Writing performant, portable, and correct parallel programs in multiprocessor systems or SMP, where each processor may load and store to a single shared address space, is not trivial. Programmers must be aware of the underlying memory semantics, i.e. the system optimizations performed by the clever beast hardware or cpu.

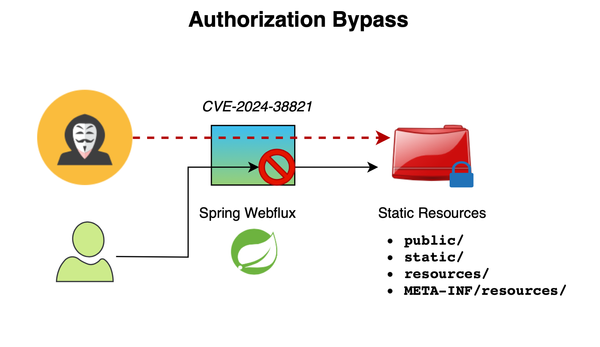
Spring announced on October 25, 2024, CVE-2024-38821, a critical vulnerability allowing attackers to access restricted resources under certain circumstances. The vulnerability specifically impacts Spring WebFlux's static resource serving. For it to affect an application, all of the following must be true: It must be a WebFlux application. It
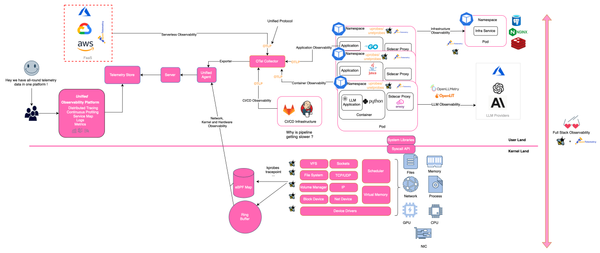
Observability represents the ability to measure how well the internal state of a system can be inferred solely by its external outputs. Observability and the challenges associated with it is by no means a new problem and have existed for decades. Observability is a necessary precursor to ensure the reliability
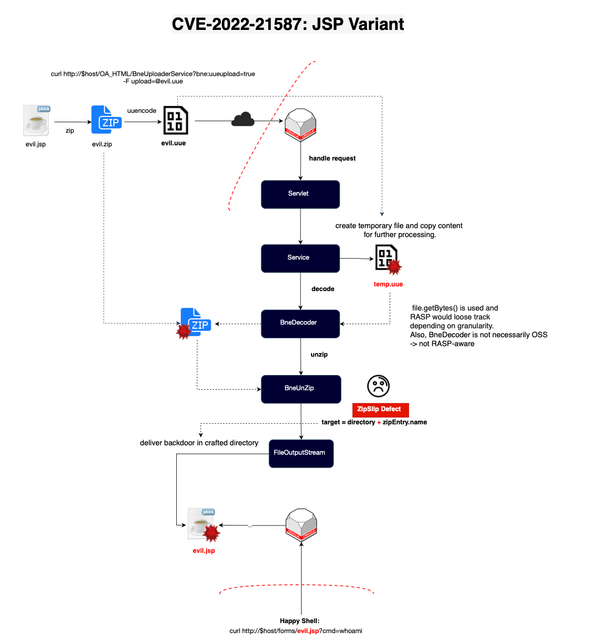
Last week, I saw this post (https://www.theregister.com/2024/07/12/cisa_broke_into_fed_agency/) discussing the exploitation of an unpatched Oracle vulnerability. The unnamed federal agency took over two weeks to apply the available patch 😜. When I read the post, I was like: Is RASP or
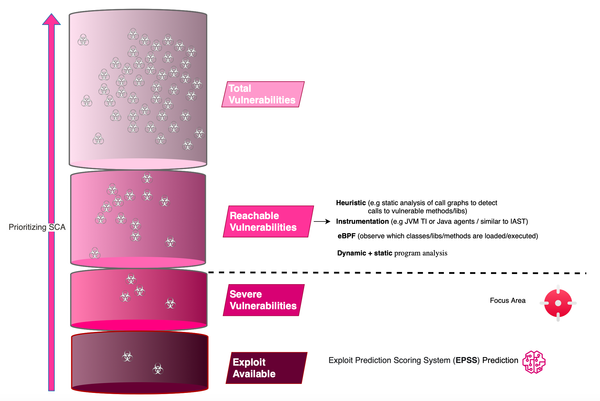
