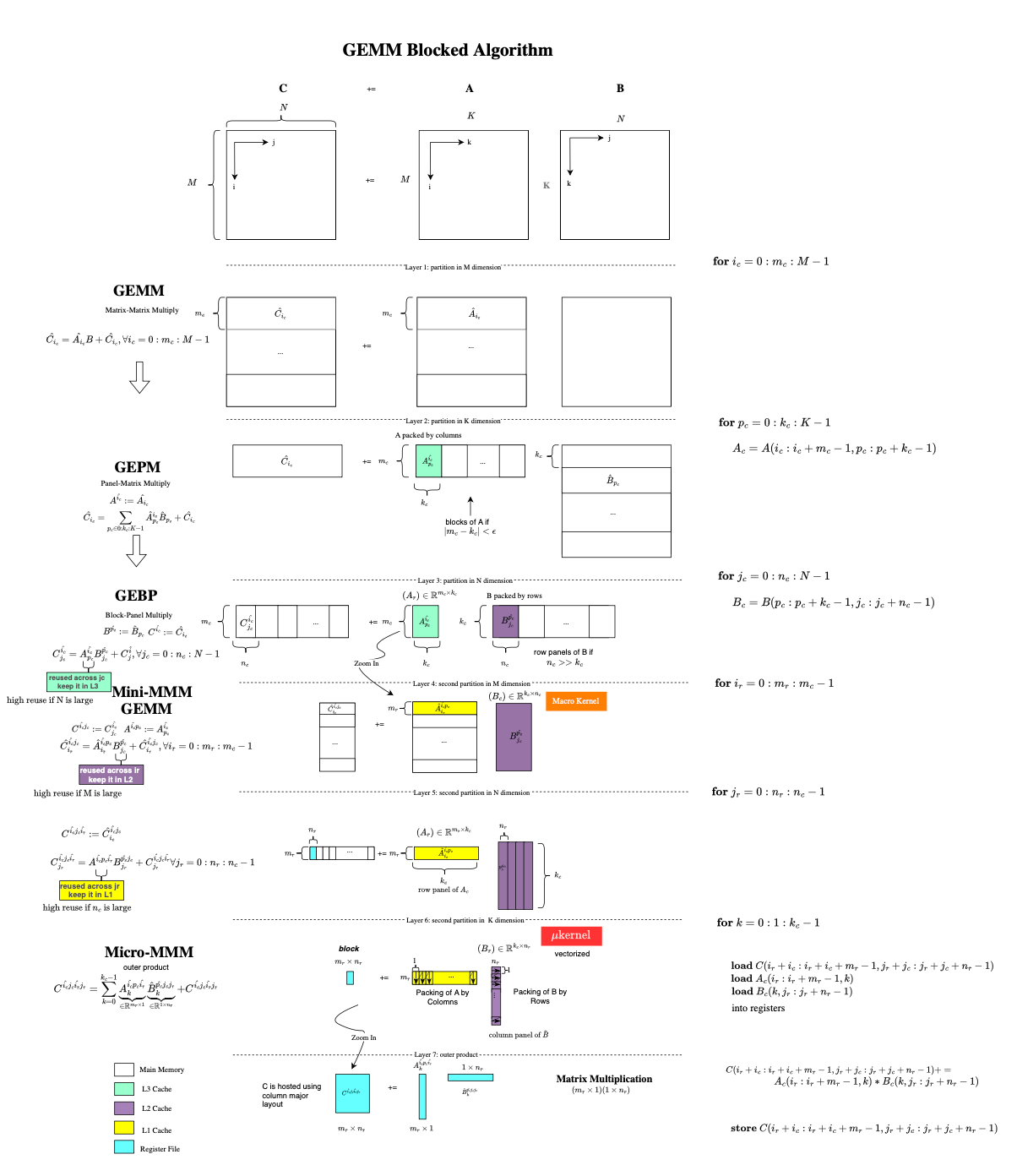
Please, if you think you found a mistake, please feel free to reach out.
The experiments can be reproduced at : https://github.com/mouadk/hpc-dgemm.
In the next posts (hopefully coming very soon), we will explore GPU and hardware-accelerated matrix multiplication, along with how different deep learning models, including generative and discriminative, are trained (i.e via backpropagation and MLE) and how inference is performed and accelerated at runtime, building on the foundation we would have developed so far.
[1] https://www.netlib.org/blas/blast-forum/blas-report.pdf
[2] https://en.wikipedia.org/wiki/Vector_processor
[3] https://en.wikipedia.org/wiki/Cholesky_decomposition
[4] https://en.wikipedia.org/wiki/Polytope_model
[5] https://mrmgroup.cs.princeton.edu/papers/toplas-ghosh.pdf
[6] https://en.wikipedia.org/wiki/Advanced_Matrix_Extensions
[7] https://en.wikipedia.org/wiki/Prefetching
[8] https://en.wikipedia.org/wiki/Loop_unrolling
[9] https://en.wikipedia.org/wiki/Transformer_(deep_learning)
[10] https://en.wikipedia.org/wiki/Register_renaming
[11] https://en.wikipedia.org/wiki/Single_instruction,_multiple_data
[12] https://en.wikipedia.org/wiki/Roofline_model
[13] https://en.wikipedia.org/wiki/Long_short-term_memory
[14] https://en.wikipedia.org/wiki/Loop_nest_optimization
[15] https://www.ibspan.waw.pl//~paprzyck/mp/cvr/education/papers/ESCCC_92.pdf
[16] https://arxiv.org/pdf/2301.10852
[17] https://www.cs.utexas.edu/~pingali/CS395T/2013fa/papers/MMMvdg.pdf
[18] https://www.cs.utexas.edu/~flame/pubs/GotoTOMS_revision.pdf
[19] https://en.algorithmica.org/hpc/algorithms/matmul/
[20] https://salykova.github.io/matmul-cpu
[21] https://github.com/OpenMathLib/OpenBLAS
[22] https://users.ece.cmu.edu/~franzf/papers/gttse07.pdf
[23] https://pages.saclay.inria.fr/olivier.temam/files/eval/PTV02.pdf