Scaling up the size of models leads to a considerable augmentation in computational expenses, both during training and inference phases. In a bid to harness the benefits of parameter scaling without an equivalent surge in computational requirements, the Mixture of Experts (MoE) approach was developed for expansive language models. Within
Scaling up the size of models leads to a considerable augmentation in computational expenses, both during training and inference phases. In a bid to harness the benefits of parameter scaling without an equivalent surge in computational requirements, the Mixture of Experts (MoE) approach was developed for expansive language models. Within these models, individual layers are introduced, often comprise several sub-networks, termed as experts. Notably, during the inference stage, only a subset of these experts is activated (conditional computation) depending on the input.
MoE offers a streamlined strategy to mitigate the costs associated with training large-scale models. It introduces merely sub-linear computational costs relative to the model’s size by selectively activating a fraction of the model parameters based on the given inputs.
As a case in point, the computational overhead for training the Switch Transformer, boasting 1.6T parameters, is less than the resources demanded for a densely-configured model encompassing billion parameters.
Pre-reading Requirements
This article assumes that readers have a basic understanding of Machine Learning and Deep Learning. I have aimed to stay as high-level as possible so that those who are not necessarily technical can still grasp the concepts.
Summary:
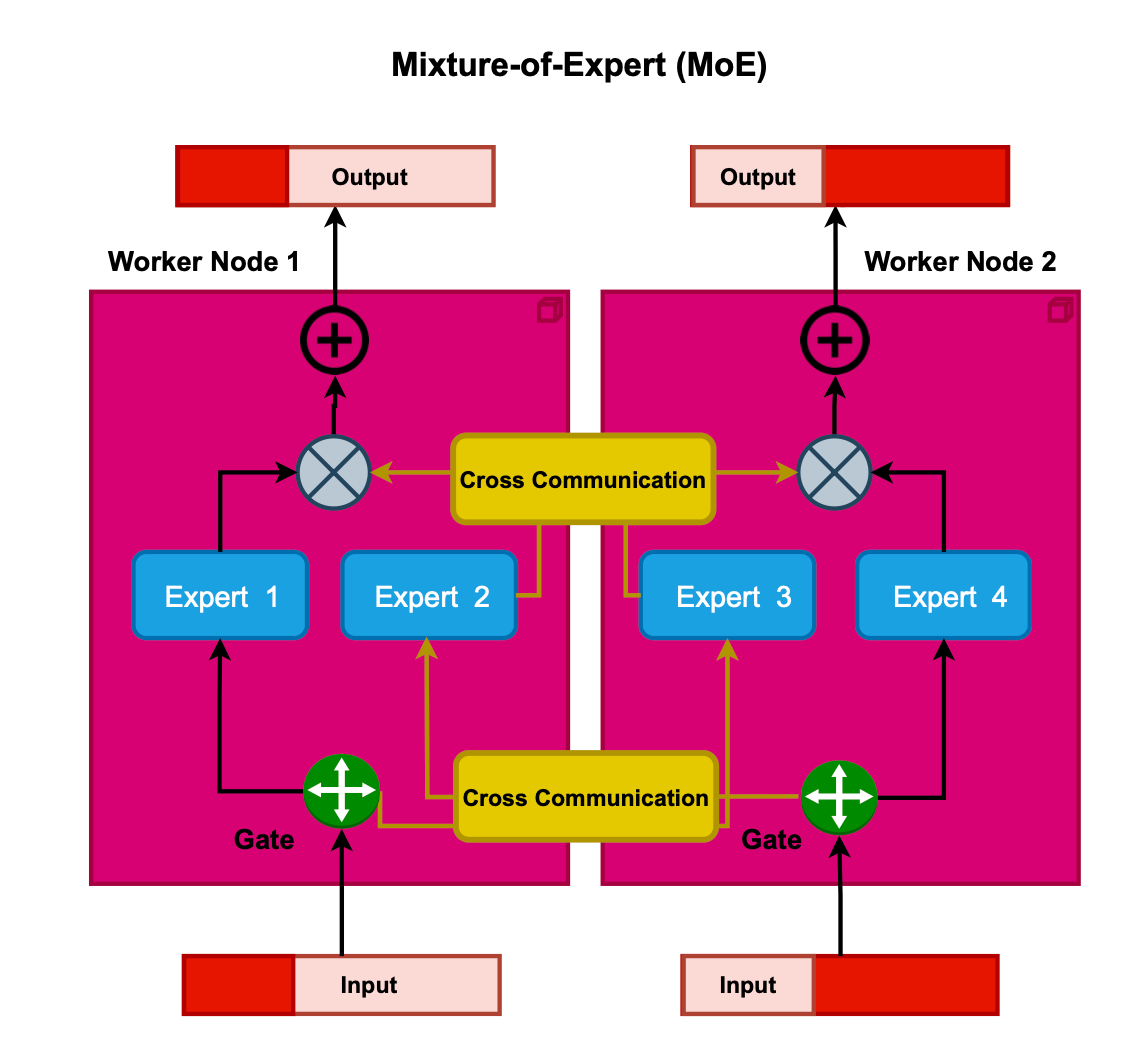
The Mixture of Experts (MoE) model addresses the challenge of processing complex data distributions that a single deep neural network might struggle with. The strategy is based on a divide-and-conquer approach, utilizing multiple subnetworks known as experts and integrating their outputs. The determination of each expert's contribution is managed by a gating network, which might employ a weighted average of the experts' outputs or select the top-performing ones. This leads to the concept of conditional training and inference, wherein the model becomes sparse, activating only a subset of parameters as needed per input.
