This post summarizes the main implementation patterns used by modern multi-agent frameworks including agents-as-tools, handoffs, routing, reflection, group chat, debate, Magentic-style ledger orchestration, dynamic subagent spawning, and mixture-of-agents architectures. The Brain: Foundation Models Well, the first thing we need to build an agent is


This post summarizes the main implementation patterns used by modern multi-agent frameworks including agents-as-tools, handoffs, routing, reflection, group chat, debate, Magentic-style ledger orchestration, dynamic subagent spawning, and mixture-of-agents architectures.
Well, the first thing we need to build an agent is a foundation model, for example GPT‑5.2.
A foundation model is basically an autoregressive model trained on an astonishing corpus of data. It goes through several phases of training to better comprehend the distribution of natural language and also learn how to follow instructions and human values.
Using prompting, we can guide the model into following a certain path conditioned on the conversation history. It is really important to understand that choosing a model is critical for performance. For example, you could have very poor performance with GPT-4.1-mini, and once you transition to GPT-5.5, the results could be completely or slightly different. This is because each model has different reasoning capabilities and, if you will, brain power.
If you have a less powerful model, it would be better to invest in retrieval, as you are less dependent on the LLM’s internal knowledge and reasoning ability.

LLMs, as briefly mentioned above, are trained to predict the next token and thus comprehend the distribution that governs the world language space. Additionally, LLMs are trained to follow instructions; for instance, if you ask a model to output a given format, it will likely follow your prompt.
LLMs are not trained continually, and thus equipping them with tools can augment their capabilities to interact with the environment around them. For example, it could be as simple as orchestrating tool calls with parameters to collect security context around an event.
This is basically known as function calling; most LLM providers can now be provided with a list of tools and schemas, and the foundation model, via the API, will return tool calls that can be scheduled in parallel or not. This is the key to building agentic systems. Most multi-agent frameworks use tool calls for handoffs, spawning subagents etc.
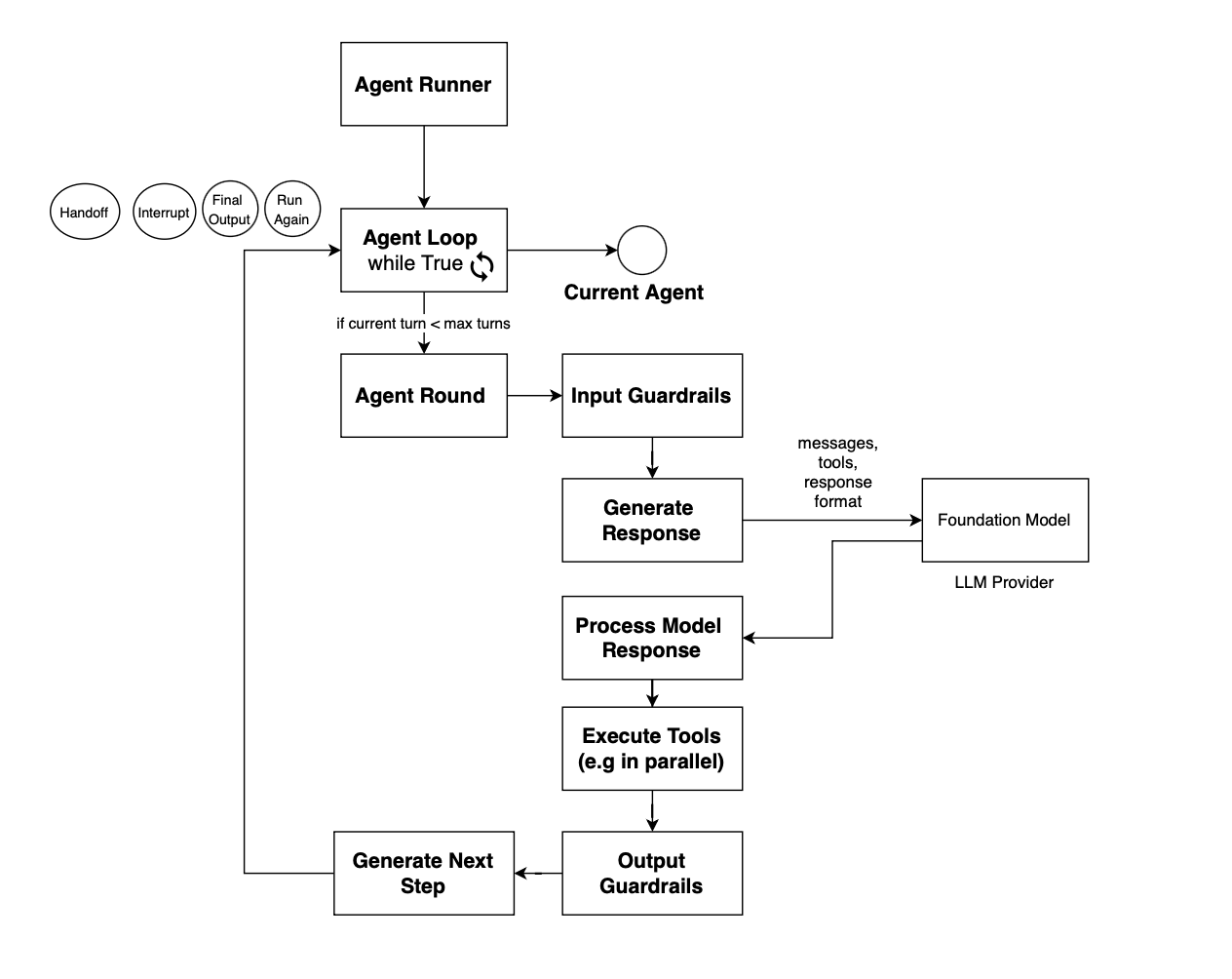
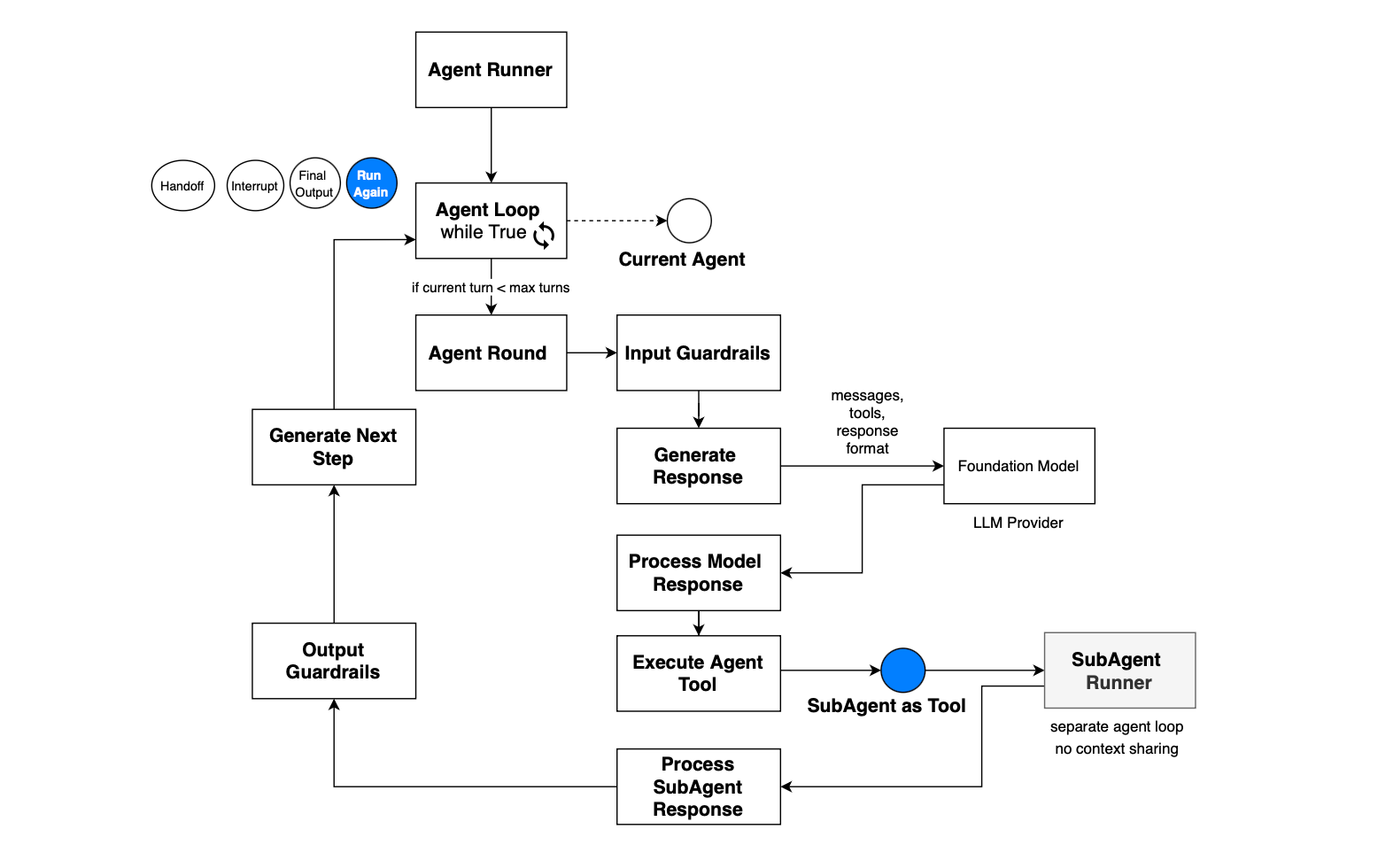
Once equipped with function-calling capabilities, well, you can just stack multiple calls to the foundation model, enabling it to self-reflect on current items, and then you get an agent. The loop stacking LLM calls is referred to as the agent loop and can be made stoppable if a max epoch is reached or no tool call is emitted. The implementation of an agent loop is really framework specific.
