Generative Pre-trained Transformers (GPT) have cast a bright spotlight on the field of AI, especially ChatGPT. Companies are now recognizing AI as a potent tool, not only GPT and its variants but AI in general. However, GPT was not born by accident. When you delve into its story, the


Generative Pre-trained Transformers (GPT) have cast a bright spotlight on the field of AI, especially ChatGPT. Companies are now recognizing AI as a potent tool, not only GPT and its variants but AI in general.
However, GPT was not born by accident. When you delve into its story, the subject becomes even more fascinating. Even those who knew nothing about AI or Deep Learning just six months ago might become intrigued enough to learn more or possibly even change their career path.
NLP, in short for Natural Language Processing, consists of helping computers understand and process human language. This includes tasks like text generation, summarization, and more, opening many doors for human-machine interaction. However, the natural language space is filled with challenges, such as words having different meanings depending on the context, or different words meaning the same thing.
Machine learning mainly consists of tensor operations and optimization. If your data does not reside in a vector space, there isn’t much you can do. With images, this process is relatively easy, as tensors or matrices already represent the data. Text, however, gets more complicated as each sentence or word must be converted to a vector before mathematical operations can occur.
An easy way to vectorize text is one-hot encoding, mapping each vocabulary word to the canonical basis where only one element is 1, and the others are 0. But this approach proved infeasible, as it assumes all words are orthogonal, which is false.
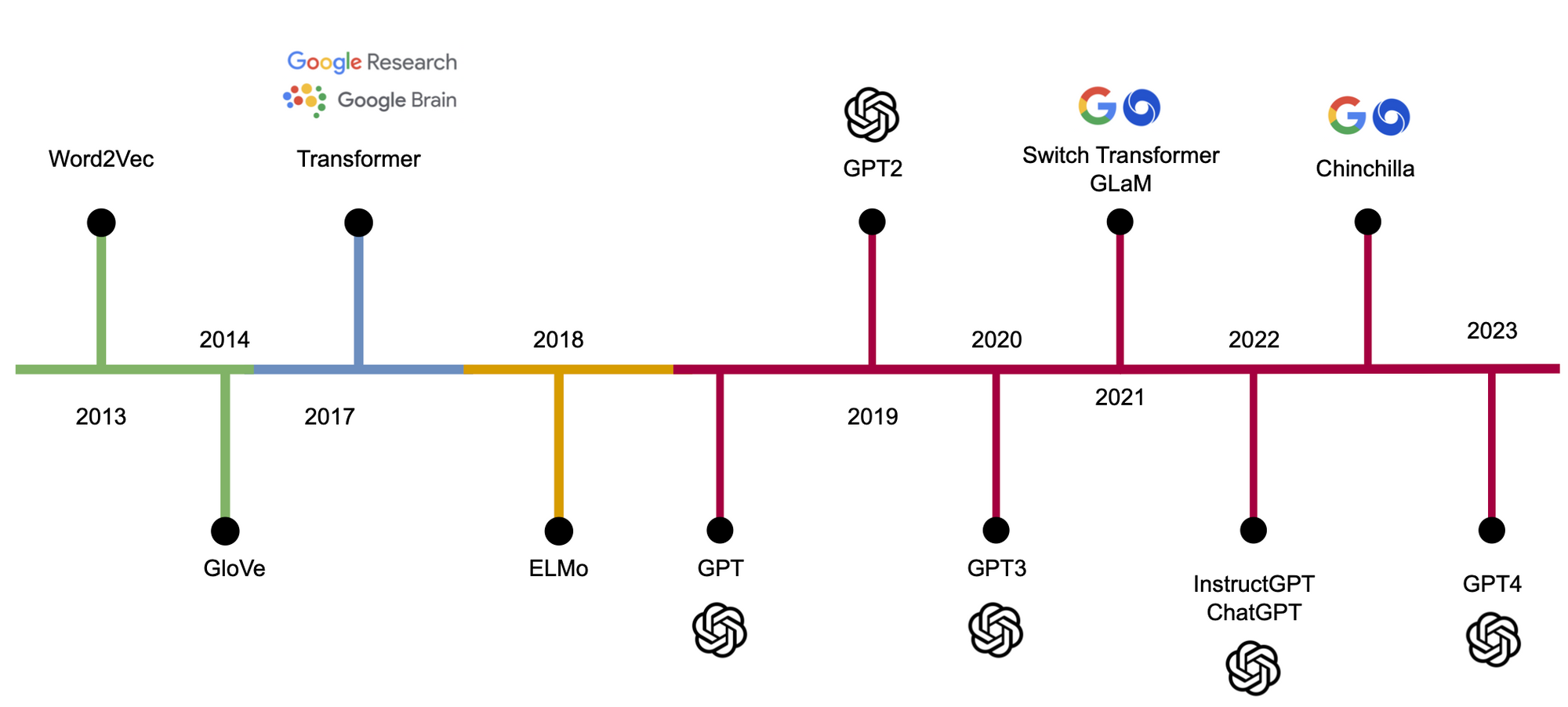
This led to the introduction of the Neural Network Language Model (NNLM), mapping one-hot encoded vectors to an embedding space and effectively reducing the dimension of the feature space. Word2Vec is one such popular model. Over the years, others like GloVe and FastText were also proposed.
Soon after these models were introduced, limitations became apparent. While they mapped similar words close together, the mapping was static and didn’t take context into account. Models like ELMO were then introduced, utilizing architectures like RNN or LSTM for contextual embeddings.
However, RNN-based architectures suffered from the gradient vanishing or exploding problem, hindering learning long-term dependencies. Although LSTM partially solved the issue, there was still room for improvement.
RNN and LSTM made significant assumptions, and stabilization tricks were insufficient for larger and complex datasets. The transformer model was introduced in the famous paper Attention is All You Need. Using the attention mechanism, it enabled the model to see previous projections and select the best ones, changing the landscape of NLP.
Many models were derived from the Transformer model, including GPT, which slightly altered the original transformer’s decoder architecture for language modeling.
Over the years, GPT underwent several enhancements, including iterations like GPT-1, GPT-2 and GPT-3. However, the generated text lacked controllable elements and didn’t always align with user intentions.
InstructGPT and ChatGPT were born from the need to better understand user intent. These models used reinforcement learning to hone their responses.
Note that I didn’t delve into exhaustive details, as more can be found in my eBook AI through Cybersecurity Glasses.
GPTs are fantastic, but resource-hungry. ChatGPT and other variants have their own issues, including potential security risks. Ongoing research is focused on democratizing these models to use less memory, be less GPU intensive, handle larger context, use effectively datasets and make models more responsible.
As the field continues to grow, the opportunities for innovation and improvement are endless, promising a fascinating future for those interested in AI.