Parameter-Efficient Fine-Tuning (PEFT), LoRA and Quantization
Transformer-based deep learning models, such as GPT-3 and LLaMA, have achieved state-of-the-art results on many NLP tasks. These models have exhibited outstanding performance and are capable of resolving tasks on the fly through in-context-learning (ICL) without the need for retraining. This approach helps
Transformer-based deep learning models, such as GPT-3 and LLaMA, have achieved state-of-the-art results on many NLP tasks. These models have exhibited outstanding performance and are capable of resolving tasks on the fly through in-context-learning (ICL) without the need for retraining. This approach helps to avoid the well-known catastrophic forgetting problem. However, ICL can sometimes be sensitive and occasionally suboptimal. Discrete prompts (tokens in the vocabularies) are often more intuitive for humans than for the model. That's why, at times, one might need to resort to fine-tuning to update the trained policy or distribution to better comprehend target tasks.
Naive or full parameter fine-tuning requires retraining all the parameters, which can make your model susceptible to catastrophic forgetting. Additionally, large language models (LLMs) are expansive in size, which can pose challenges if you're limited by memory or simply can't afford to retrain the entire configuration, not to mention the concerns related to storage and sharing.
This is where Parameter Efficient Fine Tuning (PEFT) comes into play. PEFT involves freezing certain parts of your model while training specific sections or adding additional heads to update the model's policy. In this scenario, there's no need to store a complete set of model weights for each task; instead, you only need to store the smaller, trained model parameters, which conserves storage space. Moreover, the training process is accelerated, and the associated costs are reduced. Parameter-efficient fine-tuning methods for Transformer-based language models include prefix tuning, adapter tuning, prompt tuning, and LoRA.
Pre-reading Requirements
I assume readers have at least a basic background in Machine Learning (understanding concepts such as probability, embedding space, training vs. testing, etc.).
Summary
Fully fine-tuning Large Language Models (LLMs) is nearly unfeasible because all parameters, amounting to billions, are involved in the tuning phase, which requires a substantial amount of time, memory, and consequently, money.
Typically and intuitively, only a small subset of weights would contribute to adapt to a task at hand. Parameter-efficient fine-tuning involves freezing certain parameters while only training a subset, or alternatively, introducing additional parameters.
Parameter-efficient fine-tuning techniques include Prefix Tuning, where learned latent vectors are appended to the frozen transformer blocks. These latent vectors represent task-specific knowledge to aid the model in better understanding the desired outcomes, serving as a replacement for prompt engineering.
Prompt tuning is akin to prefix tuning but operates solely on the input embedding layer, acting as virtual tokens.
Another method, Adapter Tuning, involves augmenting models with multiple trainable modules to adapt to specific tasks, while keeping the original model parameters unchanged.
Over the years, several parameter-efficient algorithms have been developed, including LoRA and its derivatives. Notably, the latest models combine these with quantization to reduce the costs associated with training, storage, and inference.
Adjusting the model while maintaining its parameters
BitFit introduced a sparse-finetuning method where only the bias terms, or a subset of them, within the model are updated. As a result, the number of trainable parameters remains minimal. By optimizing only the bias terms and freezing all other parameters, BitFit demonstrated competitive results, achieving strong performance across several benchmarks. However, as one might guess, since only the biases are trained, the learning capability can be limited, especially when faced with significant distribution shifts.
Lee et al investigated the training of the final layers and found that this approach yielded lower performance compared to fine-tuning all parameters. Additionally, they concluded that fine-tuning every layer isn't always beneficial.
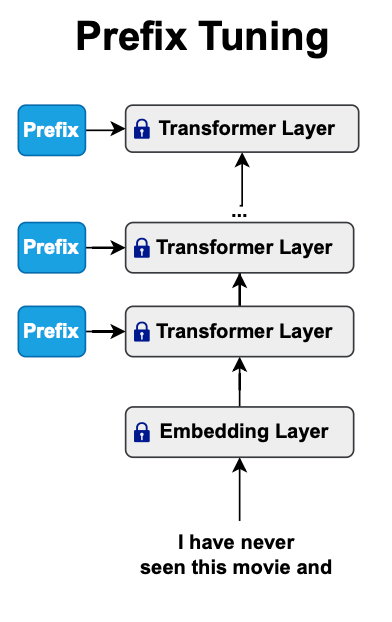
Prefix Tuning
Prefix tuning prepends task-specific trainable continuous tokens or prefixes to each Transformer layer. It essentially introduces virtual word embeddings. A MLP structure is usually added in front of the prefix layer to stabilize the training.