In OpenAI agent SDK, this is what the agent loop looks like:
In the Microsoft Agent Framework, the tool-calling loop is defined at the FunctionInvocationLayer. The loop starts inside get_response:
def get_response(
self,
messages: Sequence[Message],
...
):
loop_enabled = self.function_invocation_configuration.get("enabled", True)
max_iterations = self.function_invocation_configuration.get(
"max_iterations",
DEFAULT_MAX_ITERATIONS,
)
for attempt_idx in range(max_iterations if loop_enabled else 0):
approval_result = await _process_function_requests(
response=None,
...
)If there is no function call, the loop terminates:
if not (function_calls and tools):
_prepend_fcc_messages(response, fcc_messages)
return {
"action": "return",
"errors_in_a_row": errors_in_a_row,
"result_message": None,
"update_role": None,
"function_call_results": None,
"function_call_count": 0,
}
Otherwise, the requested tools are executed. The loop may also terminate if any tool result signals termination:
# If any function requested termination, terminate the loop
should_terminate = any(result[1] for result in execution_results)So the function invocation loop is essentially, call model, inspect response for function calls, if no function calls, return response, execute requested tools, append function-call results, check whether any tool requested termination if terminated, return otherwise call model again and repeat until max_iterations.
The agent loop is triggered from the agent executor, for example when a message is delivered that requires the agent’s attention. Once the agent loop terminates, control returns to the executor. The executor can then decide whether to relaunch the agent, continue orchestration, hand off to another agent, or stop; depending on the underlying workflow.
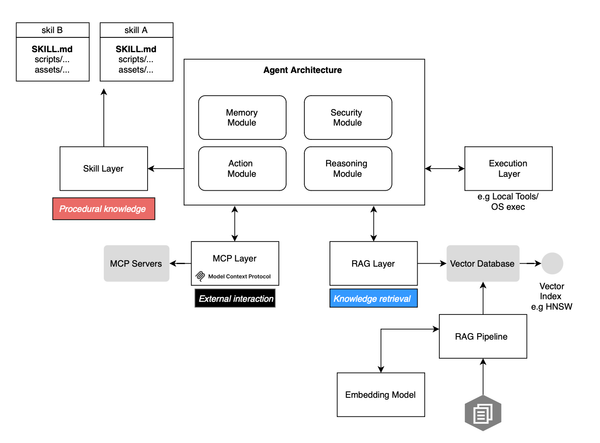
An agent tool can be a lot of things. It could be a simple local tool, for example spawning a pod in Kubernetes, or an MCP call.
RAG is heavily used in modern agent systems for several reasons. First, the neural embedding space can be used to find only information semantically relevant to the current query, thus reducing noise, especially since the context window is limited and noise can mess with the token generation path. Second, RAG can help when there is no API available to fetch some unstructured data, so you can just create your index and then apply neural retrieval on top. Third, it reduces round trips if the agent were to iteratively go through all the data to find a response for a given query.
Skills, introduced recently, help with workflow reuse; basically, instead of sending the prompt with all possible paths the agent may take, for example for investigation, triage, or incident response, it could just load that skill. If you look at strix, several skills are introduced to guide the pentesting task, and the model or agent if you will can load them when deemed relevant.
In this case, the skill itself is a tool, and then the description of the workflow is available in the near context, and the model can peek at it and follow the encoded instructions.
The agent loop may be interrupted before the agent accomplishes the task for many reasons, for example either a max turn is reached, a guardrail is triggered, or for human-in-the-loop scenarios.
For human-in-the-loop flows, when you exit the agent loop, at some point you will be back to it with the user response or approval, and thus a state of the agent needs to be maintained. This includes the reason for the interrupt, the current round, and also the context, including messages, so that the agent loop can resume.
For instance, if a tool call requires approval, then the user is prompted to approve a function call, and then the agent loop is rerun to continue from the currently saved state. When the user is prompted to provide clarification, the exact message is sent back to the model when the loop resumes, and then the loop continues until it finishes again because max turns have been reached or output is provided, i.e. no tool call is proposed by the underlying foundation model.
So what do we need to build an agent? We need a foundation model, or LLM, tools with schemas, prompts that dictate the instructions, a loop to stack LLM calls, some control around it, and also the structure of the output.
During the agent loop, a stopping condition could be raised due to max turns being reached or guardrails being triggered. The loop can also terminate in a normal fashion when the agent produces final output and no tool calls. A loop may also be interrupted due to approval requests, e.g. in human-in-the-loop scenarios; for instance, it could also ask users for more information to generate targeted answers.
Once you have an agent, you can also introduce multiple agents into your system, each specialized in a given task and with a different foundation model. Sometimes you need reasoning and thus more powerful models, while in some scenarios you can stick with a cheaper model (e.g if you just need completion and you have a high quality retrieval for the given subtask).
But then how do you connect them? In this case, each framework may use a different pattern, and you can even define your own.
But please, you can define a very simple agentic system using predictable paths. If you don’t need autonomy, do not use it. Hardcode your orchestration and use synthesis on top. Improving retrieval is usually by far more interesting to invest in than having to fight with the agent to follow a certain path that you already know!.
The first pattern in a multi-agentic system is running agents as tools. In this case, the parent or lead agent runs its own loop.