Finally, MoE is instrumental in Lifelong Language Pretraining. This is critical in circumventing the need to retrain the model on all available data with each newly available distribution subset, thereby avoiding the catastrophic forgetting problem.
MoE - Mixture of Experts
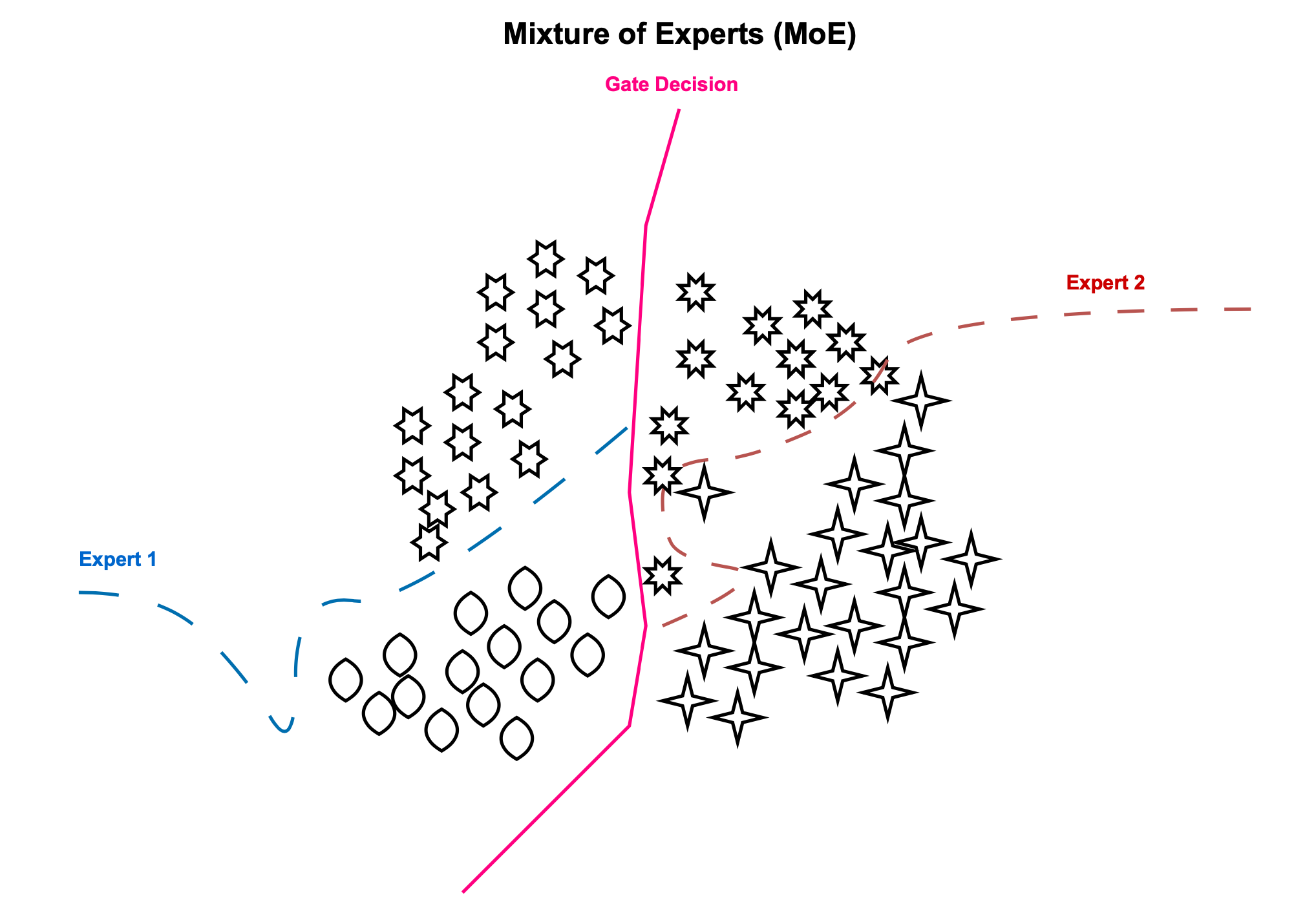
Machine learning often grapples with intricate input spaces, especially when such spaces encompass multiple subdomains or subspaces. A single neural network, regardless of its depth, might struggle to capture the distribution across the entire data space due to overlapping and intricate patterns. More specifically, in a classification scenario, the decision boundary that separates data from different classes can be exceedingly complex. By segmenting the feature space and using multiple classifiers, each can learn its own nonlinear decision boundary. The overarching complex decision boundary can then be approximated through an appropriate combination of these subnetworks outputs .