Prefix tuning was inspired by the prompt methodology; the primary difference is that there's no need to add the prefix explicitly. Instead, the model learns how to prepend it to all the Transformer layers (task specific). Additionally, you're not limited to using the model's vocabulary to express your target tasks.
A significant advantage is that these task-specific prefixes are inexpensive in terms of storage. They serve as an alternative to prompt engineering, which can be more effective. Rather than spending hours optimizing a prompt, you let the model learn and then fetch and append the prefixes to the model during inference. However, you lose the interpretability of discrete or hard prompts.
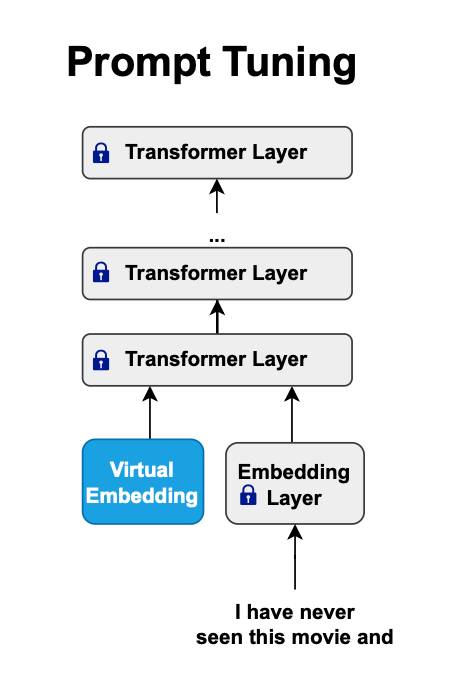
Prompt Tuning
Prompt tuning is similar to prefix tuning. Instead of prepending each Transformer layer, it primarily integrates a soft, trainable prompt or embeddings at the input layer to guide a static language model towards a specific downstream task. Rather than crafting prompts by hand, they're made adaptable through backpropagation.
In prompt tuning, virtual tokens are introduced and embedded using a new table, then prefixed to the input. The model runs a forward pass with this sequence, calculates the loss, and, after a backward pass, updates only the new embedding table, keeping the main model static.
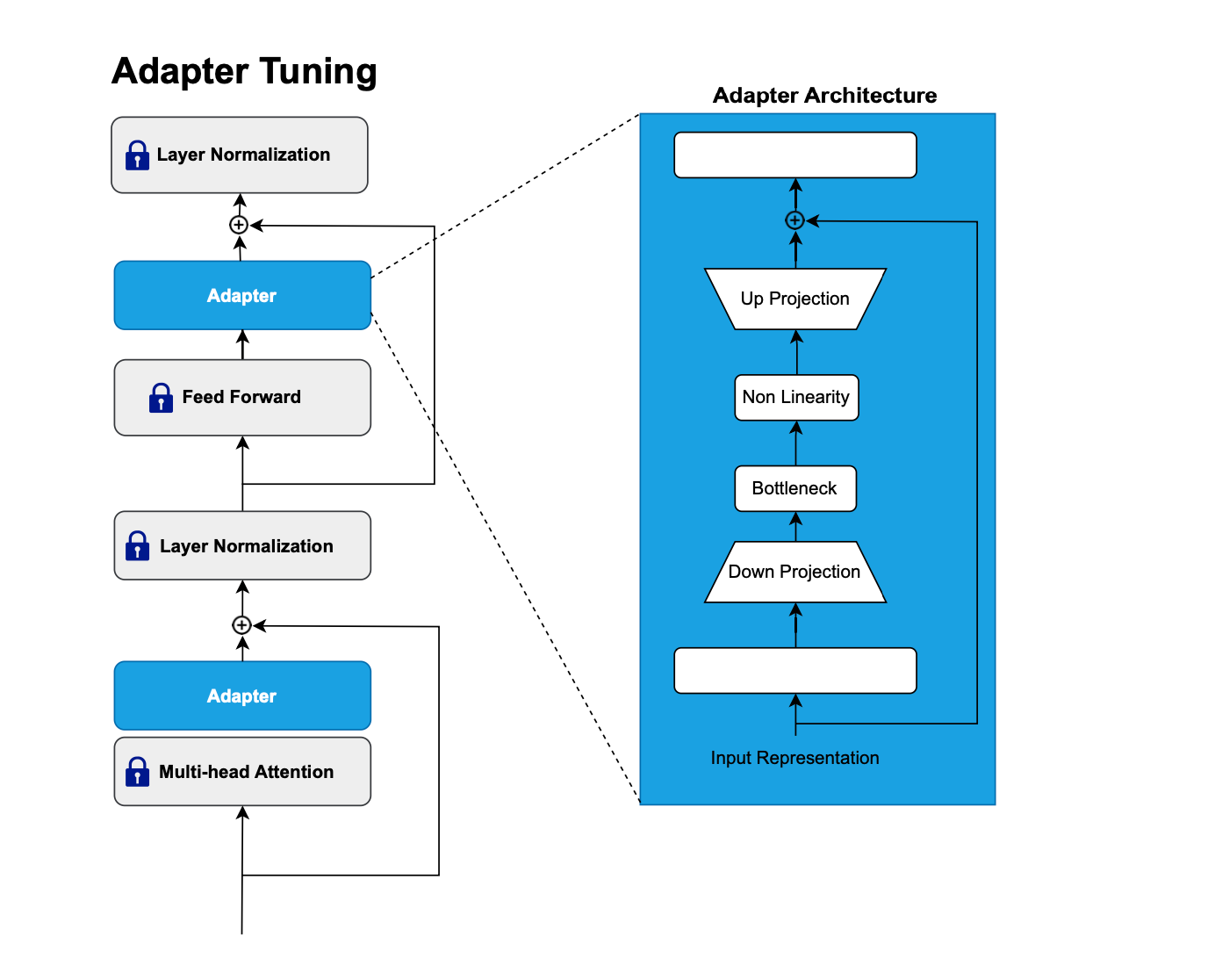
Adapter Tuning
Adapters, as the name suggests, augment models to adapt to specific tasks by adding multiple trainable modules, while the original configurations or parameters remain frozen.