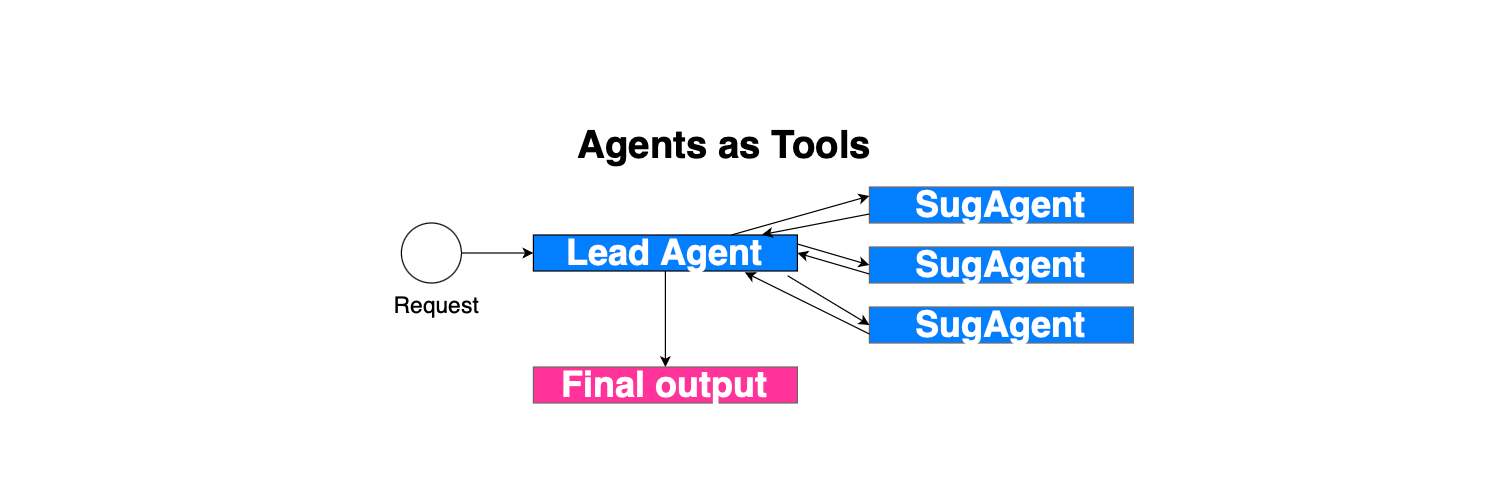
The sub-agents are exposed as tools, along with descriptions, so that the foundation model knows when and how to invoke an agent. If the model responds with a tool call referring to a sub-agent, then the sub-agent is executed with the input provided by the model, with its own loop and running environment; i.e. there is no conversation sharing. It only sees its system prompt and the input message. Next, once the sub-agent finishes, the response is added to the original context, similar to other function calls, and the parent continues.
Here is what the agentic loop looks like when when agents are exposed as tools in the OpenAI agent SDK:
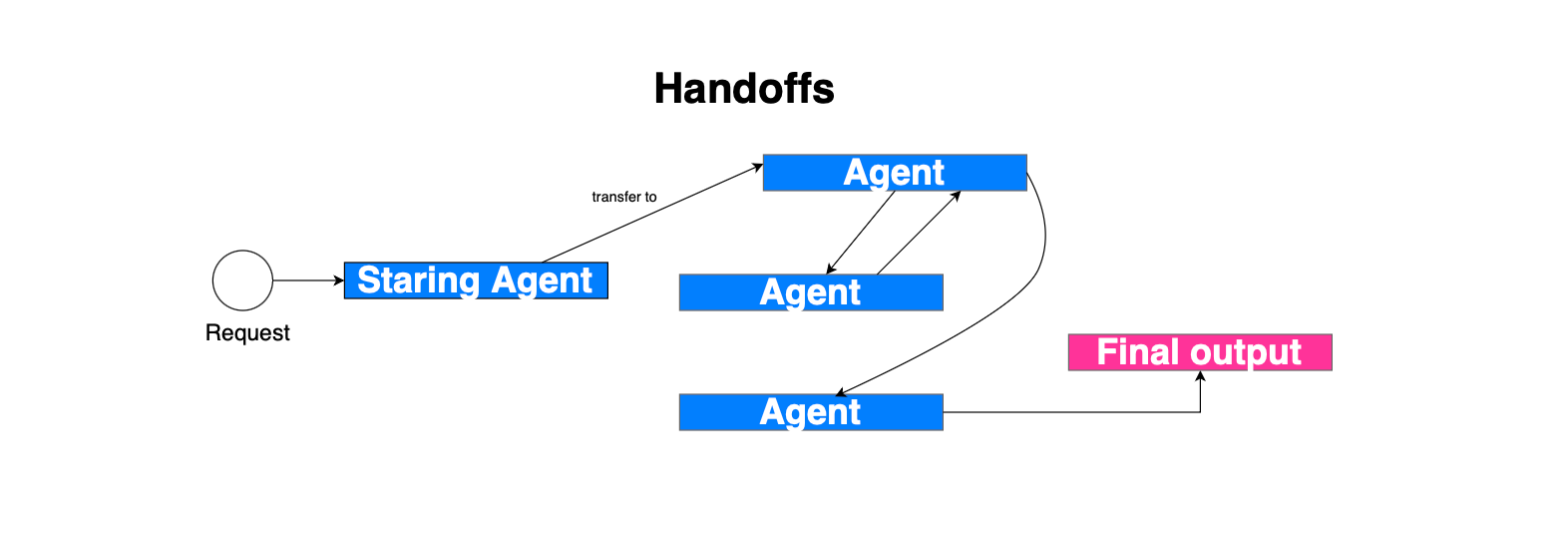
Another pattern is handoffs, where there is no reliance on a central entity or orchestrator. Basically, the idea is that during the agent loop, the model may decide to switch to another agent, i.e. transfer control to another agent. The handoff itself is exposed as a tool call, and once the model suggests a handoff, the state changes and the agent switches. The runner now runs the loop with the current agent referencing the target agent, and the system prompt is updated as well. In contrast to agents as tools, the new agent has access to the entire conversation history.
Both the agents-as-tools and handoff patterns may be combined. They are, for instance, implemented by https://github.com/openai/openai-agents-python and https://docs.langchain.com/oss/python/langchain/multi-agent/subagents. Handoff is used in Swarm: https://microsoft.github.io/autogen/stable/user-guide/agentchat-user-guide/swarm.html.
In OpenAI agent SDK, the handoff implementation consists of exposing the handoff as a tool, once executed the current agent running reference switches to point to the new target agent and the execution continue. This is depicted in the figure below.
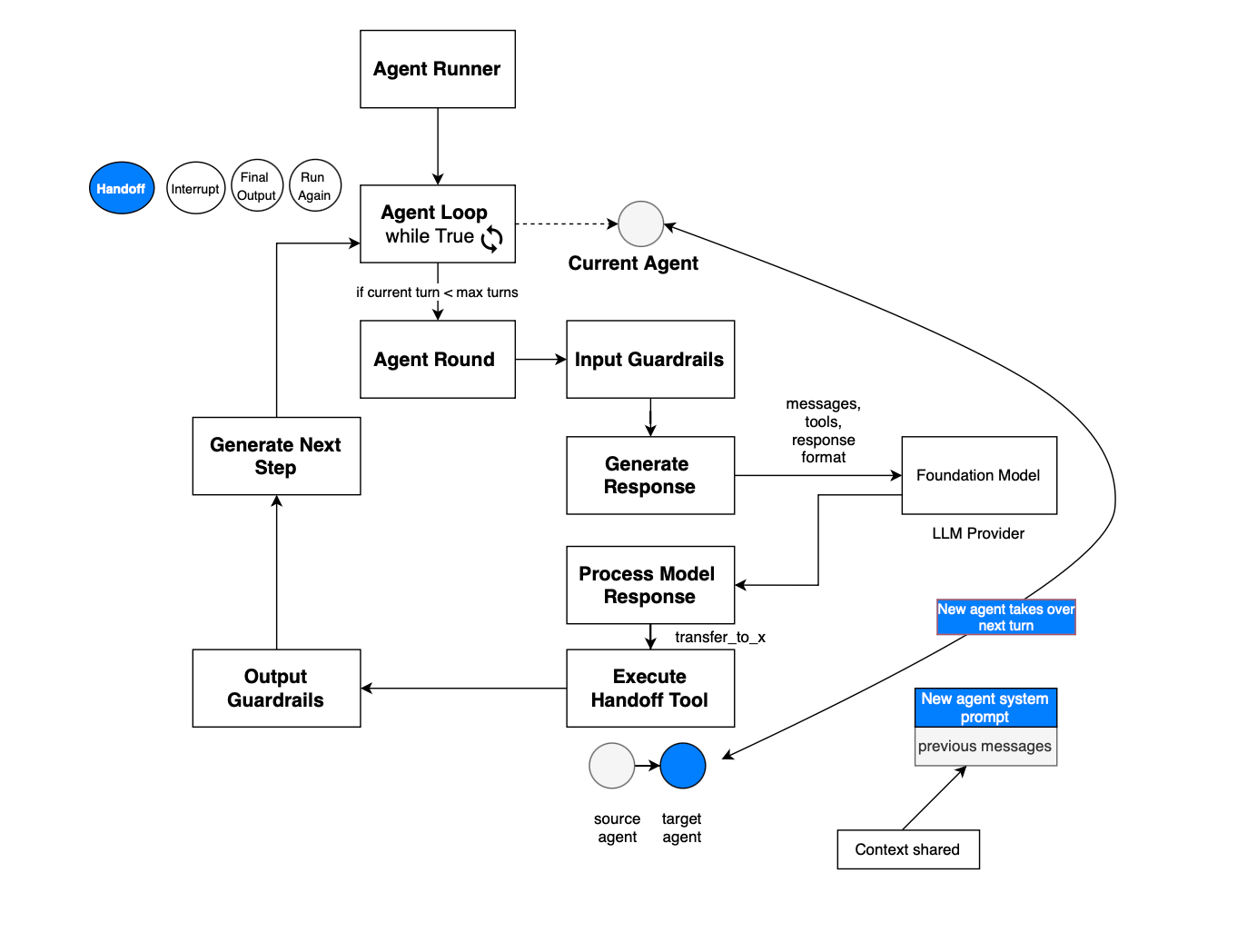
In the case of handoff, in the Microsoft agent framework, HandoffAgentExecutor is used. In autonomous mode, the agent can continue running if no handoff has been requested:
# Handle case where no handoff was requested
if (
self._autonomous_mode
and self._autonomous_mode_turns < self._autonomous_mode_turn_limit
):
