Introduction A straightforward approach to augment large language models or LLMs with new capabilities is through in-context learning. The model is provided with a small number of examples that demonstrate how to solve a task, after which it generates a response using its inherent capabilities combined with the knowledge

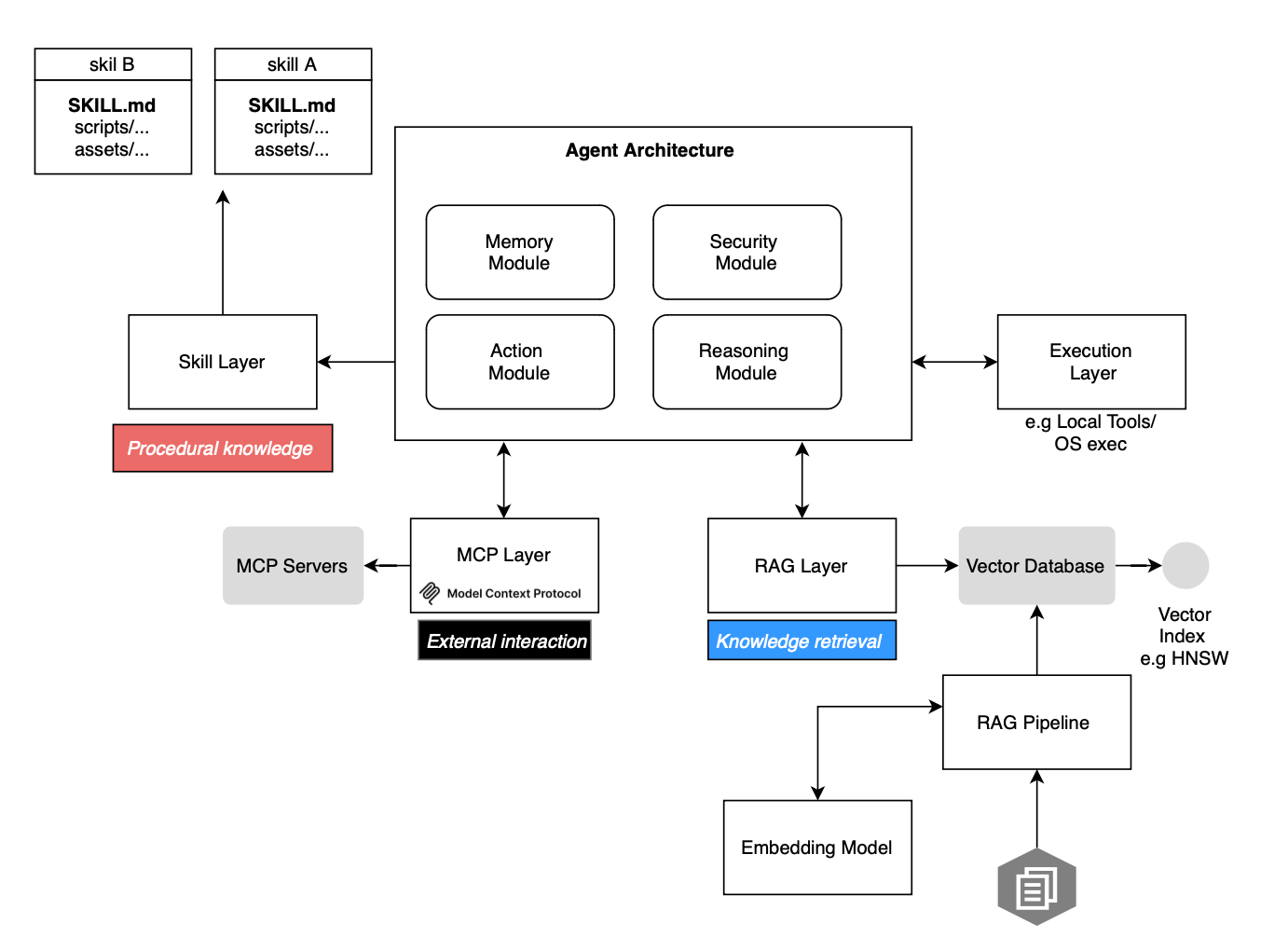
A straightforward approach to augment large language models or LLMs with new capabilities is through in-context learning. The model is provided with a small number of examples that demonstrate how to solve a task, after which it generates a response using its inherent capabilities combined with the knowledge embedded in the prompt. Function calling and standardized tools such as the Model Context Protocol or MCP have been introduced to extend LLM capabilities beyond text generation; LLM-based agents can now do almost anything you can think of. Another augmentation strategy is to equip LLMs with information retrieval capabilities, such as retrieval-augmented generation (RAG) or GraphRAG for knowledge graph-based retrieval. In this post, we cover Agent Skills, another way to equip LLM-based agents, used by Claude Code, OpenClaw, and Codex. We explore them in detail, including how they fit into the agentic stack, how an agent selects and executes them during task solving, and how they differ from prompts, tools, and RAG.