Adapters are typically MLP structures scattered throughout the model and are usually inserted between the layers of transformers (after the projection of the multi-head attention and the feed-forward layer).
Adapters often employ a bottleneck architecture, which initially projects the original feature vector into a smaller dimension, undergoes a nonlinear transformation, and then restores it to the original dimension.
Several variants have been proposed recently. It has been observed that as the number of adapter layers increases, the performance improves. However, introducing new layers also means a slower inference time and an increase in the model's size.
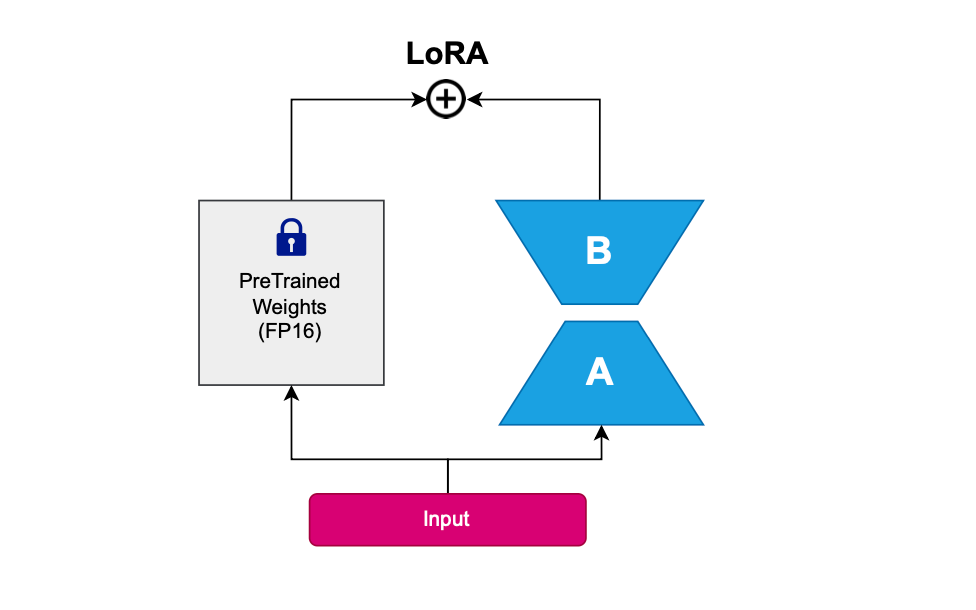
LoRA (Low-Rank Adaptation of Large Language Models)
One of the primary disadvantages of full fine-tuning LLMs is their huge number of parameters, especially within the attention blocks. It becomes infeasible and impractical to update all these weights, as the process is time-consuming. Computing the gradient for each parameter during training takes considerable time. Research has shown that even with full fine-tuning, the significant impacts occur only within a low dimension subspace of the parameter space. Intuitively, it seems unnecessary to utilize all the parameters to achieve desired performance levels.
The core idea of Low Rank Adaptation (LoRA) is that the change in weights during model fine-tuning occupies a low intrinsic dimension. It decomposes attention weight updates into low-rank matrices, thereby reducing the number of trainable parameters.
This post is for subscribers only
Sign up now to read the post and get access to the full library of posts for subscribers only.