# In autonomous mode, continue running the agent until a handoff is requested
# or a termination condition is met.
# This allows the agent to perform long-running tasks without returning control
# to the coordinator or user prematurely.
self._cache.extend(
[Message(role="user", contents=[self._autonomous_mode_prompt])]
)
self._autonomous_mode_turns += 1
await self._run_agent_and_emit(ctx)Basically, in autonomous mode, agents continue responding until one of the following happens, a handoff tool is invoked, a termination condition is met, the autonomous-mode turn limit is reached.
Handoffs are implemented in the framework using tools. Each agent may request a handoff by invoking the appropriate handoff tool, using the description of the target agent. When the currently running agent invokes a handoff tool, it exits its current loop and leaves the floor to the selected agent.
That target agent may then continue the workflow, perform additional reasoning or tool calls, invoke another handoff, or eventually produce the final response.
Routing is another pattern, which consists of having an LLM-based router, for example, that routes to different sub-agents, each with a dedicated input. When all the sub-agents finish, the result is combined and a synthesized response is generated: https://docs.langchain.com/oss/python/langchain/multi-agent/router.
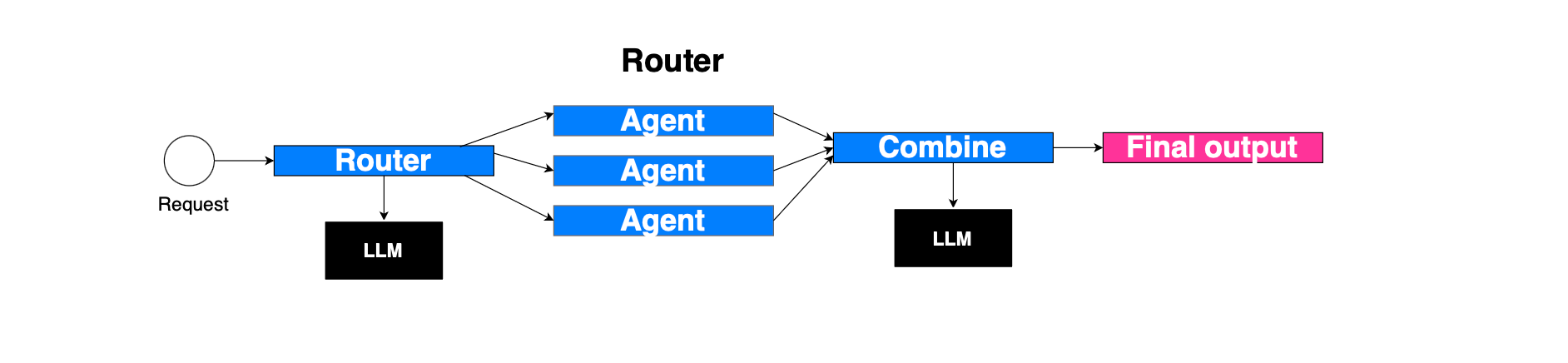
This is different from agents as tools, where the main agent governs the context and can solicit multiple sub-agents across turns. In the routing pattern, the router does not maintain the conversation history and will not be able, for instance, to call the same sub-agent across multiple turns.
The reflection pattern here is similar to having a generator agent and a discriminator agent. The first agent produces something, and the latter gives its opinion. The loop continues until the second agent approves the output or an iteration count is reached. For example, the generator could be a code snippet generator, while the second agent could be a reviewer.
An example is illustrated below; the worker agent will continue to generate a response until the response is approved (if review.approved:):
class Reviewer(Executor):
"""Executor that reviews agent responses and provides structured feedback."""
def __init__(self, id: str, client: SupportsChatGetResponse) -> None:
super().__init__(id=id)
self._chat_client = client
@handler
async def review(self, request: ReviewRequest, ctx: WorkflowContext[ReviewResponse]) -> None:
print(f"Reviewer: Evaluating response for request {request.request_id[:8]}...")
# Define structured schema for the LLM to return.
class _Response(BaseModel):
feedback: str
approved: bool
# Construct review instructions and context.
messages = [
Message(
role="system",
contents=[
(
"You are a reviewer for an AI agent. Provide feedback on the "
"exchange between a user and the agent. Indicate approval only if:\n"
"- Relevance: response addresses the query\n"
"- Accuracy: information is correct\n"
"- Clarity: response is easy to understand\n"
"- Completeness: response covers all aspects\n"
"Do not approve until all criteria are satisfied."
)
],
)
]
# Add conversation history.
messages.extend(request.user_messages)
messages.extend(request.agent_messages)
# Add explicit review instruction.
messages.append(Message("user", ["Please review the agent's responses."]))
print("Reviewer: Sending review request to LLM...")
response = await self._chat_client.get_response(messages=messages, options={"response_format": _Response})
parsed = _Response.model_validate_json(response.messages[-1].text)
print(f"Reviewer: Review complete - Approved: {parsed.approved}")
print(f"Reviewer: Feedback: {parsed.feedback}")
# Send structured review result to Worker.
await ctx.send_message(
ReviewResponse(request_id=request.request_id, feedback=parsed.feedback, approved=parsed.approved)
)
class Worker(Executor):
"""Executor that generates responses and incorporates feedback when necessary."""
def __init__(self, id: str, client: SupportsChatGetResponse) -> None:
super().__init__(id=id)
self._chat_client = client
self._pending_requests: dict[str, tuple[ReviewRequest, list[Message]]] = {}
@handler
async def handle_user_messages(self, user_messages: list[Message], ctx: WorkflowContext[ReviewRequest]) -> None:
print("Worker: Received user messages, generating response...")
# Initialize chat with system prompt.
messages = [Message("system", ["You are a helpful assistant."])]
messages.extend(user_messages)
print("Worker: Calling LLM to generate response...")
response = await self._chat_client.get_response(messages=messages)
print(f"Worker: Response generated: {response.messages[-1].text}")
# Add agent messages to context.
messages.extend(response.messages)
# Create review request and send to Reviewer.
request = ReviewRequest(request_id=str(uuid4()), user_messages=user_messages, agent_messages=response.messages)
print(f"Worker: Sending response for review (ID: {request.request_id[:8]})")
await ctx.send_message(request)
# Track request for possible retry.
self._pending_requests[request.request_id] = (request, messages)
@handler
async def handle_review_response(
self, review: ReviewResponse, ctx: WorkflowContext[ReviewRequest, AgentResponse]
) -> None:
print(f"Worker: Received review for request {review.request_id[:8]} - Approved: {review.approved}")
if review.request_id not in self._pending_requests:
raise ValueError(f"Unknown request ID in review: {review.request_id}")
request, messages = self._pending_requests.pop(review.request_id)
if review.approved:
print("Worker: Response approved. Emitting to external consumer...")
# Emit approved result to external consumer
await ctx.yield_output(AgentResponse(messages=request.agent_messages))
return
print(f"Worker: Response not approved. Feedback: {review.feedback}")
print("Worker: Regenerating response with feedback...")
