This post summarizes the main implementation patterns used by modern multi-agent frameworks including agents-as-tools, handoffs, routing, reflection, group chat, debate, Magentic-style ledger orchestration, dynamic subagent spawning, and mixture-of-agents architectures. The Brain: Foundation Models Well, the first thing we need to build an agent is a foundation model, for example GPT‑

Introduction A straightforward approach to augment large language models or LLMs with new capabilities is through in-context learning. The model is provided with a small number of examples that demonstrate how to solve a task, after which it generates a response using its inherent capabilities combined with the knowledge embedded
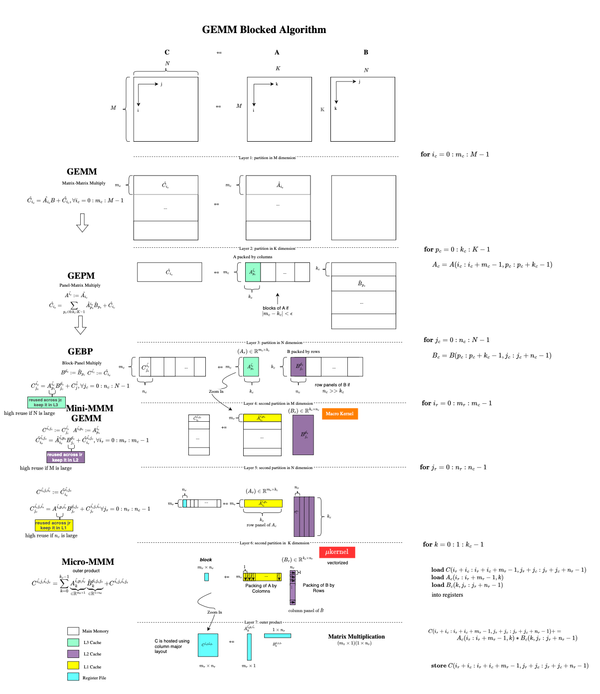
Implementing highly efficient matrix multiplication routines that approach peak performance demands significant effort, strong linear algebra knowledge, and a deep understanding of the underlying hardware architecture (even down to the microarchitectural level[23]). This is why vendors provide highly optimized implementations of the Basic Linear Algebra Subprograms (BLAS)[1], including
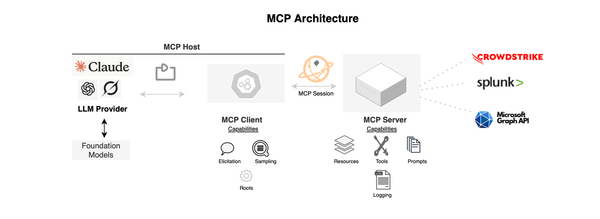
Whether you are an AI engineer or working on workflow automation, you probably know how much attention the MCP or Model Context Protocol has attracted recently; thanks to the AI hype cycle. Since its introduction by Anthropic, it has gained real momentum, supported by a vibrant community ecosystem with thousands
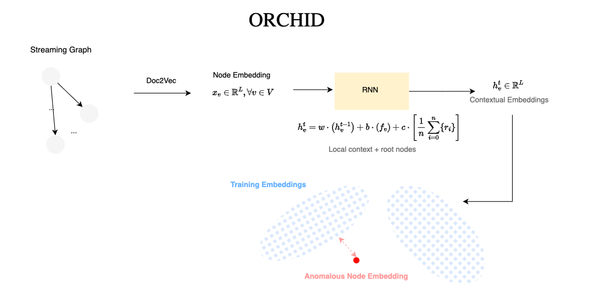
During the last few months, I spent a significant amount of time reviewing system modeling literature and exploring the current advancements in this area of research. Specifically, my goal was to apply advanced machine learning including deep learning techniques to efficiently represent system events in a euclidean space and detect
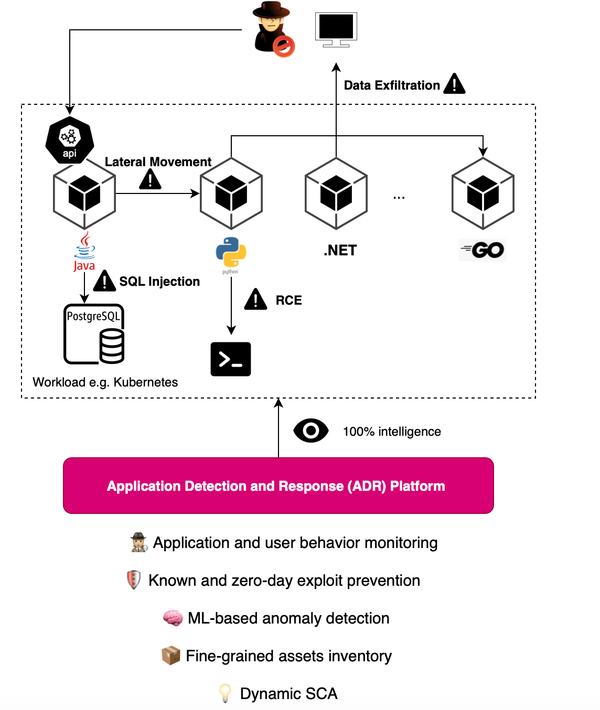
Few companies are starting to pave the way for Application and Detection Response (ADR) including Oligo Security, RevealSecurity and Miggo Security. You may find yourself quickly lost in understanding what these solutions aim to tackle. First, each of these solutions likely focuses on what they do best. For example, Oligo
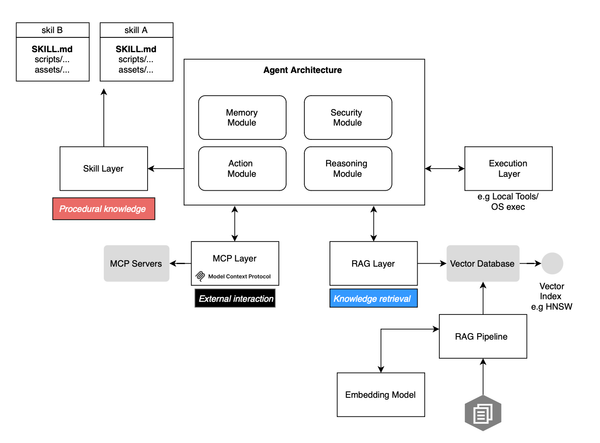
Large Language Models (LLMs) have evolved from being merely passive text generators with limited capabilities to becoming autonomous or semi-autonomous agents navigating complex environments and offering actionable insights. This transformation equips them with a diverse set of tools, perception modules to interpret signals from various modalities, and memory systems to
Multimodal Large Language Models (MLLMs) are garnering significant attention. There has been a plethora of work in recent months dedicated to the development of MLLMs [Flamingo, NExT-GPT, Gemini...]. The key challenge for MLLMs lies in effectively injecting multimodal-data in LLMs. Most research begins with pre-trained LLMs and employs modality-specific encoders
Large Language Models (LLMs) are developed to understand the probability distribution that governs the world language space. Autoregressive models approximate this distribution by predicting subsequent words based on previous context, forming a Markov chain. World knowledge (often referred as parametric knowledge) is stored implicitly within the model's parameters.