Multimodal Large Language Models (MLLMs) are garnering significant attention. There has been a plethora of work in recent months dedicated to the development of MLLMs [Flamingo, NExT-GPT, Gemini...].
The key challenge for MLLMs lies in effectively injecting multimodal-data in LLMs. Most research begins with pre-trained LLMs and employs modality-specific encoders
Multimodal Large Language Models (MLLMs) are garnering significant attention. There has been a plethora of work in recent months dedicated to the development of MLLMs [Flamingo, NExT-GPT, Gemini...].
The key challenge for MLLMs lies in effectively injecting multimodal-data in LLMs. Most research begins with pre-trained LLMs and employs modality-specific encoders (eg. CLIP) to extract modality embeddings. These features are then mapped to the language embedding space using a learnable network. Consequently, the LLM condition itself on the multimodal embeddings interleaved with standard embedded text tokens. Another approach involves resampling multimodal inputs into a fixed number of discrete tokens, using vector quantizers (e.g. VQVAE), enabling LLMs to generate non-textual data (because multimodal tokens become part of the LLM vocabulary).
In this post, we will explore how MLLMs are developed. We will go through various architectures, training regimes, and approaches for handling multimodal inputs, including audio, video, and text.
Modality Adaptation
LLMs play tokens in a cascade of transformer layers. However, tokens must first be represented in a vector space. Given a vocabulary \(V\) and a word embedding space \(W \subset \mathbb{R}^e\), a LLM initially maps a token to the language embedding space using a mapping \(\phi:V \rightarrow W\).
Each sequence is represented as a set of tokens, which are then transferred to the embedding space, using the aforementioned mapping. Using the implicitly acquired knowledge, it can predict the subsequent token, i.e., \(p(w_n|w_{1:n−1})\).
To integrate multimodal data within the LLM, one can follow different approaches.
One approach is direct mapping, employing modality-specific encoders and an additional projection module to transfer multimodal feaures to a vector space with the same dimensions as the language embedding space, bypassing the discrete token level. The projections are then interleaved with standard embedded text tokens to form a prefix for the LLM.
Another approach expands the base vocabulary with discrete tokens covering the modality feature space, obtained using modality-specific quantizers. Essentially, each raw multimodal data piece is compressed into a sequence of discrete tokens that the LLM can use. Coupling a language model with discrete non-textual tokenization equips the LLM with the capability to perceive and generate non-textual modalities. The generation problem becomes a discrete token prediction task without affecting performance in standard textual tasks.
Multimodal LLMs often use pretrained decoders that leverage contextualized representations of special modality tokens, projected into a decoder embedding space designed for generating outputs like audio, etc.
BERT has made significant advancements and is now widely used as a robust framework for contextualized representations.
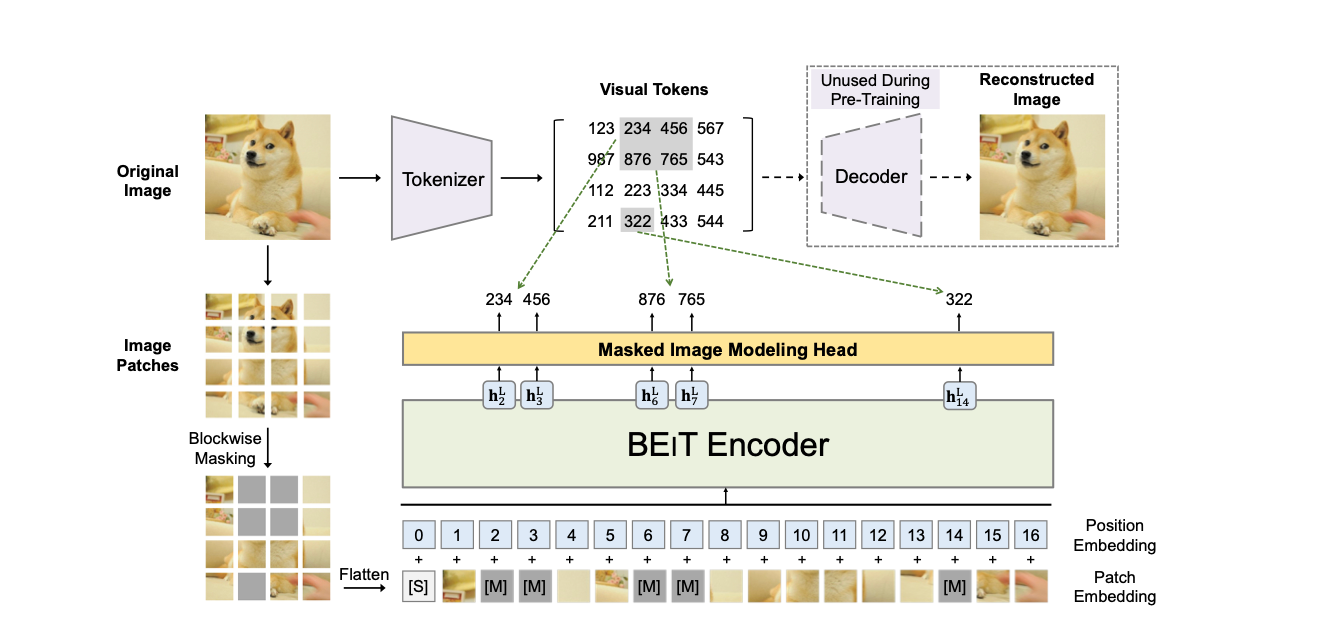
BEiT, inspired by BERT's approach, applies similar pre-training techniques to image data. Prior to BEiT, transformers for vision models existed but required extensive amount of data for training.
The paper introduces Masked Image Modeling (MIM), which is similar to Masked Language Modeling (MLM). Each image is divided into a grid of patches, serving as the input for the Transformer backbone. A discrete Variational Autoencoder (dVAE) is employed to generate visual discrete tokens. During training, a portion of the image patches is masked, and the model is trained to reconstruct the original image's visual tokens, as illustrated below:
More specifically, each image patch is projected into a patch embedding, similar to the concept of word embeddings in language models. An image tokenizer, utilizing a dVAE, creates a vocabulary of visual tokens. The model also incorporates standard learnable 1D position embeddings. Embeddings then pass through a cascade of Transformer layers, with the output vectors of the final layer serving as encoded representations for each image patch. Finally, a softmax layer is added, utilizing the contextualized representations to predict the visual tokens corresponding to each masked position.
This post is for subscribers only
Sign up now to read the post and get access to the full library of posts for subscribers only.