# Incorporate review feedback.
messages.append(Message("system", [review.feedback]))
messages.append(Message("system", ["Please incorporate the feedback and regenerate the response."]))
messages.extend(request.user_messages)
# Retry with updated prompt.
response = await self._chat_client.get_response(messages=messages)
print(f"Worker: New response generated: {response.messages[-1].text}")
messages.extend(response.messages)
# Send updated request for re-review.
new_request = ReviewRequest(
request_id=review.request_id, user_messages=request.user_messages, agent_messages=response.messages
)
await ctx.send_message(new_request)
# Track new request for further evaluation.
self._pending_requests[new_request.request_id] = (new_request, messages)In Multi-Agent Debate, the idea is as follows. you have a set of solver agents that may interact together, i.e., simulate a multi-turn interaction for a given set of interactions or rounds, each time refining their respective responses until producing a final response (when final round reached). The solver agents can be connected sparsely e.g https://arxiv.org/pdf/2406.11776. The aggregator agent, given a query, dispatches tasks to the solver agents. They process the task, publish a response, and use the output of their neighbors to refine their own responses, producing another response. This process continues for a given number of rounds. Finally, the aggregator agent uses majority voting to aggregate the final responses from all solver agents.
You can see here how it is implemented: https://microsoft.github.io/autogen/stable//user-guide/core-user-guide/design-patterns/multi-agent-debate.html, with more details about the exchange mechanism. There is also a similar pattern implemented in https://github.com/microsoft/agent-framework/blob/main/python/samples/03-workflows/orchestrations/group_chat_philosophical_debate.py.
AutoGen introduced the notion of a chat, where multiple agents have access to the same conversation and form a team. At each turn, a selector, which is typically LLM-powered, uses the conversation history and the agents descriptions to select which agent should act on the conversation context and produce a message for its turn in the chat. Once the message is added to the chat, the selector picks the next agent conditioned on the updated chat, and the loop continues until a termination condition is met: for example, a FINAL keyword is detected in a produced message, a specific agent responds, or a StopMessage is produced by an agent.
In Microsoft Agent Framework Group Chat, the orchestrator drives the conversation by selecting the next speaker conditioned on the current context. It then sends a request to the selected participant to generate a response:
# Send request to selected participant
await self._send_request_to_participant(
# If not terminating, next_speaker must be provided and therefore will not be None
agent_orchestration_output.next_speaker, # type: ignore[arg-type]
cast(WorkflowContext[AgentExecutorRequest | GroupChatRequestMessage], ctx),
)The request sent to the selected participant is:
request = AgentExecutorRequest(
messages=messages,
should_respond=True,
)
await ctx.send_message(request, target_id=target)After a participant produces a response, the orchestrator broadcasts that message to the other participants so that their local contexts are updated, and then the loop continues:
# Broadcast messages to all participants for context
await self._broadcast_messages_to_participants(
messages,
cast(WorkflowContext[AgentExecutorRequest | GroupChatParticipantMessage], ctx),
)The orchestrator agent is invoked to decide whether to terminate or which participant should speak next:
async def _invoke_agent(self) -> AgentOrchestrationOutput:
"""Invoke the orchestrator agent to determine the next speaker and termination."""
async def _invoke_agent_helper(
conversation: list[Message],
) -> AgentOrchestrationOutput:
# Run the agent in non-streaming mode for simplicity
agent_response = await self._agent.run(
messages=conversation,
session=self._session,
options={"response_format": AgentOrchestrationOutput},
)
# Parse and validate the structured output
agent_orchestration_output = self._parse_agent_output(agent_response)
if (
not agent_orchestration_output.terminate
and not agent_orchestration_output.next_speaker
):
raise ValueError(
"next_speaker must be provided if not terminating the conversation."
)
return agent_orchestration_output
# We only need the last message for context because history is maintained in the thread
current_conversation = self._cache.copy()
self._cache.clear()
instruction = (
"Decide what to do next. Respond with a JSON object of the following format:\n"
"{\n"
' "terminate": <true|false>,\n'
' "reason": "<explanation for the decision>",\n'
' "next_speaker": "<name of the next participant to speak (if not terminating)>",\n'
' "final_message": "<optional final message if terminating>"\n'
"}\n"
"If not terminating, here are the valid participant names "
"(case-sensitive) and their descriptions:\n"
+ "\n".join(
[
f"{name}: {description}"
for name, description in self._participant_registry.participants.items()
]
)
)
# Append instruction as a user message
current_conversation.append(Message(role="user", contents=[instruction]))
retry_attempts = self._retry_attempts
while True:
try:
return await _invoke_agent_helper(current_conversation)
except Exception as ex:
logger.error(f"Agent orchestration invocation failed: {ex}")
if retry_attempts is None or retry_attempts <= 0:
raise
retry_attempts -= 1
logger.debug(
f"Retrying agent orchestration invocation, "
f"attempts left: {retry_attempts}"
)
# We do not need the full conversation because the thread should maintain history
current_conversation = [
Message(
role="user",
contents=[
f"Your input could not be parsed due to an error: {ex}. "
"Please try again."
],
)
]
Here is the loop handler that is triggered each time messages are received in AgentBasedGroupChatOrchestrator. On initial messages, the orchestrator appends the messages, checks termination, invokes the orchestration agent, broadcasts the input messages to all participants, sends a request to the selected participant, and increments the round count:
@override
async def _handle_messages(
self,
messages: list[Message],
ctx: WorkflowContext[GroupChatWorkflowContextOutT, list[Message]],
) -> None:
"""Initialize orchestrator state and start the conversation loop."""
self._append_messages(messages)
# Termination condition will also be applied to the input messages
if await self._check_terminate_and_yield(
cast(WorkflowContext[Never, AgentResponse | AgentResponseUpdate], ctx)
):
return
agent_orchestration_output = await self._invoke_agent()
if await self._check_agent_terminate_and_yield(
agent_orchestration_output,
cast(WorkflowContext[Never, AgentResponse | AgentResponseUpdate], ctx),
):
return
# Broadcast messages to all participants for context
await self._broadcast_messages_to_participants(
messages,
cast(WorkflowContext[AgentExecutorRequest | GroupChatParticipantMessage], ctx),
)
# Send request to selected participant
await self._send_request_to_participant(
# If not terminating, next_speaker must be provided and therefore will not be None
agent_orchestration_output.next_speaker, # type: ignore[arg-type]
cast(WorkflowContext[AgentExecutorRequest | GroupChatRequestMessage], ctx),
)
self._increment_round()On a participant response, the orchestrator processes the response, cleans tool-related content, appends the messages, checks termination and round limits, invokes the orchestration agent, broadcasts the participant message to all other participants except the producer, sends a request to the selected next speaker, and increments the round count:
@override
async def _handle_response(
self,
response: AgentExecutorResponse | GroupChatResponseMessage,
ctx: WorkflowContext[GroupChatWorkflowContextOutT, list[Message]],
) -> None:
"""Handle a participant response."""
messages = self._process_participant_response(response)
# Remove tool-related content to prevent API errors from empty messages
messages = clean_conversation_for_handoff(messages)
self._append_messages(messages)
if await self._check_terminate_and_yield(
cast(WorkflowContext[Never, AgentResponse | AgentResponseUpdate], ctx)
):
return
if await self._check_round_limit_and_yield(
cast(WorkflowContext[Never, AgentResponse | AgentResponseUpdate], ctx)
):
return
agent_orchestration_output = await self._invoke_agent()
if await self._check_agent_terminate_and_yield(
agent_orchestration_output,
cast(WorkflowContext[Never, AgentResponse | AgentResponseUpdate], ctx),
):
return
# Broadcast participant messages to all participants for context,
# except the participant that just responded
participant = ctx.get_source_executor_id()
await self._broadcast_messages_to_participants(
messages,
cast(WorkflowContext[AgentExecutorRequest | GroupChatParticipantMessage], ctx),
participants=[
p
for p in self._participant_registry.participants
if p != participant
],
)
# Send request to selected participant
await self._send_request_to_participant(
# If not terminating, next_speaker must be provided and therefore will not be None
agent_orchestration_output.next_speaker, # type: ignore[arg-type]
cast(WorkflowContext[AgentExecutorRequest | GroupChatRequestMessage], ctx),
)
self._increment_round()So the overall Group Chat loop is append incoming messages, check termination condition, invoke orchestrator agent, check agent termination decision, broadcast messages to participants, send request to selected participant, receive participant response, append response, check termination and round limit, invoke orchestrator agent again, broadcast response to all participants except producer, send request to next selected participant, repeat…
All other agents get their cache or history updated with the produced participant message. The producing agent is excluded from the broadcast because it already has that message from its own call.