Vulnerabilities are everywhere and here to stay. Defects can exist in source code or third-party and open-source software. However, not all vulnerabilities pose the same threat, and code that is exploitable in one context may not be exploitable in another. Focusing on what matters is crucial for remediation and prioritization,
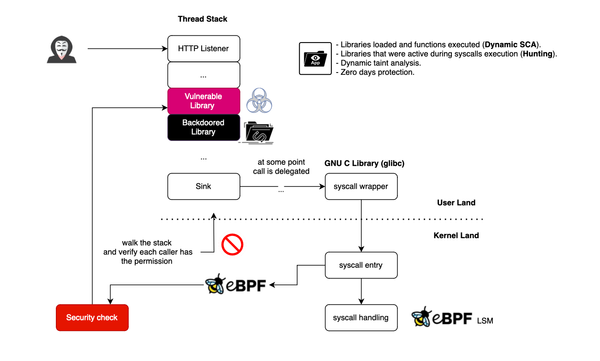
In this blog post, I will discuss how one can use eBPF for runtime application security to detect library profile deviations. More specifically we will use stack traces to observe what libraries/functions are active in the stack when a system call is issued. Stack traces are very valuable signals
In this post, we will explore why RASP, or Runtime Application Self-Protection, is not always effective in protecting your Java applications and can be bypassed. Introduction Open source security has long been problematic, yet many organizations continue to overlook its importance. Existing sandboxing solutions such as seccomp and LSMs (SELinux,
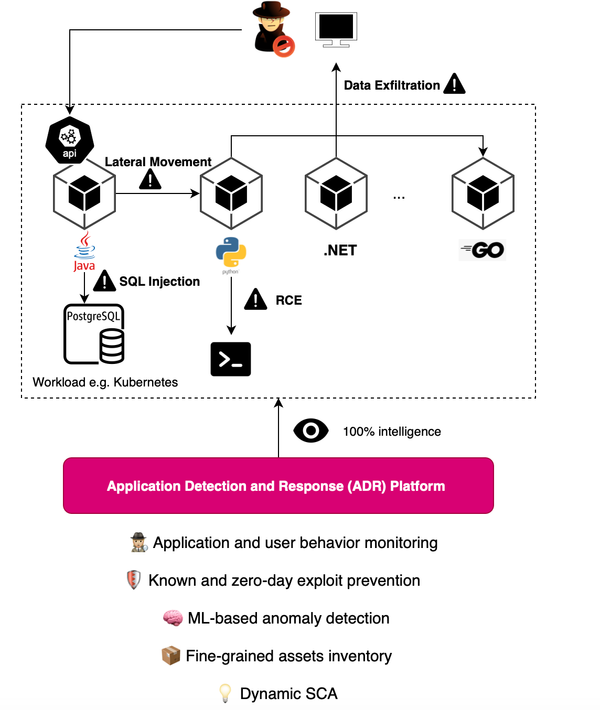
Few companies are starting to pave the way for Application and Detection Response (ADR) including Oligo Security, RevealSecurity and Miggo Security. You may find yourself quickly lost in understanding what these solutions aim to tackle. First, each of these solutions likely focuses on what they do best. For example, Oligo

Cybercrime is growing at a dizzying pace and projected to inflict $9.5 trillion USD global cost in 2024. Java-based applications, often targeted by hackers due to their known and zero-day vulnerabilities, are at high risk. The increased reliance of many Java applications on open source frameworks such as Spring