Compared to my recent post about GEMM and deep learning, this one is much shorter and far less technical.
Anthropic introduced skills as a way to augment agents with procedural knowledge without fine-tuning model parameters. Instead of updating weights, one can guide agent behavior at inference time using modular, reusable artifacts known as skills or agent skills. These bundles encode task-specific workflows, instructions, and auxiliary resources like references or assets dynamically loaded when deemed relevant by the underlying agent.

More precisely, a skill is a shareable artifact, in its simplest form, directory hosting a SKILL.md file, that encapsulates domain expertise and procedural guidance for a given task; for example code analysis. The SKILL.md file must start with a mandatory YAML frontmatter block at the top that includes the name and description of the skill as shown below. Additional resources like scripts, assets and references reside in subdirectories and can be loaded on dynamically.
---
name: analyzing-campaign-attribution-evidence
description: Campaign attribution analysis involves systematically evaluating evidence to determine which threat actor or
group is responsible for a cyber operation. This skill covers collecting and weighting attr
domain: cybersecurity
subdomain: threat-intelligence
tags:
- threat-intelligence
- cti
- ioc
- mitre-attack
- stix
- attribution
- campaign-analysis
version: '1.0'
author: mahipal
license: Apache-2.0
nist_csf:
- ID.RA-01
- ID.RA-05
- DE.CM-01
- DE.AE-02
---
...
## Workflow
### Step 1: Collect Attribution Evidence
```python
from stix2 import MemoryStore, Filter
from collections import defaultdict
class AttributionAnalyzer:
def __init__(self):
self.evidence = []
self.hypotheses = {}
def add_evidence(self, category, description, value, confidence):
self.evidence.append({
"category": category,
"description": description,
"value": value,
"confidence": confidence,
"timestamp": None,
})
...The file then defines then how to solve the task (i.e., a reusable workflow), along with additional resources such as scripts, queries, or templates.
Skills may bundle executable assets like .py files or binaries and reference them by name from the SKILL.md file.
What is really important to understand is that skills do not directly provide execution capabilities like MCP tools do. Instead, they define how a task should be performed. Without underlying tools capable of executing the prescribed actions (like playing a python script e.g https://github.com/mukul975/Anthropic-Cybersecurity-Skills/tree/main/skills/analyzing-campaign-attribution-evidence/scripts), skills alone are insufficient.
The idea is that, given a user query, the agent can infer which skill to load based on its description. The full instructions encoded in the skill (i.e SKILL.md) are then added to the context window, allowing the agent to move toward achieving the target goal.
Unlike static non-modular prompts, skills are loaded on demand. At startup, the agent preloads only the names and descriptions of available skills into its system prompt thereby avoiding repeatedly injecting the same guidance and improving token efficiency. Thus skills guide agent reasoning and behavior by structuring workflows, and this is different from RAG, which focuses on information retrieval and response generation. Tools (including MCP tools) provide tool capabilities. So, skills are basically a layer between reasoning and execution and one should not see Skills competing with MCPs.