The agents therefore share the same conversation context, but they do not share the same system prompt or instructions.
In Magentic-One, a lead agent, or orchestrator, defines the plan and tracks progress among the subagents it directs.
Specialized agents, each with different roles, are part of a team, and the lead agent dispatches tasks to these agents.
If the lead agent observes that there is an error and the plan cannot proceed, it triggers a recovery step to continue the execution of the plan. Specifically, two loops are introduced an outer loop maintains the task ledger, which contains the overall plan, while the inner loop maintains the progress ledger. The inner loop is initiated once the plan is formed and is updated by the orchestrator as the subagents finish their assigned tasks. Both loops are maintained by the orchestrator.
For example, if the agents are stuck or there is no progress, the orchestrator breaks from the inner loop and proceeds with another iteration of the outer loop, which could lead to a new plan decomposition (see below).
Magnetic is very similar to GroupChat. In GroupChat, the manager mainly handles turn selection, i.e, select speaker, request intervention of agent, append response, broadcast response, check stop condition, select next speaker and then repeat. In GroupChat, the manager is mainly responsible for selecting the next speaker. In Magentic, as presented above, there is a task ledger:
@dataclass
class _MagenticTaskLedger(DictConvertible):
"""Internal: Task ledger for the Standard Magentic manager."""
facts: Message
plan: Message
def to_dict(self) -> dict[str, Any]:
return {
"facts": _message_to_payload(self.facts),
"plan": _message_to_payload(self.plan),
}
@classmethod
def from_dict(cls, data: dict[str, Any]) -> "_MagenticTaskLedger":
return cls(
facts=_message_from_payload(data.get("facts")),
plan=_message_from_payload(data.get("plan")),
)There is also a progress ledger:
@dataclass
class MagenticProgressLedger(DictConvertible):
"""Internal: A progress ledger for tracking workflow progress."""
is_request_satisfied: MagenticProgressLedgerItem
is_in_loop: MagenticProgressLedgerItem
is_progress_being_made: MagenticProgressLedgerItem
next_speaker: MagenticProgressLedgerItem
instruction_or_question: MagenticProgressLedgerItem
def to_dict(self) -> dict[str, Any]:
return {
"is_request_satisfied": self.is_request_satisfied.to_dict(),
"is_in_loop": self.is_in_loop.to_dict(),
"is_progress_being_made": self.is_progress_being_made.to_dict(),
"next_speaker": self.next_speaker.to_dict(),
"instruction_or_question": self.instruction_or_question.to_dict(),
}
When initially prompted, the context is first created:
self._magentic_context = MagenticContext(
task=messages[0].text,
participant_descriptions=self._participant_registry.participants,
chat_history=list(messages),
)A plan is then created:
# Initial planning using the manager with real model calls
self._task_ledger = await self._manager.plan(
self._magentic_context.clone(deep=True)
)Then the inner loop is executed initially, and also after each agent response. It does the following.
First, the progress ledger is created or updated:
# Create progress ledger using the manager
try:
self._progress_ledger = await self._manager.create_progress_ledger(
self._magentic_context.clone(deep=True)
)
except Exception as ex:
logger.warning(
f"Magentic Orchestrator: Progress ledger creation failed, triggering reset: {ex}"
)
await self._reset_and_replan(ctx)
returnNext, the task is checked for completion:
# Check for task completion
if self._progress_ledger.is_request_satisfied.answer:
logger.info("Magentic Orchestrator: Task completed")
await self._prepare_final_answer(
cast(WorkflowContext[Never, AgentResponse | AgentResponseUpdate], ctx)
)
return
Next, the speaker is selected:
# Determine the next speaker and instruction
next_speaker = self._progress_ledger.next_speaker.answer
if not isinstance(next_speaker, str):
# Fallback to first participant if ledger returns non-string
logger.warning(
"Next speaker answer was not a string; selecting first participant as fallback"
)
next_speaker = next(iter(self._participant_registry.participants.keys()))
instruction = self._progress_ledger.instruction_or_question.answer
# Request specific agent to respond
logger.debug(f"Magentic Orchestrator: Requesting {next_speaker} to respond")
await self._send_request_to_participant(
next_speaker,
cast(WorkflowContext[AgentExecutorRequest | GroupChatRequestMessage], ctx),
additional_instruction=str(instruction),
)If there is a stall count, the context is reset and replanned. Planning is achieved by first calling the foundation model to gather facts, then to create a plan, and finally by setting:
self.task_ledger = _MagenticTaskLedger(
facts=facts_msg,
plan=plan_msg,
)During replanning, task_ledger_facts_update_prompt is used to update the facts conditioned on the history. Then task_ledger_plan_update_prompt is used to update the plan. Finally, a new task ledger is produced:
self.task_ledger = _MagenticTaskLedger(
facts=updated_facts,
plan=updated_plan,
)The stall check is:
if self._magentic_context.stall_count > self._manager.max_stall_count:
logger.debug(
f"Magentic Orchestrator: Stalling detected after "
f"{self._magentic_context.stall_count} rounds"
)
await self._reset_and_replan(ctx)
returnOn a new agent response, the message is broadcast to all participants except the producer. Their contexts are then updated, and the inner loop is triggered again:
self._progress_ledger = await self._manager.create_progress_ledger(
self._magentic_context.clone(deep=True)
)Finally, the final answer is synthesized using a model.
Another pattern, for example implemented by Strix is to spawn subagents dynamically at runtime; for example to validate a vulnerability in a penetration testing exercise. The creation of agents is exposed as a tool and the foundation model can decide at some point to use the tool i.e create a subagent. If you look at the definition of the tool, the model can decide whether the subagent share the context or not:

@register_tool(sandbox_execution=False)
def create_agent(
agent_state: Any,
task: str,
name: str,
inherit_context: bool = True,
skills: str | None = None,
) -> dict[str, Any]:
try:
...
</details>
<parameters>
<parameter name="task" type="string" required="true">
<description>The specific task/objective for the new agent to accomplish</description>
</parameter>
<parameter name="name" type="string" required="true">
<description>Human-readable name for the agent (for tracking purposes)</description>
</parameter>
<parameter name="inherit_context" type="boolean" required="false">
<description>Whether the new agent should inherit parent's conversation history and context</description>
</parameter>
<parameter name="skills" type="string" required="false">
<description>Comma-separated list of skills to use for the agent (MAXIMUM 5 skills allowed). Most agents should have at least one skill in order to be useful. Agents should be highly specialized - use 1-3 related skills; up to 5 for complex contexts. {{DYNAMIC_SKILLS_DESCRIPTION}}</description>
</parameter>
</parameters>
<returns type="Dict[str, Any]">
<description>Response containing: - agent_id: Unique identifier for the created agent - success: Whether the agent was created successfully - message: Status message - agent_info: Details about the created agent</description>
</returns>
<examples>Mixture of agents draws inspiration from Mixture of Experts or MoE, the idea is as follows, you have one orchestrator agent, and many works agents placed at different layers form 1 to N.