The Mixture of Experts (MoE) technique aims to partition a nonlinear, complex problem space into more manageable subspaces that specific experts can address. This paradigm, introduced in 1991 by Jacobs et al, embodies the divide and conquer principle. Here, the problem or feature space is segmented amongst various experts. Each expert, as suggested by its name, concentrates on a distinct subspace. The selection of these (not necessarly orthogonal) experts is guided by an overseeing gating network. Both the expert sub-networks and the gating mechanism undergo training. The gating network adapts to route or allocate weights to specific experts, who in turn learn and specialize in certain subproblems. The expert selection strategy can vary; one can opt for hard selection (routing to one or the top-k experts) or soft selection (taking a weighted average of the experts). The differentiation of expert selection is crucial for effective backpropagation.
As said, MoE isn’t novel. Initially delved into by Jacobs et al. in 1991, they explored diverse error definitions for training a composite DNN structure, encompassing both experts and gating. Over time, the employment of MoE demonstrated that considering a data distribution through an experts-gating mechanism yielded impressive performance, outscaling dense models. In comparison to conventional Transformer models, where the FLOP count per batch scales linearly with parameter count, MoE architectures demand significantly fewer computations, enabling the efficient training of larger models.
With time, various training forms, error definitions, and strategies emerged to enhance MoE’s performance and the segmentation of the input space. For instance, while the original MoE approach stochastically partitioned the feature space, alternative methods like pre- training clustering offered a more deterministic route.
To train a massive language model leveraging the MoE design, expert parallelism is often employed to minimize the memory footprint by distributing different experts across multiple devices. These experts are disseminated over an array of workers. A gating network dictates the destination device for each token, precipitating an all-to-all communication. If tokens are routed to experts on different devices, an all-to-all communication process dispatches the token to the appropriate devices. Once processed by the expert, another all-to-all communication returns the token.
In summary, MoE divides a data space into numerous subspaces, with each expert dedicated to a specific subspace of data distribution. The gating network, trained in conjunction with the experts, discerns which expert excels for each training instance, and subsequently, assigns data subspaces to the appropriate experts.
MoE and Sparsity
Beyond mere performance capabilities, sparse MoE models present a significant advantage. Not every sample necessitates the use of all model parameters. Consequently, through the incorporation of experts, one can drastically expand the model’s size without a proportional increase in computational requirements. This trait is pivotal for scaling up large language models.
As highlighted previously, bolstering the computational budget, training data, and model dimensions tends to enhance model efficacy. Sparse expert models have emerged as a potent solution, aligning with some of the strategic directions pursued by Google.
The probability vector of the gating network can manifest sparsity, meaning only one or a select group of experts are activated, while others remain dormant. In contrast, a dense probability vector, such as one derived from softmax, ensures all experts are assigned non-zero probabilities.
An example of a sparse gating network is the Top-k gate (often termed "sparse softmax"), where typically only 1 or 2 experts are activated, and the remainder are disregarded. This sparsity facilitates reduced computational overhead both during training and inference.
The Top-k gate is characterized by the function $$\text{softmax}(\text{TopK}(Wx + b))$$ where for any given vector v: $$\text{TopK}(v)_i := \begin{cases} v_i & \text{if } v_i \text{ ranks among the top-}k \text{ elements of } v \\ -\infty & \text{otherwise (the softmax then goes to 0)} \end{cases}$$
The Top-k gate is conducive to conditional training (and inference). During backpropagation, for every input sample, only the gradients of the loss with respect to the top k elements are computed. To promote load balancing and stabilize training, noise is occasionally added prior to selecting the top-k values, fostering smoother routing.
When executed meticulously, conditional training can result in computational efficiencies. Nonetheless, the Top-k gate's discontinuity signifies that its gradient is undefined at certain input values.
This post is for paying subscribers only
Sign up now and upgrade your account to read the post and get access to the full library of posts for paying subscribers only.