Skills inherit the same privilege level as the user's environment. As a result, they introduce significant security risks. Public repositories (e.g. GitHub repositories) already host various skills, some of which may be malicious e.g they can define data exfiltration instructions [https://arxiv.org/html/2602.06547v1, https://arxiv.org/html/2604.15415v1 ]. Therefore, skills must be treated as untrusted code, especially when they include executable resources.

To better understand how agents like Claude Code utilize skills, we examine the integration of the Skills capability within the OpenAI Agents SDK [https://github.com/openai/openai-agents-python](note though that skills are supported in Codex only, cf https://github.com/openai/openai-agents-python/issues/2361).
This is what it looks like:
def build_agent(model: str) -> SandboxAgent:
return SandboxAgent(
name="Vision Website Clone Builder",
model=model,
instructions=AGENTS_MD,
capabilities=[
Shell(),
Filesystem(),
Skills(
lazy_from=LocalDirLazySkillSource(source=LocalDir(src=SKILLS_SOURCE_DIR)),
skills_path="skills",
),
],
model_settings=ModelSettings(tool_choice="required"),
)At a high level, the agent operates by identifying relevant skills from metadata, loading the selected skill into the workspace, reading its SKILL.md file, accessing associated resources, and invoking tools to execute the prescribed workflow.
At initialization, the agent is prompted with a list of available skills, including their metadata (name, description, and path). Skills are not fully loaded into the workspace at this stage; instead, they are indexed for planning and can be loaded on demand to achieve subgoals:
async def instructions(self, manifest: Manifest) -> str | None:
skills = await self._skill_metadata(manifest)
if not skills:
return None
available_skill_lines: list[str] = []
for skill in skills:
path_str = str(skill.path).replace("\\", "/")
available_skill_lines.append(f"- {skill.name}: {skill.description} (file: {path_str})")
how_to_use_section = (
_HOW_TO_USE_LAZY_SKILLS_SECTION
if self.lazy_from is not None
else _HOW_TO_USE_SKILLS_SECTION
)
return "\n".join(
[
"## Skills",
_SKILLS_SECTION_INTRO,
"### Available skills",
*available_skill_lines,
*(
[
"### Lazy loading",
"- These skills are indexed for planning, but they are not materialized "
"in the workspace yet.",
"- Call `load_skill` with a single skill name from the list before "
"reading its `SKILL.md` or other files from the workspace.",
"- `load_skill` stages exactly one skill under the listed path. "
"If you need more than one skill, call it multiple times.",
]
if self.lazy_from is not None
else []
),
how_to_use_section,
]
)As listed below, the system prompt explicitly informs the model that skills are stored as local instruction sets in SKILL.md files, only metadata is initially available, and that skills must be explicitly loaded before accessing their contents. This enables lazy loading, where the agent select only the skills required for the current task (token efficient).
….
_SKILLS_SECTION_INTRO = (
"A skill is a set of local instructions to follow that is stored in a `SKILL.md` file. "
"Below is the list of skills that can be used. Each entry includes a name, description, "
"and file path so you can open the source for full instructions when using a specific skill."