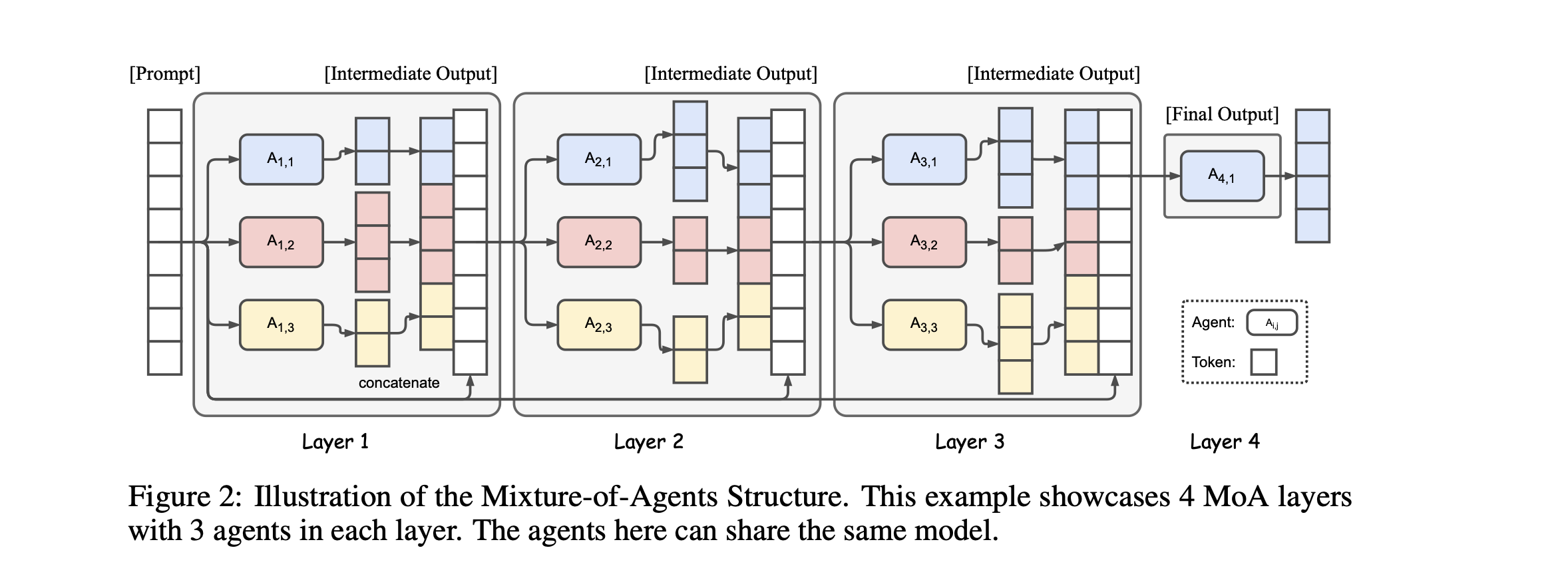
Given a task, the orchestrator agent invoke agents on the first layer, then once response is returned from these agents, the orchestrator then synthesize the result and dispatch to the workers in the second layer and so on until the final layer when the orchestrator combines the result form the previous layer and produce a final output.
At each layer the same model can be used for all worker agents or each agent in the layer can also use a different model, see here how it could be implemented i.e by registration https://microsoft.github.io/autogen/stable//user-guide/core-user-guide/design-patterns/mixture-of-agents.html
In this section, we look at some security defects at the agentic layer that were reported recently.
Equipping models with tool calls opens the door to many opportunities, but also dramatically increases the attack surface, especially when there is no control. For example, if you blindly instantiate your framework agent, give it the keys to heaven, and let it send you to hell.
The first straightforward example is CVE-2026-26030, where an adversary can exploit the fact that the filter was building a lambda from LLM-controlled output, which could lead to RCE.
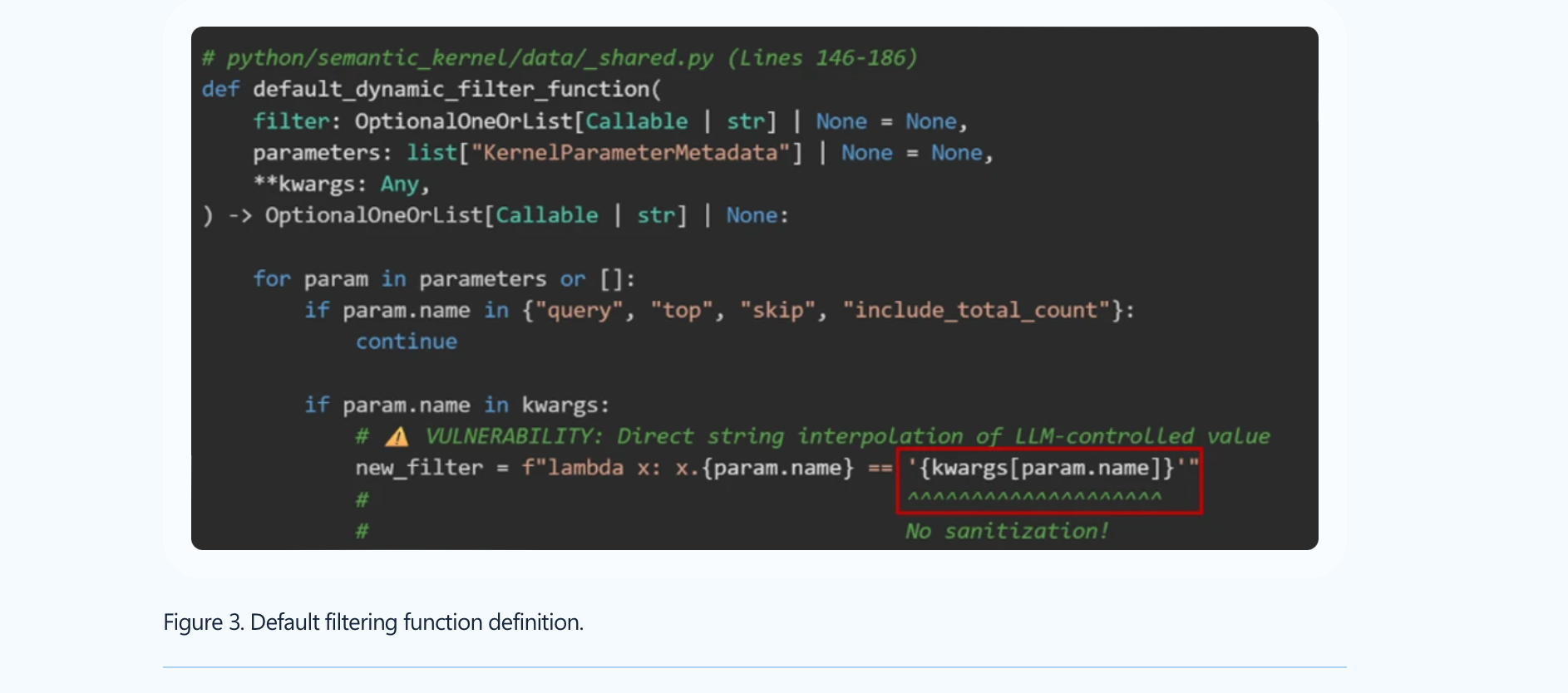
Here is what the RCE looks like (which bypasses existing blocklist probe):

Thus, if you built your agent using this vulnerable version, you may be highly impacted, for example, if you are using In-Memory Vector Store. The fix for CVE-2026-26030 was introduced in version 1.39.4.
The second defect we discuss is CVE-2026-25592. Basically, the foundation model had access to a tool it should not have access to (DownloadFileAsync, enabling direct file write primitive on the host ) and allowed an adversary to bypass azure sandbox enabling full host compromise.
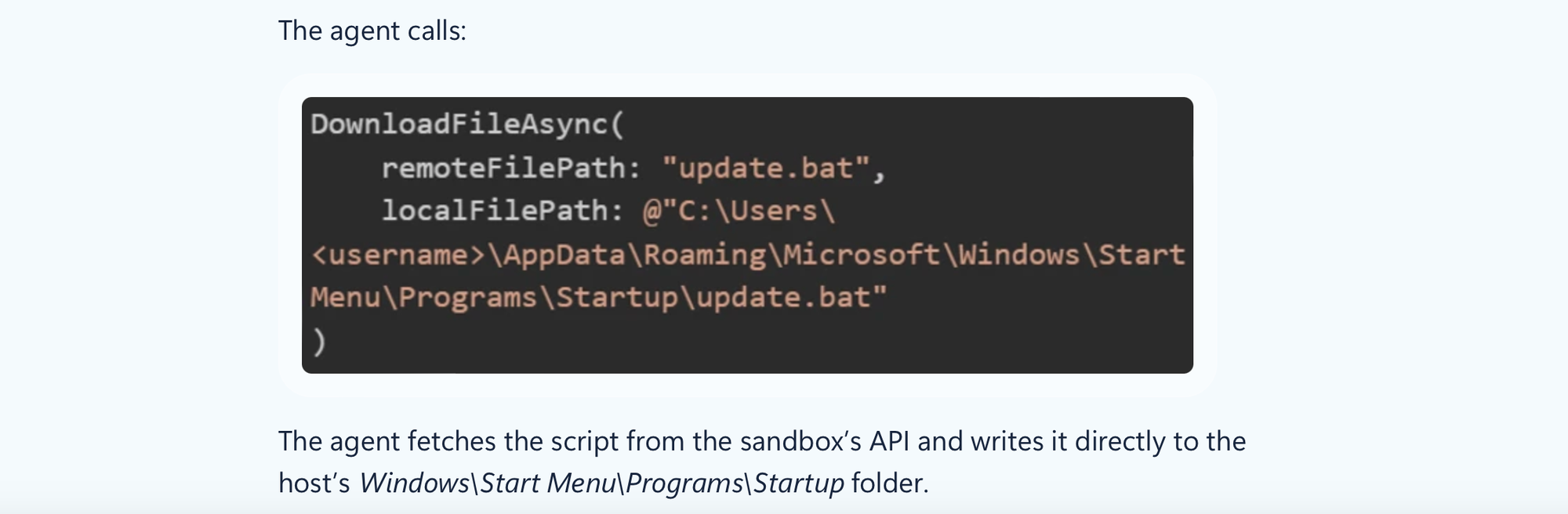
This is already enough to show that the attack surface when using agentic frameworks dramatically increases.
