Large Language Models (LLMs) have evolved from being merely passive text generators with limited capabilities to becoming autonomous or semi-autonomous agents navigating complex environments and offering actionable insights. This transformation equips them with a diverse set of tools, perception modules to interpret signals from various modalities, and memory systems
Large Language Models (LLMs) have evolved from being merely passive text generators with limited capabilities to becoming autonomous or semi-autonomous agents navigating complex environments and offering actionable insights. This transformation equips them with a diverse set of tools, perception modules to interpret signals from various modalities, and memory systems to accomplish specific objectives.
The configuration of LLM-based agents includes a set of potential actions, API definitions, roles or characters to embody, and the task at hand, along with in-context examples. These elements are encoded within the prompt, which must be precisely crafted for optimal performance due to its sensitivity.
A common approach in the operation of these agents is stacking [e.g. AutoGPT]; The model is called recursively, allowing it to attend to previous actions and observations in order to predict the next steps. This capability enables the agent to self-reflect and adjust its plan progressively until a solution is found or the goal is achieved. Such a mechanism ensures that the agent not only follows a set path but also dynamically adapts its strategy based on the evolving context and outcomes of its actions.
We shift from simple text generation to complex, goal-oriented problem-solving, demonstrating the rapidly expanding potential of AI agents.
Large Language Model (LLM)
A Large Language Model (LLM), such as GPT-4, is a language model designed to approximate the distribution governing the global language space. LLMs based on transformers utilize an attention mechanism, enabling the model to consider previous words for predicting subsequent ones.
Typically, an LLM undergoes two main stages: a pretraining stage and a fine-tuning stage for downstream tasks. However, due to the emergent abilities of LLMs (present in larger models), pretrained models demonstrate outstanding performance, learning tasks on-the-fly in a manner akin to human in-context learning.
Reinforcement Learning from Human Feedback (RLHF) is often employed during training to further refine the model. This process helps the model adhere to instructions and avoid incorporating harmful or inappropriate responses when deployed in conversational settings.
Despite their power, LLMs are susceptible to hallucinations, where the model fabricate nonsense. Addressing this issue remains a focus of ongoing research.
Another challenge with LLMs is the limitation on context size, often restricted to thousands of tokens due to the quadratic complexity inherent in the attention mechanism used during training and inference. Methods like Retrieval-Augmented Generation (RAG) and Mixture of Experts (MoE) have been introduced to extend the model's lens and reduce memory requirements on devices.
In-Context Learning (ICL)
In-context learning (ICL) refers to a model's ability to adjust itself based on a given prompt sequence that includes in-context examples. These examples are input-output pairs related to a specific task, combined with a new query input, from which the model generates a corresponding output.
The key advantage of ICL is its capacity to enable models like GPT-3 to infer the output for a given query using a limited set of example pairs. This approach eliminates the need to modify model weights or conduct task-specific training for various downstream tasks. Instead, the model can dynamically adapt and learn in real time by conditioning itself on a sequence of demonstrative examples.
However, it's important to recognize the limitations of ICL. There's no absolute certainty that the model will consistently understand the intended task correctly and produce an appropriate response. Research indicates that these models are quite sensitive to the nature and quality of the in-context examples provided. For instance, a study highlighted in https://aclanthology.org/2022.acl-long.556.pdf reveals significant variability in model performance based on the examples used in ICL. This underscores the need for careful selection and design of in-context examples to optimize the effectiveness of ICL in LLMs.
Chain of Thought (CoT)
Chain-of-Thought (CoT) is an enhancement of in-context learning, focusing on the creation of a sequence of reasoning steps that a model follows to solve complex tasks. The concept draws inspiration from human cognitive processes, where a series of logical steps bridges the gap between a problem and its solution.
The essence of CoT lies in incorporating intermediate reasoning steps, both during training and prediction phases. Instead of relying solely on direct prompt question/answer pairs, CoT involves structuring the learning process to encourage the model to not only produce output from input but also to develop intermediate steps of reasoning. This approach aims to elevate the model's capabilities beyond basic input-output mapping, enabling it to engage in a more nuanced, step-by-step reasoning process.
Such a structured reasoning approach could significantly enhance the model's proficiency in tackling complex tasks. By learning to navigate through a series of logical steps, the model mimics human-like problem-solving strategies, potentially leading to more accurate and contextually relevant solutions. CoT represents an attempt to push the boundaries of what language models can achieve, bringing them closer to the intricacies of human thought processes.
From Passive to LLM-Based Agents
Before delving into the development of agents based on LLMs, it's crucial to define what an AI Agent is and understand the processes that make an LLM both actionable and autonomous.
An LLM essentially maps input from one vector space to another (or if you want from one sequence to another). This transformation involves a cascade of learnable projections through backpropagation. Intermediate representations in this process aid in achieving the final projection.
By predicting the next word in a sequence, LLMs are capable of approximating the probability distribution governing the world's language space. LLMs operates by transforming numerical representations, raising the question: How do researchers make LLMs actionable?
When scaled, LLMs exhibit robust capabilities known as emergent abilities. Notable examples include reasoning and in-context learning, where the model learns adaptively and demonstrates reasoning capabilities. These features motivated the development of LLM-based agents, where the LLM acts as the brain of the agent. It defines strategies, reasoning, and plans for using various tools. These tools help address issues like hallucinations, incorporate up-to-date knowledge, and overcome other limitations.