)
…
_HOW_TO_USE_SKILLS_SECTION = "\n".join(
[
"### How to use skills",
"- Discovery: The list above is the skills available in this session "
"(name + description + file path). Skill bodies live on disk at the listed paths.",
"- Trigger rules: If the user names a skill (with `$SkillName` or plain text) "
"OR the task clearly matches a skill's description shown above, you must use that "
"skill for that turn. Multiple mentions mean use them all. Do not carry skills "Skill discovery relies on parsing metadata from local directories. As said earlier, each skill is expected to reside in a folder containing a SKILL.md file with YAML frontmatter:
def list_skill_metadata(self, *, skills_path: str) -> list[SkillMetadata]:
src_root = self._src_root()
if src_root is None:
return []
metadata: list[SkillMetadata] = []
for child in sorted(src_root.iterdir(), key=lambda entry: entry.name):
if not child.is_dir():
continue
skill_md_path = child / "SKILL.md"
if not skill_md_path.is_file():
continue
try:
markdown = skill_md_path.read_text(encoding="utf-8")
except OSError:
continue
frontmatter = _parse_frontmatter(markdown)
metadata.append(
SkillMetadata(
name=frontmatter.get("name", child.name),
description=frontmatter.get("description", "No description provided."),
path=Path(skills_path) / child.name,
)
)
return metadataWhen the agent decides to use a skill, it invokes a dedicated loading procedure that materializes the skill into the workspace:
async def load_skill(
self,
*,
skill_name: str,
session: BaseSandboxSession,
skills_path: str,
user: str | User | None = None,
) -> dict[str, str]:
src_root = self._src_root()
if src_root is None:
raise SkillsConfigError(
message="lazy skill source directory is unavailable",
context={"skill_name": skill_name},
)
matches = [
skill
for skill in self.list_skill_metadata(skills_path=skills_path)
if skill.name == skill_name or skill.path.name == skill_name
]
if not matches:
raise SkillsConfigError(
message="lazy skill not found",
context={"skill_name": skill_name, "skills_path": skills_path},
)
if len(matches) > 1:
raise SkillsConfigError(
message="lazy skill name is ambiguous",
context={
"skill_name": skill_name,
"matching_paths": [str(skill.path) for skill in matches],
},
)
metadata = matches[0]
workspace_root = Path(session.state.manifest.root)
skill_dest = workspace_root / metadata.path
skill_md_path = skill_dest / "SKILL.md"
try:
handle = await session.read(skill_md_path, user=user)
except Exception:
handle = None
if handle is not None:
handle.close()
return {
"status": "already_loaded",
"skill_name": metadata.name,
"path": str(metadata.path).replace("\\", "/"),
}
await LocalDir(src=src_root / metadata.path.name).apply(
session,
skill_dest,
base_dir=Path.cwd(),
user=user,
)
return {
"status": "loaded",
"skill_name": metadata.name,
"path": str(metadata.path).replace("\\", "/"),
}Once loaded, the skill exposes a directory path within the workspace. The agent can then read SKILL.md to obtain task-specific instructions, access associated resources (e.g., scripts) and refer to these resources using relative paths.
Skill loading itself is exposed as a callable tool:
@dataclass(init=False)
class _LoadSkillTool(FunctionTool):
tool_name = "load_skill"
args_model = _LoadSkillArgs
tool_description = (
"Load a single lazily configured skill into the sandbox so its SKILL.md, scripts, "
"references, and assets can be read from the workspace."
)
skills: Skills = field(init=False, repr=False, compare=False)
def __init__(self, *, skills: Skills) -> None:
self.skills = skills
super().__init__(
name=self.tool_name,
description=self.tool_description,
params_json_schema=self.args_model.model_json_schema(),
on_invoke_tool=self._invoke,
strict_json_schema=False,
)
If we resume, the available skills are listed in the system prompt with names and descriptions, next, during the agent loop, the agent selects, based on the query, a skill to load and then follows the instructions defined in the markdown and schedule tool calls. Thus, skills define what to do, while tools define how to do it. The workspace here serves as the interface through which both are connected.
Note that skills can also be discovered semantically by projecting the skills to a neural embedding space using their associated description, which can help when there are like hundreds of skills that could lead to prompt overhead specially if only few of them are needed for the task completion[https://github.com/anthropics/claude-code/issues/24730].