Let’s discuss other defects.
CrewAI is a widely known multi-agent framework. It is different from other frameworks in terms of the patterns it implements and has been vulnerable to many flaws: https://www.kb.cert.org/vuls/id/221883. CVE-2026-2285 allowed an attacker to leverage JSON and a lack of validation to access files on the server. CVE-2026-2275 was mainly due to an insecure fallback, the CrewAI CodeInterpreter tool falls back to SandboxPython when it cannot reach Docker. Similarly, CVE-2026-2287 is due to a lack of checks to verify that Docker is still running during runtime, causing it to fall back to a sandbox setting that allows for RCE exploitation.
Again, be careful when using agentic frameworks.
How could we not talk about MCP flaws :p
Basically, MCP, or Model Context Protocol, is a way, or standard, to incorporate context and expose tools to LLMs when, for example, one cannot modify the underlying agent code, such as with Claude, or simply wants to avoid fragmented integrations.
MCP consists of a client, sitting usually at the agent layer and then a server that accepts user sessions and process MCP requests; for example to list or execute tools (and other stuff).
MCPs are widely integrated with multi-agent systems. However, while their integration seems easy, MCPs are not secure by default and can enable a wide range of attacks, especially when the MCP server is malicious or attacker-controlled. For example, this can include data exfiltration, tool hijacking, etc.
Remember that LLMs are trained to follow instructions.
OX Security [https://www.ox.security/blog/the-mother-of-all-ai-supply-chains-critical-systemic-vulnerability-at-the-core-of-the-mcp/] revealed many security defects, including CVE-2025-65719, which enables arbitrary code execution once a user visits a malicious website. In this case, the server is not malicious but is simply too friendly, as it accepts requests without checking the origin. This could have been prevented, for example, with API token protection or scope-based permissions.
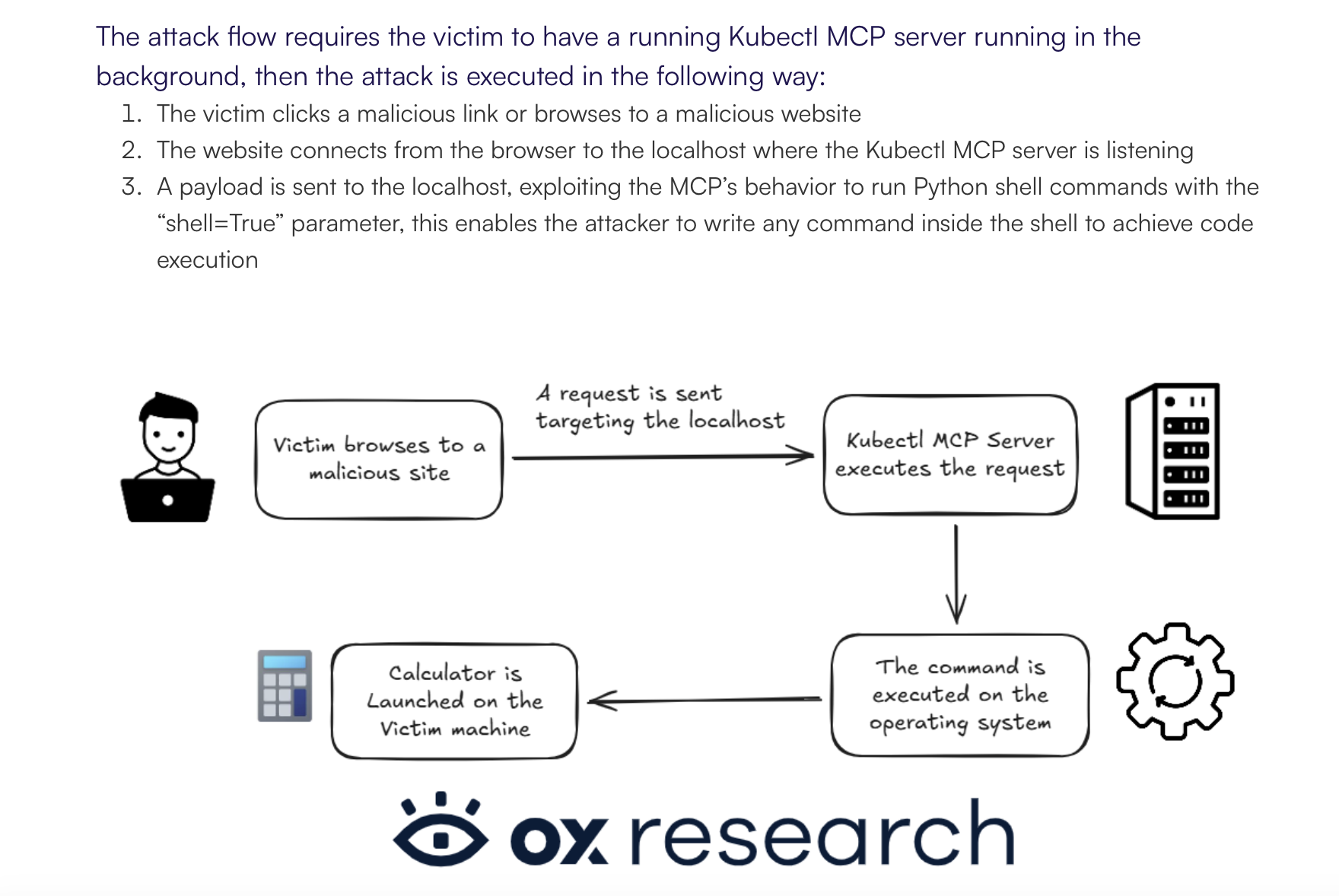
There are other vulnerabilities reported as well, for example targeting LiteLLM, where authenticated users can achieve RCE due to the capability to deploy local/stdio MCP servers [https://docs.litellm.ai/blog/mcp-stdio-command-injection-april-2026].
In this post, we covered how agents and multi-agent systems work by looking at several frameworks and projects. Using a framework is not always the best approach; it depends on your use case, how much control you need over the agent loop, and which orchestration pattern you want to use.
Agents can be useful in many scenarios, but they can also increase costs. Make sure you do not burn tokens simply because the application is not configured properly. For example, if an agent cannot test an application because of network or authorization issues, it may keep looping for some time before realizing that it needs to stop.
Data is more important than the pattern you use. Powerful foundation models can help in complex scenarios such as penetration testing or investigations, but you still need to fix the basics first, especially data quality. Only then should you start thinking about using that data to automate tedious tasks.
When using an open-source multi-agent orchestration framework, MCP, or any other channel that writes into a foundation model, you need to be aware of the security implications.
Use multi-agent orchestration only when the task genuinely requires autonomy or specialization; otherwise, predictable workflows plus retrieval are often better.
And please, LLMs do not reason; they produce reasoning-like outputs, and this is different, which makes tool access, permissions, validation, and orchestration controls critical...
I hope this post was useful, I tried to keep it as short as possible.