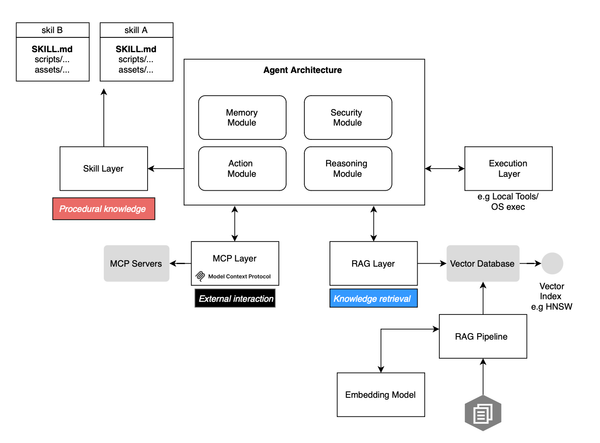
An LLM-based agent typically comprises the following components:
Perception Module: Integrates signals from various modalities like audio and video, enabling the LLM to interpret them. For instance, if the LLM suggests physical interaction with the environment, this module ensures the LLM understands the state of the relevant modality to progress in task resolution.
Action Module: Translates the LLM's suggestions into actions, like querying a search engine API or executing Python code snippets with specific parameters.
Reasoning: Utilizes feedback from the environment and previous actions to refine the approach and adjust plans as needed.
Planning: Deals with complex tasks by breaking them down into manageable subtasks, following a divide-and-conquer approach.
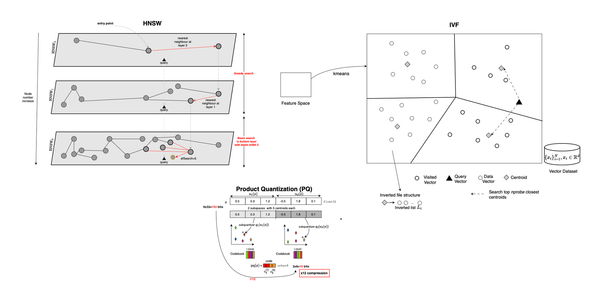
Memory: Records the LLM-based Agent's trajectory as a dialogue history of recent conversations or actions. Short-term memory refers to information within the current prompt, while long-term memory involves externally stored data accessible via fast vector retrieval.
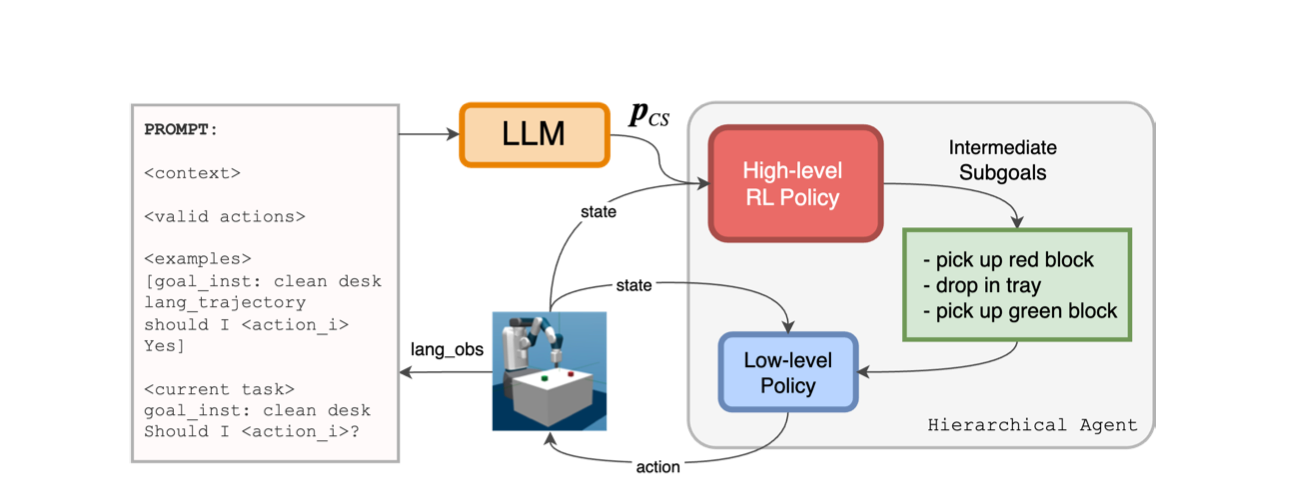
In practice, when developing an agent using a model like GPT-4, instructions and the agent's roles are encoded within the prompt. This includes APIs available for use, output format, etc. For instance, AutoGPT utilizes recursive self-calling, where the output is appended in each iteration. The ReAct framework is a popular framework in this context.
In summary, through prompt engineering, AI agents based on LLMs can be endowed with abilities to plan, execute, reason, and self-reflect autonomously. The design of the prompt is crucial, as LLMs are sensitive to prompts. A well-crafted prompt should clearly outline the agent's role, the task at hand, the command set, the output format ect.
This post is for subscribers only
Sign up now to read the post and get access to the full library of posts for subscribers only.