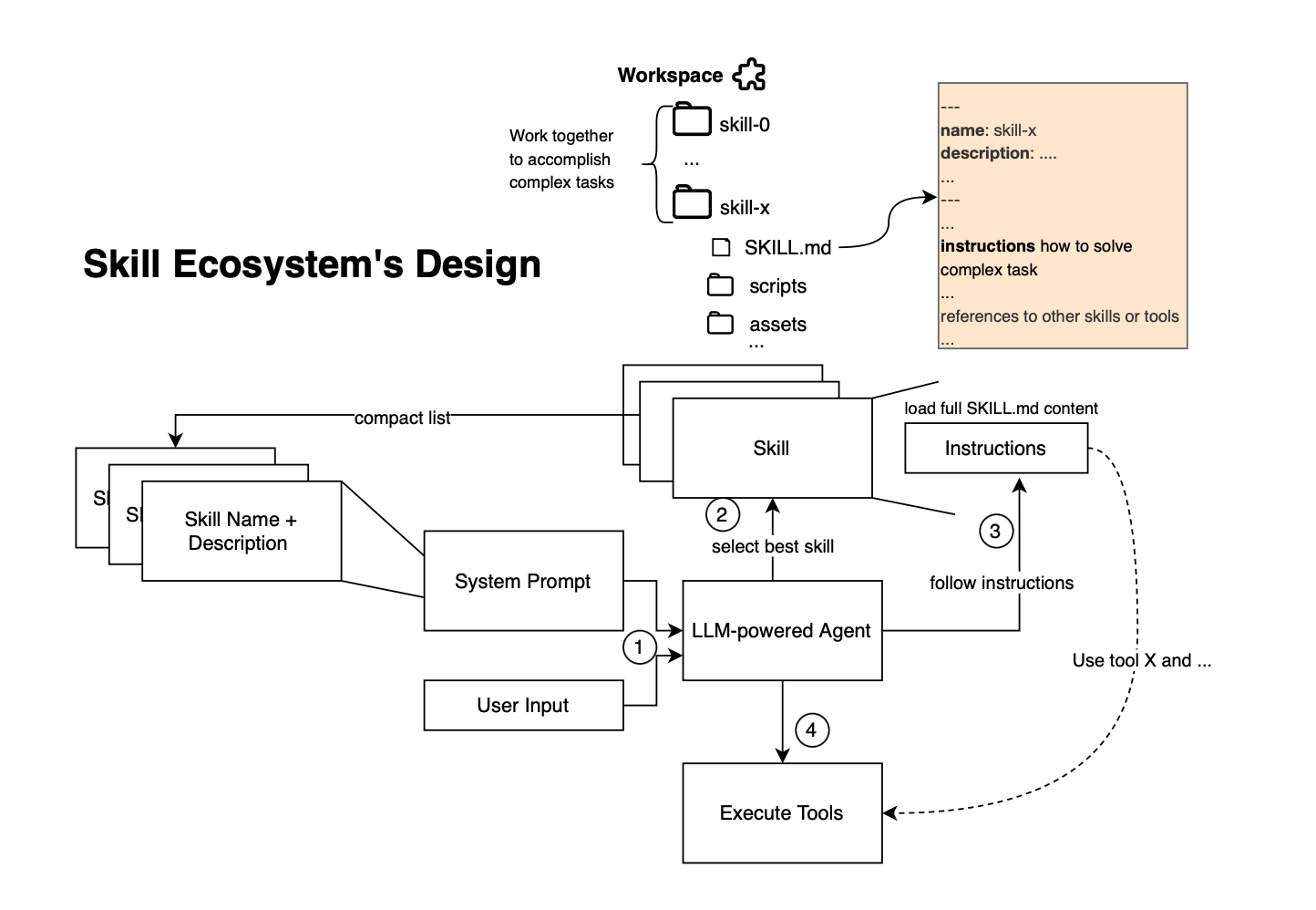
I did not find any open-source agent SDK that natively supports skills, so I quickly developed a simple example to illustrate how skills can be integrated. The code is available at https://github.com/mouadk/ai-agent-skills (it is very naive hein). As shown below, the agent first reads the skill and then follows the instructions to execute Python code as instructed in the skill.

Note though that the actual agent implementation and integration of skills could be slightly different from one agent to another e.g. https://github.com/microsoft/agent-framework/blob/main/dotnet/samples/02-agents/AgentSkills/Agent_Step01_FileBasedSkills/Program.cs.
That is all I hope that now you understand how AI agent skills fit in the agentic stack and how they are used to develop LLM-based agents. Note however, that there is no definitive evidence that their inclusion systematically improves agent performance[https://arxiv.org/html/2602.12670v1].